






May 23, 2017
Eryn Muetzel
D2iQ

5 min read
Data is growing at a rate faster than ever before. Every day, 2.5 quintillion bytes of data are created–equivalent to more than 8 iPads per person. The average American household has 13 connected devices and enterprise data is growing by 40% annually. While the volume of data is massive, the benefits of this data will be lost if the information is not processed and acted on quickly enough.
One of the key drivers of the sheer increase in the volume of data is the growth of unstructured data, which now makes up approximately 80% of enterprise data. Structured data is information, usually text files, displayed in titled columns and rows which can easily be analyzed. Historically, structured data was the norm because of limited processing capability, inadequate memory and high costs of storage. In contrast, unstructured data has no identifiable internal structure; examples include emails, video, audio and social media. Unstructured data has skyrocketed due to the increased availability of storage and the number of complex data sources.
Challenges with Hadoop
The term "big data" was popularized in the early- to mid-2000s, when many companies started to focus on obtaining business insights from the vast amounts of data being generated. Hadoop was created in 2006 to handle the explosion of data from the web.
While most large enterprises have put forth efforts to build data warehouses, the challenge is in seeing real business impact—organizations leave the vast amount of unstructured data unused. Despite substantial hype and reported successes for early adopters, over half of the respondents to a Gartner survey reported no plans to invest in Hadoop as of 2015. The key big data adoption inhibitors include:
Skills gaps (57% of respondents): Large, distributed systems are complex, and most companies do not want to staff an entire team on a Hadoop distribution.
Unclear how to get value from Hadoop (49% of respondents): Most companies have heard they need Hadoop, but cannot always think of applications for it.
Beyond Hadoop: The Rise of Fast Data
Over the past two to three years, companies have started transitioning from big data, where analytics are processed after-the-fact in batch mode, to fast data, where data analysis is done in real-time to provide immediate insights. For example, in the past, retail stores such as Macy's analyzed historical purchases by store to determine which products to add to stores in the next year. In comparison, Amazon drives personalized recommendations based on hundreds of individual characteristics about you, including what products you viewed in the last five minutes.
Big data is collected from many sources in real-time, but is processed after collection in batches to provide information about the past. The benefits of data are lost if real-time streaming data is dumped into a database because of the inability to act on data as it is collected.
Modern applications need to respond to events happening now, to provide insights in real time. To do this they use fast data, which is processed as it is collected to provide real-time insights. Whereas big data provided insights into user segmentation and seasonal trending using descriptive (what happened) and predictive analytics (what will likely happen), fast data allows for real-time recommendations and alerting using prescriptive analytics (what should you do about it).
Big Data vs. Fast Data Examples
.tg {border-collapse:collapse;border-spacing:0;margin-bottom:25px;}.tg td{font-family:Arial, sans-serif;font-size:14px;padding:10px 5px;border-style:solid;border-width:1px;overflow:hidden;word-break:normal;}.tg th{font-family:Arial, sans-serif;font-size:14px;font-weight:normal;padding:10px 5px;border-style:solid;border-width:1px;overflow:hidden;word-break:normal;}.tg .tg-erlg{font-weight:bold;background-color:#efefef;vertical-align:top}.tg .tg-yzt1{background-color:#efefef;vertical-align:top}.tg .tg-7ojv{font-weight:bold;background-color:#ecf4ff;vertical-align:top}.tg .tg-9hbo{font-weight:bold;vertical-align:top}.tg .tg-yw4l{vertical-align:top}.tg .tg-c57o{background-color:#ecf4ff;vertical-align:top}
Vertical Big Data Fast Data
Automotive Automakers analyze large sets of crash and car-based sensor data to improve safety features Connected cars provide real-time traffic information and alerts for predictive maintenance
Healthcare Doctors provide care suggestions based on historical analysis of large datasets Doctors provide insightful care recommendations based on predictive models and in-the-moment patient data
Retail Stores determine which products to stock based on analysis of previous quarter's purchase data Online retailers provide personalized recommendations based on hundreds of individual characteristics, including products you viewed in last five minutes
Financial Services Credit card companies create models for credit risk based on demographic data Credit card companies alert customers of potential fraud in real-time
Automotive Automakers analyze large sets of crash and car-based sensor data to improve safety features Connected cars provide real-time traffic information and alerts for predictive maintenance
Healthcare Doctors provide care suggestions based on historical analysis of large datasets Doctors provide insightful care recommendations based on predictive models and in-the-moment patient data
Retail Stores determine which products to stock based on analysis of previous quarter's purchase data Online retailers provide personalized recommendations based on hundreds of individual characteristics, including products you viewed in last five minutes
Financial Services Credit card companies create models for credit risk based on demographic data Credit card companies alert customers of potential fraud in real-time
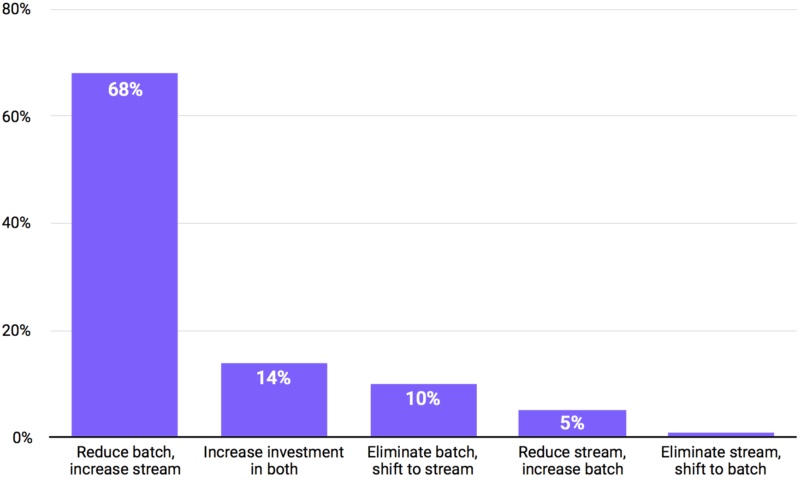
Businesses are realizing they can leverage multiple streams of real-time data to make in-the-moment decisions. But more importantly, fast data powers business critical applications, allowing companies to create new business opportunities and serve their customers in new ways. Over 92% of companies plan to increase their investment in streaming data in the next year, and those who don't face risk of disruption.
How Will Usage of Batch and Streaming Shift in Your Company in the Next One Year?
Source: 2016 State of Fast Data and Streaming Applications, OpsClarity
Mesosphere DC/OS: Simplifying the Development and Operations of Fast Data Applications
The shift from big data to fast data is clearly underway. But architecting, deploying, and scaling fast data applications and the related data services such as Spark, Cassandra, and Kafka, can be incredibly complicated.
Mesosphere is focused on making it insanely easy to build and elastically scale data-rich, modern applications. Mesosphere DC/OS is the only production-proven platform that runs both containers and data services on the same infrastructure. DC/OS accelerates deployment and simplifies operations for a broad set of data services including databases, message queues, analytics engines, and more. Mesosphere enables experimentation with new data services and provides a future-proof platform that is highly available and scales to meet the demands of users.
Sources:
• Vouchercloud Big Data Infographic
• Survey Analysis: Hadoop Adoption Drivers and Challenges, Gartner, May 2015
• State of Fast Data and Streaming Applications, OpsClarity, 2016
• Vouchercloud Big Data Infographic
• Survey Analysis: Hadoop Adoption Drivers and Challenges, Gartner, May 2015
• State of Fast Data and Streaming Applications, OpsClarity, 2016


