






May 30, 2017
Eryn Muetzel
D2iQ

5 min read
The most valuable applications to today's businesses are all data-driven. These applications must serve customers in real-time, and are powered by millions of endpoints and massive quantities of data.
But how does a company set up and operate the required infrastructure and application services, design and build the application, and then scale it to millions of users? Modern enterprise applications are shifting from monolithic architectures to distributed systems composed of microservices deployed in containers, and platform services such as message queues, distributed databases, and analytics engines.
However, building and maintaining infrastructure and data services for these modern distributed applications is complex and time-consuming. But just why is building and maintaining data infrastructure so taxing?
1. Deploying each data service is time consuming
First, deploying each data service is time consuming. Installing a production-grade platform service such as Kafka or Cassandra requires specialized knowledge for operators; even for an expert, deployment is time consuming and often requires significant engineering effort. For example, when the engineering team at AirBnB first attempted to deploy Kafka, it took multiple months, and ultimately ran into many issues. Additionally, if fast data services are not architected correctly, the result is snowflake implementations that are dependent on key personnel to maintain.
In the past five to ten years, an explosion of datastores and analytics engines have emerged, many open source. Beyond the significant cost of resources to deploy each new data service, a primary downside of deployment challenges is that developers and data engineers cannot easily experiment with these new technologies.
Explosion of Datastores and Analytics Engines
2. Operating data services is manual and error-prone
The second major challenge with implementing fast data technologies is the ongoing operations of these technologies; common tasks such as upgrading software, deploying updates, rolling back after failures, monitoring health, and managing storage resources are often manual and error-prone. This time-consuming ongoing maintenance requires additional headcount and can be a drag on new innovation.
Applications teams and operators need the latest capabilities in data services in order to fix critical bugs, add valuable features, and reduce operational overhead. Software upgrades and updates are time consuming because operators and developers manually upgrade the services or are required to build configuration management and orchestration software to automate the upgrade. In addition, updates and rollback need to be thoroughly validated on a testing environment before they are ready for production.
3. Infrastructure silos with low utilization
The third key challenge with operating fast data infrastructure is maintaining enough infrastructure to handle data-processing peaks in a cost-effective way. Average datacenter utilization is approximately 6-12% and remained static from 2006-2012, driven by companies' desire to maintain high service quality through peak load periods.
Traditional Approach: Silos with Low Utilization
The increased utilization benefit of virtual machines does not apply to distributed systems. Operators typically create separate clusters for Spark, Kafka, Cassandra, and so on. This is because these services are distributed systems with their own scheduling logic to grow and shrink their footprint, so operators run them in different clusters to avoid resource conflicts. For example, the Spark data processing service may want all the capacity it can get to finish a job, the Kafka message queue may need resourcing based on the volume of data passing through, while the Cassandra distributed database may need steady resourcing to persist data. The result is extremely low utilization, and waste of infrastructure resources.
Rather than running workloads in silos based on the application, datacenter-wide resource sharing drives increased utilization as all workloads can access a shared pool of resources.
Public Cloud - The Solution?
Many companies are shifting fast data workloads to the cloud or hybrid environments. The two key reasons for moving to the cloud are:
- To get immediate access to platform services such as analytics tools and databases. Cloud providers such as Amazon Web Services and Microsoft Azure package data services and make them easy to install and operate.
- To enable scalability and elasticity, an imperative for bursting fast data workloads.
In a recent survey, less than a third of companies hosted their data pipeline on-premises, while more than two thirds hosted in the cloud or hybrid environments.
While public cloud provides clear advantages for fast data workloads, the major downside is the risk of lock-in. Applications that are developed using public cloud platforms are tied to a specific cloud provider's APIs, and moving workloads after the fact is near impossible without rewriting them. One recent story highlights the risk of cloud lock-in, that of Snap (of Snapchat). In the S1 Registration Statement issued by Snap in February 2017, it came to light that Snap had handcuffed itself to Google Cloud. Of the annual loss of over $500 million, 80% was attributed to contractually obligated spend with Google. In the same filing, Snap states that they wrote their application to use some Google services "which do not have an alternative in the market." Google now has them in handcuffs, and there is little Snap can do to change that without having to invest a tremendous amount of money to free themselves.
As companies continue to rush to the cloud to quickly build new services, the costly risk of lock-in continues to mount. But what is the alternative?
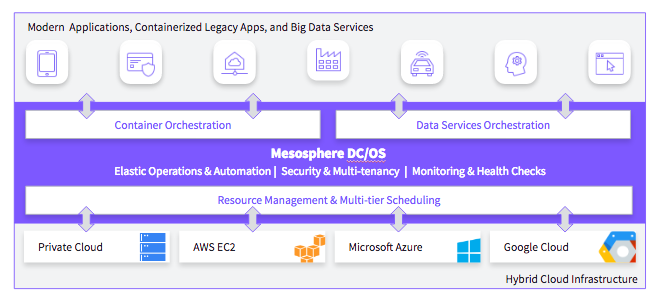
Mesosphere DC/OS: Simplifying the Development and Operations of Fast Data Applications
Mesosphere is focused on making it insanely easy to build and elastically scale data-rich, modern applications. Mesosphere DC/OS is the only production-proven platform that runs both containers and data services on the same infrastructure. DC/OS accelerates deployment and simplifies operations for a broad set of data services including databases, message queues, analytics engines, and more.
The core of DC/OS is the Apache Mesos™ distributed systems kernel. Its power comes from the two-level scheduling that enables distributed systems to be pooled and share datacenter resources. Two-level scheduling in DC/OS provides key differentiators versus simply running services in containers on Kubernetes or Docker Swarm, and simplifies the three key challenges with operating data services—deploying services, operating them, and overcoming silos with low utilization.
- On-demand provisioning: DC/OS enables single-command install of data services such as Spark, Cassandra, Kafka and Elasticsearch, among many others. DC/OS also dramatically simplifies resizing instances of a data service, as well as adding more instances. With Mesosphere DC/OS, operators can easily scale up and scale out data services, with no downtime.
- Simplified operations: DC/OS dramatically reduces the time and effort involved with operating data services through simple runtime software upgrades and updates, application-level monitoring and metrics and managed persistent storage volumes.
- Elastic data infrastructure: DC/OS enables multiple data services, containerized applications and traditional applications to all run on the same infrastructure, dramatically increasing utilization. Some Mesos and DC/OS users have approached average utilization rates of over 90%, and reduced hardware and cloud costs by over 60%.
Mesosphere DC/OS: The Premier Platform for Deploying Data-Rich Apps
Sources:
• "The Sorry State of Server Utilization and the Impending Post Hypervisor Era", Gigaom, November 2013
• NRDC Data Center Efficiency Assessment, August 2014
• State of Fast Data and Streaming Applications, OpsClarity, 2016
• Snap S1 Registration, February 2017
• "The Sorry State of Server Utilization and the Impending Post Hypervisor Era", Gigaom, November 2013
• NRDC Data Center Efficiency Assessment, August 2014
• State of Fast Data and Streaming Applications, OpsClarity, 2016
• Snap S1 Registration, February 2017
Want to learn more?
This content is an excerpt from our free eBook, "Architecting for Fast Data Applications." This book details the infrastructure requirements to build fast data applications, the challenges that arise, and the key technologies and tools required for success.


