






Feb 14, 2020
Michael Beisiegel
D2iQ
10 min read
Akka based Cloud Native Applications
You can represent the state of thousands, if not millions of connected IOT devices, interrogate them, apply AI on the data they produce, and gain insight into how your world works. You can start small, and let your systems scale to the level you need to serve your customers and their data, and not worry about limitations of services, or data stores. KUDO simplifies development of Kubernetes operators, simplifies operations tasks, and speeds the time to value for stateful applications. Cloud Native applications are built as a composition of microservices that run in containers, which are orchestrated predominantly in Kubernetes. Each microservice runs as a collection of containers. As the processing load on a given microservice goes up and down, the Kubernetes container orchestration makes it easy to scale resources up or down. It will increase or decrease the number of running microservice container instances.
A typical pattern used is each microservice container runs independently, and each container instance is unaware of any other instances. As a result, concurrency is handled at the persistence layer, by the underlying databases used by the microservices. Some form of locking is used to handle concurrency, such as when two or more requests for the same data occur concurrently in multiple microservice container instances.
This processing pattern is commonly known as stateless microservices. Requests to a stateless microservice trigger a process to retrieve state from a database. The state is modified, then the altered state is pushed back to the database. The microservice resets and is ready for another request.
Stateful microservices provide alternative microservice processing patterns. One stateful processing pattern maintains the state of things, entities, such as order entity instances, in memory. With this stateful entity approach, incoming requests that alter the state of a given entity are routed to the in-memory location of the entity. The request is processed, and the entity state is changed. Of course, the state change must be persisted. However, maintaining the state in memory significantly reduces the state retrieval overhead.
At first glance, this stateful entity approach looks complex. How are requests routed to the correct in-memory entity? How do you ensure there is only one instance of a given entity in a cluster of stateful microservice containers? What process is used to distribute entities across a cluster of multiple containers?
As it happens, that actor model is a perfect solution for handling large clusters of individual entity instances that are distributed across multiple containers. With the actor model, actors are the units of computation. Actors are implemented in software, and they must follow a simple processing pattern.
One unique actor characteristic is that the only way to communicate with an actor is to send it an asynchronous message. The message sender does not automatically wait for a response. In response to a message, an actor may make local decisions, send messages to other actors, it may create other actors, and it may determine how to respond to the next message. The actor as a unit of computation is a relatively simple but powerful building block.
Akka is an implementation of the actor model. From the Akka.io homepage, "Akka is a toolkit for building highly concurrent, distributed, and resilient message-driven applications."
Getting back to a stateful microservice processing pattern where entities are distributed across a cluster of containers, let's examine at a high-level how Akka solves the problem. First, Akka is highly concurrent. This feature addresses concurrently handling many entity instances. Next, being distributed, Akka manages running individual microservices across a cluster of containers. Finally, Akka is resilient and message-driven, this is needed to handle the routing of requests and responses to entity instances across a dynamically scaling cluster of containers.
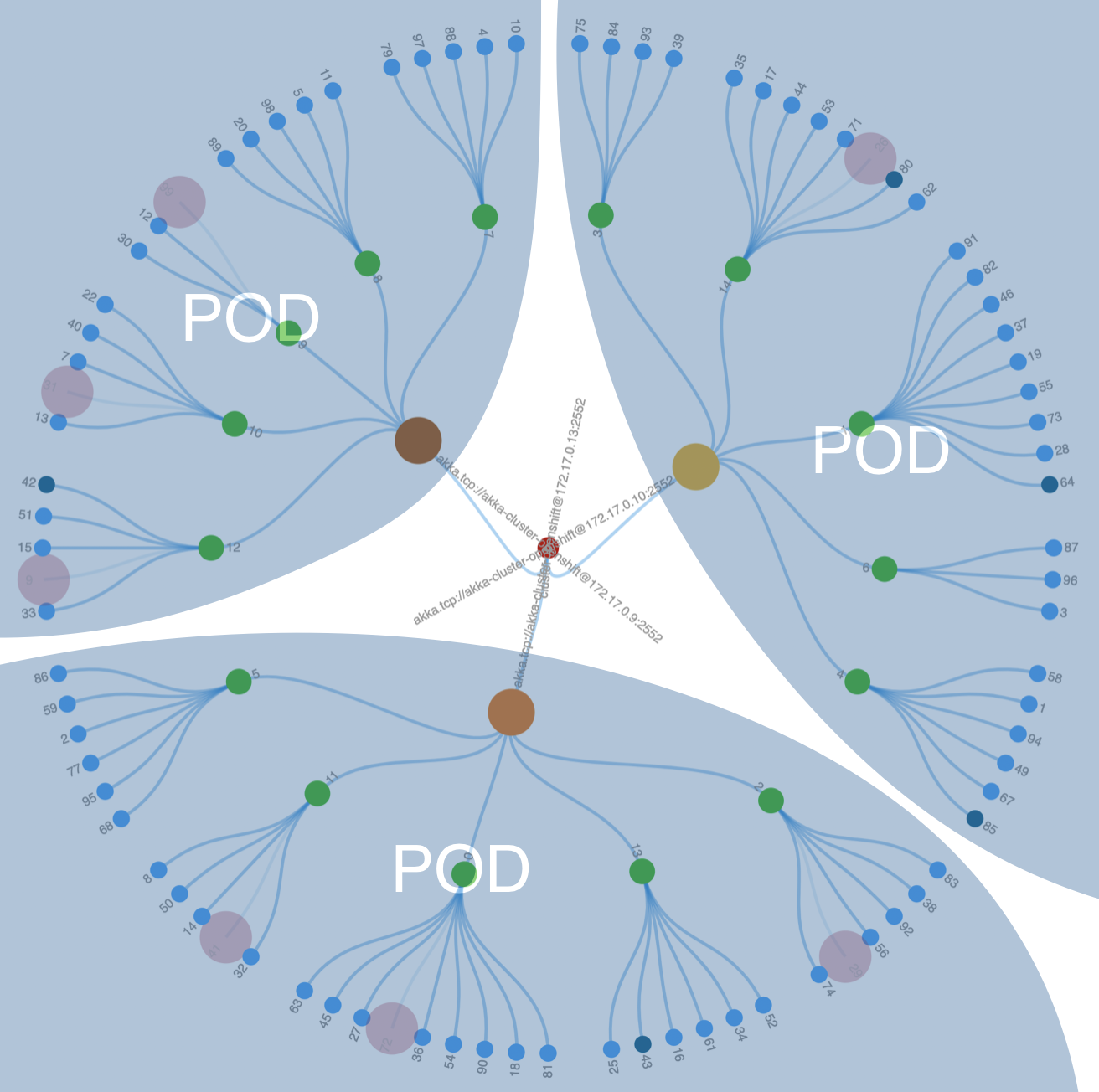
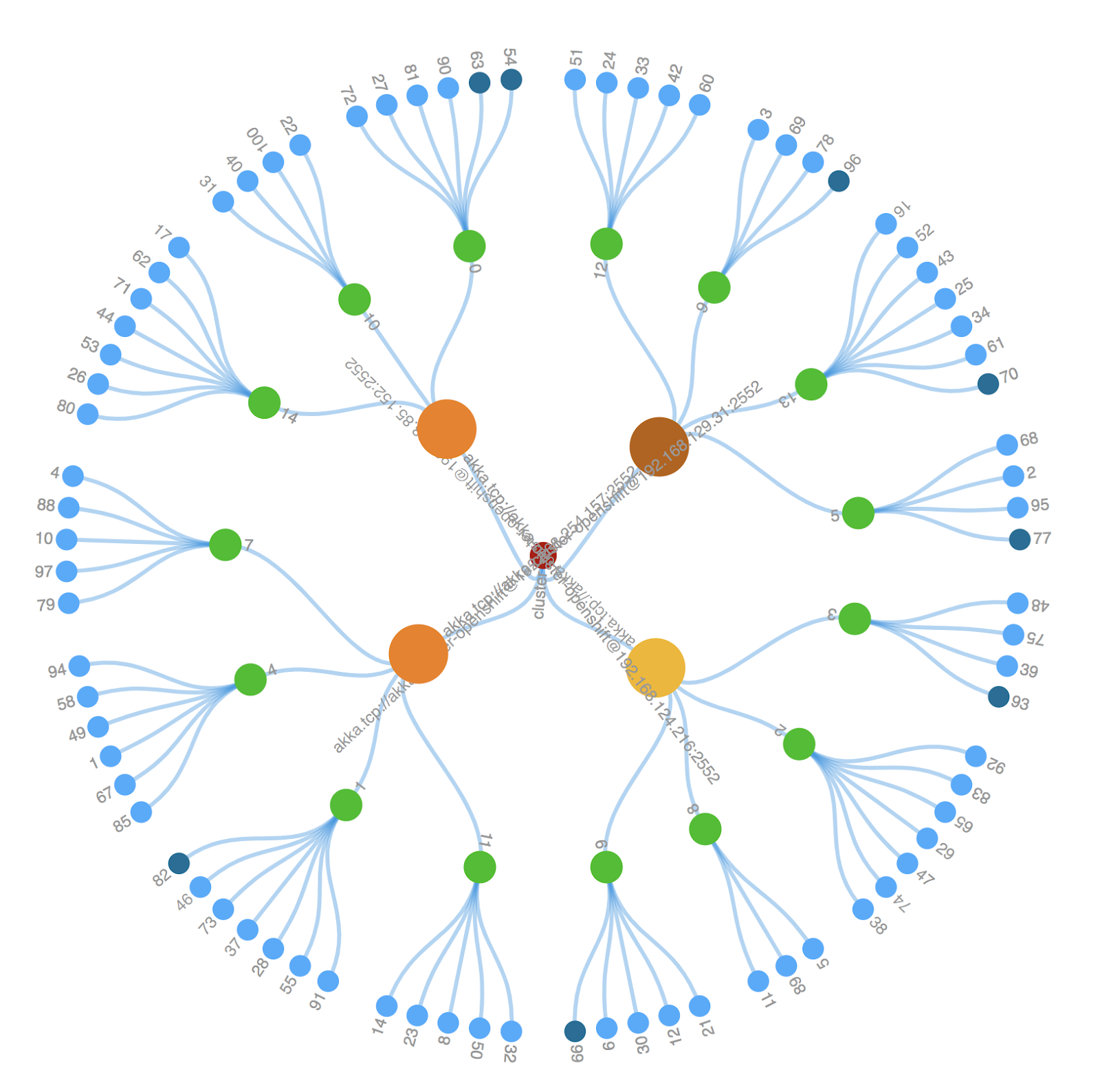
Let's look at a more specific example. In the figure above is a visualization of an Akka stateful microservice. This microservice is currently running across three containers. Each container is running a JVM, and Akka is running in each JVM. Within each JVM in the figure is a hierarchy of circles. These circles represent actors. Actors form a hierarchy of parent to child actors where the higher-level circles are actors that have created lower-level child actors.
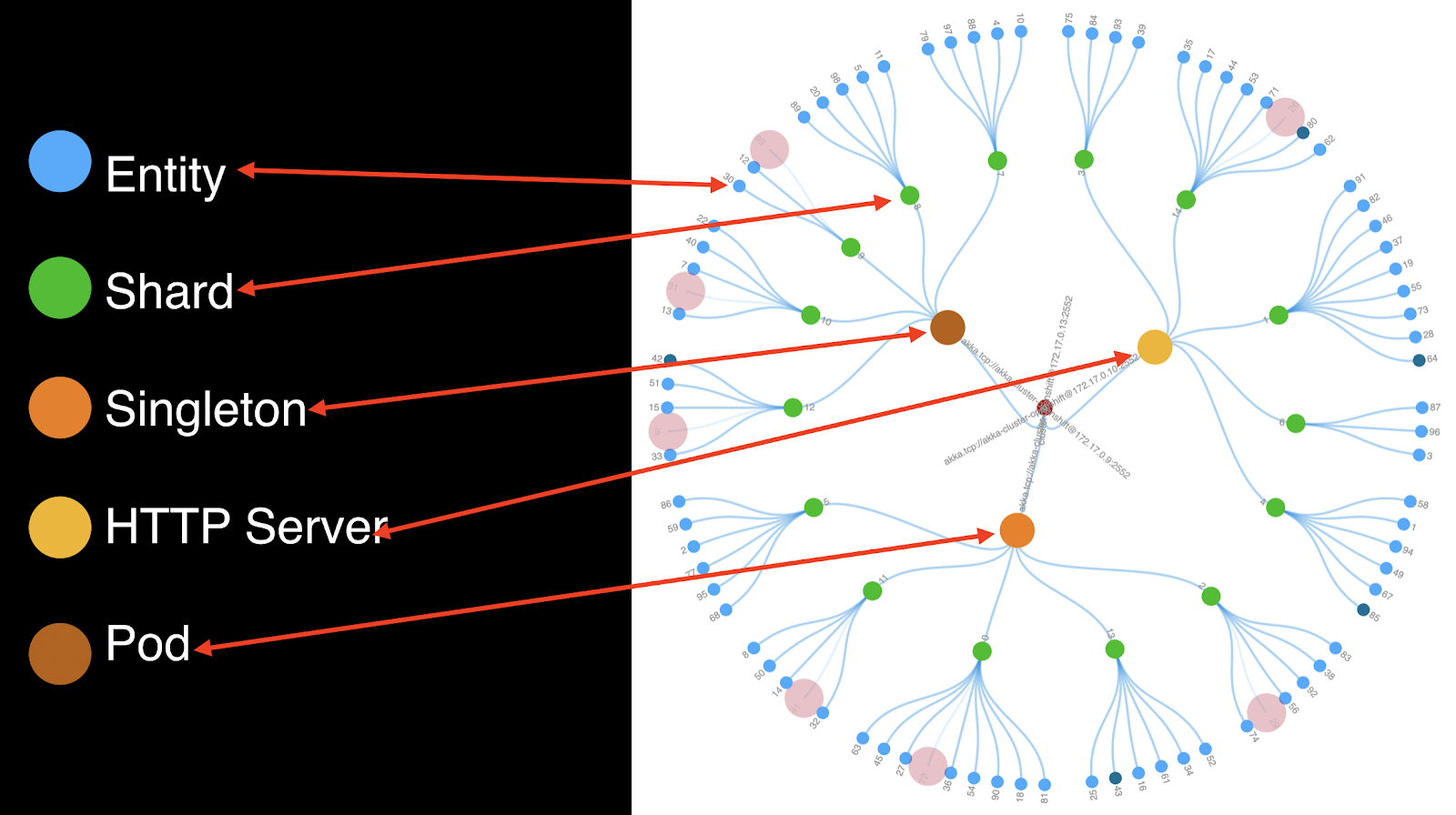
Each actor represented by the circles in the figure above represents different types of actors. At the perimeter are the main actors. They are entity actors. These entity actors are handling the state of entities, such as an order entity.
Next up the hierarchy are the green circles; they represent shard actors. Shard actors are responsible for distributing entity actors across the cluster. In this example, there are 15 shard actors. These 15 shard actors redistribute themselves and their associated entity actors across the cluster as the number of cluster containers expands and contracts.
The three relatively large circles represent multiple things. One of the things that these three circles represent is shard region actors. There is one shard region actor per JVM. The shard region actors are responsible for distributing shard actors. As the number of containers changes, the shard region and shard actors dynamically adjust the distribution of entity actors across the cluster.
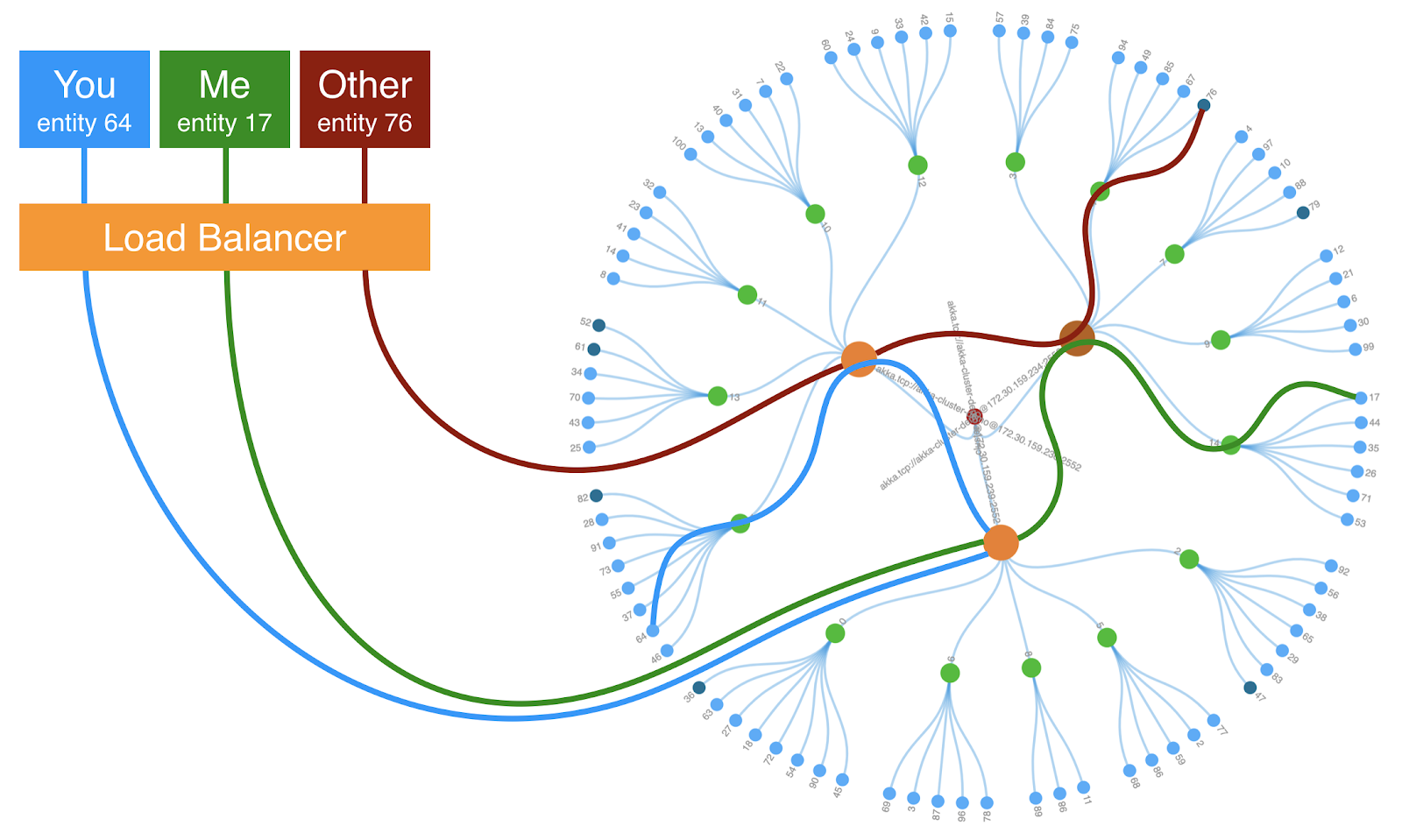
Here, shown above, is an example of how incoming requests are routed to entity actors. Say you are currently using an app that is interacting with entity 64. Imagine that each entity is a shopping cart that has a unique entity identifier, which in your case, is entity id 64.
Say a request to modify your shopping cart is routed to the bottom container in the diagram. This request is sent to the container local shard region actor. This shard region actor examines the message and determines that the message is for an entity actor that is located in another container in the cluster. This local shard region actor forwards the message to the shard region actor located in the container that contains the entity actor for id 64.
Next, the remote shard region actor also examines the message, and it determines that the message is for one of the local entity actors. The shard region actor determines which local shard the entity is responsible for entity 64. It forwards the message to the shard actor. The shard actor checks to see if the entity actor instance for id 64 is active. The entity actor is started as a child actor of the shard actor If it is not active. Once the entity actor has started, or if it is already running, the shard actor forwards the message to entity actor 64.
When an entity actor starts, it recovers its state from the database. This initial state recovery query happens each time an instance of an entity actor starts. Once started, the entity actor processes incoming messages. As entity state changes are made, the changes are persisted to the database.
Akka Cluster Operations using KUDO
The Operator pattern provides an extension mechanism to Kubernetes that captures human operator knowledge about a service, like an Akka Cluster, in software to automate its operation. KUDO, which stands for Kubernetes Universal Declarative Operator, is an open source toolkit for implementing Kubernetes Operators using a declarative approach, with a focus on ease of use for developers and cluster admins.
As a Developer
As a Developer of a KUDO Operator you have to author three types of YAML artifacts in a simple folder file structure. Clone the kudobuilder/operators repo to inspect the sample Akka Cluster operator artifacts and then later operate it. Shown in the following is the folder file structure of the sample Akka Cluster operator.
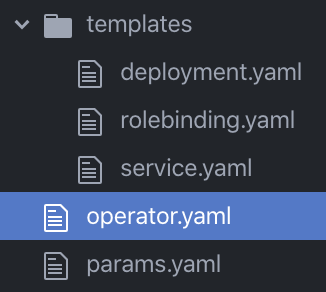
Let’s have a closer look at the YAML artifacts.
- The templates folder contains kubernetes resources that are applied by operator tasks
- the deployment.yaml defines the Akka Cluster Deployment
- the service.yaml defines how the Akka Cluster is exposed via a Service of type LoadBalancer
- the rolebinding.yaml defines a Role and a RoleBinding required by the Akka Cluster discovery process
- The operator.yaml defines the operators behavior in form of tasks and plans
- tasks list the resource templates that get applied together
- plans orchestrate tasks through phases and steps, e.g. deploy, update, ...
- The params.yaml defines the parameters that can be used to configure an Akka Cluster instance created by the operator
As an Operator
As an Operator you need the following prerequisites before you can get started with the sample Akka Cluster operator.
- A Kubernetes cluster. If you don’t have one already running we recommend installing D2iQ’s Konvoy, which is an enterprise ready Kubernetes distribution, providing all you expect for Day 2 operations
- Install the KUDO CLI, it comes as a kubectl plugin
- Install the KUDO controller into your Kubernetes cluster using the KUDO CLI
In the following we show the lifecycle operations supported by the KUDO based sample Akka Cluster operator.
Deploy
From the templates/akka/operator folder of the cloned kudobuilder/operators repo run the KUDO install command.
kubectl kudo install . --instance myakka
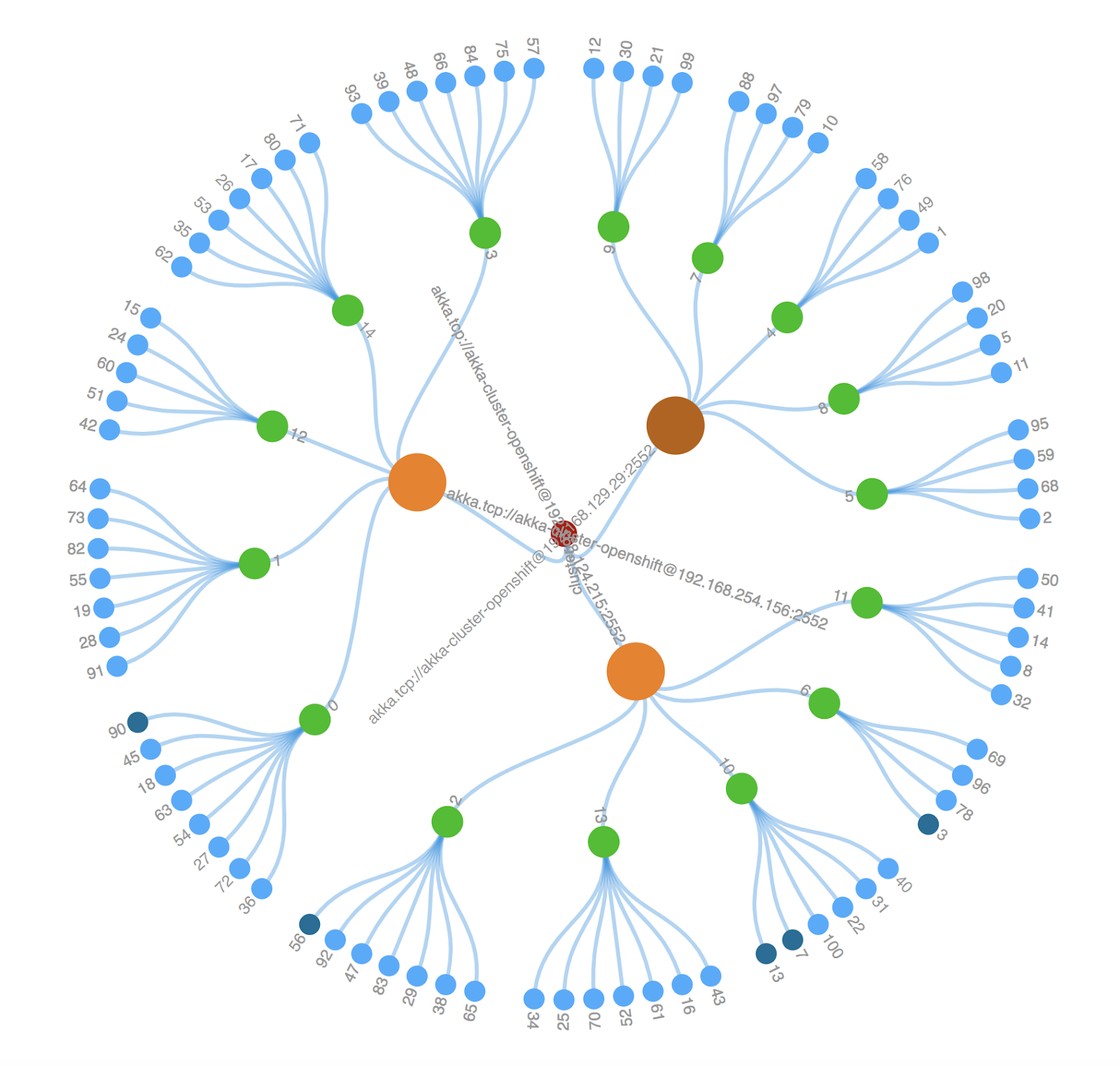
The created sample Akka Cluster serves the visual that we learned about in the first part of this blog. We get it by entering the URL created for its Service of type LoadBalancer into a browser. From the cluster visual we see that a cluster with three nodes got created, which is the default NODE_COUNT set in the params.yaml file.
Update
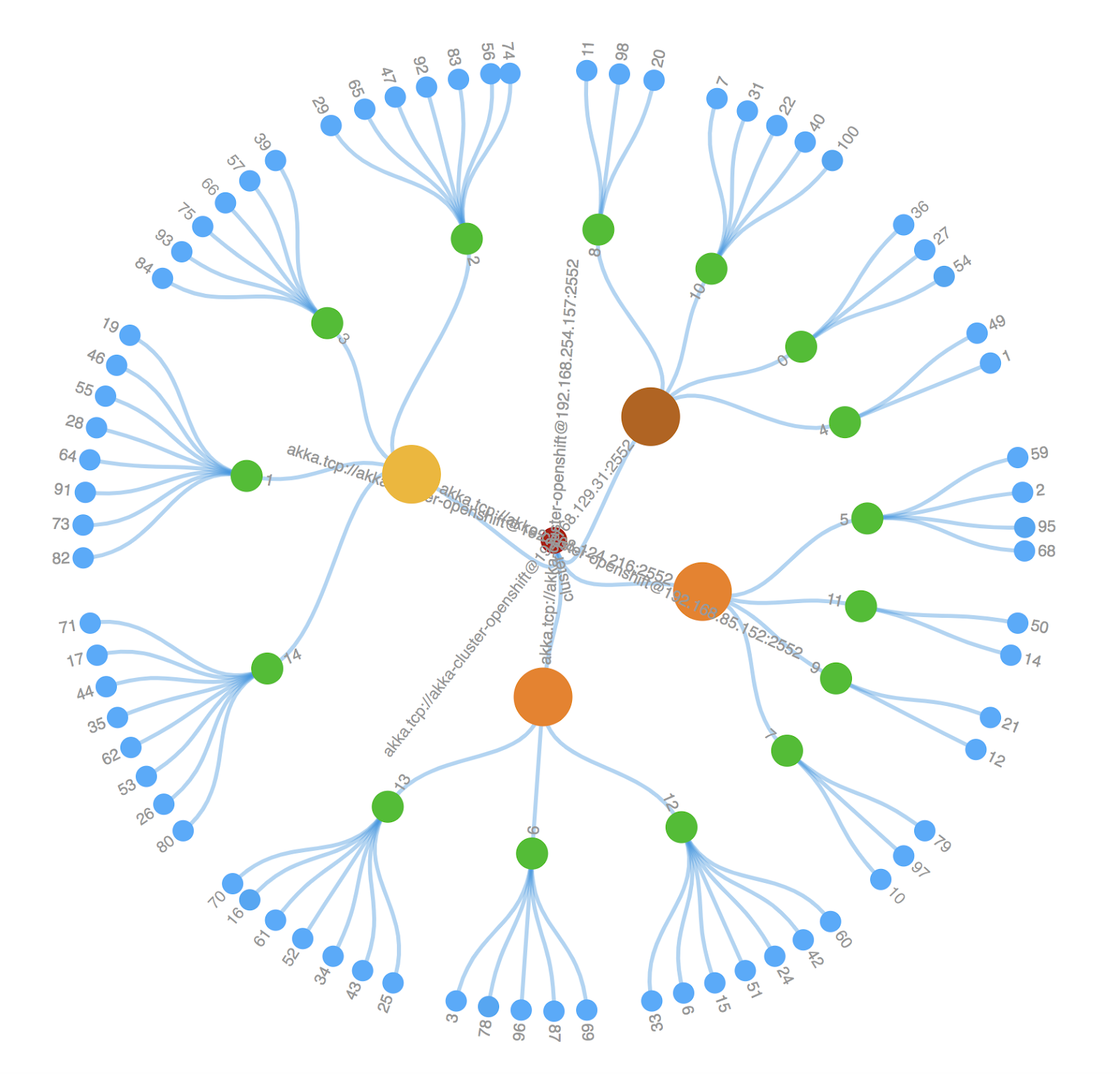
As an Operator you want to be able to scale the Akka Cluster as the request load increases. We scale the cluster by increasing the NODE_COUNT to four running the KUDO update command.
kubectl kudo update --instance myakka -p NODE_COUNT=4
Monitoring the cluster visual we see that a fourth cluster node gets created, and that the shards with their entities get redistributed.
Resilience
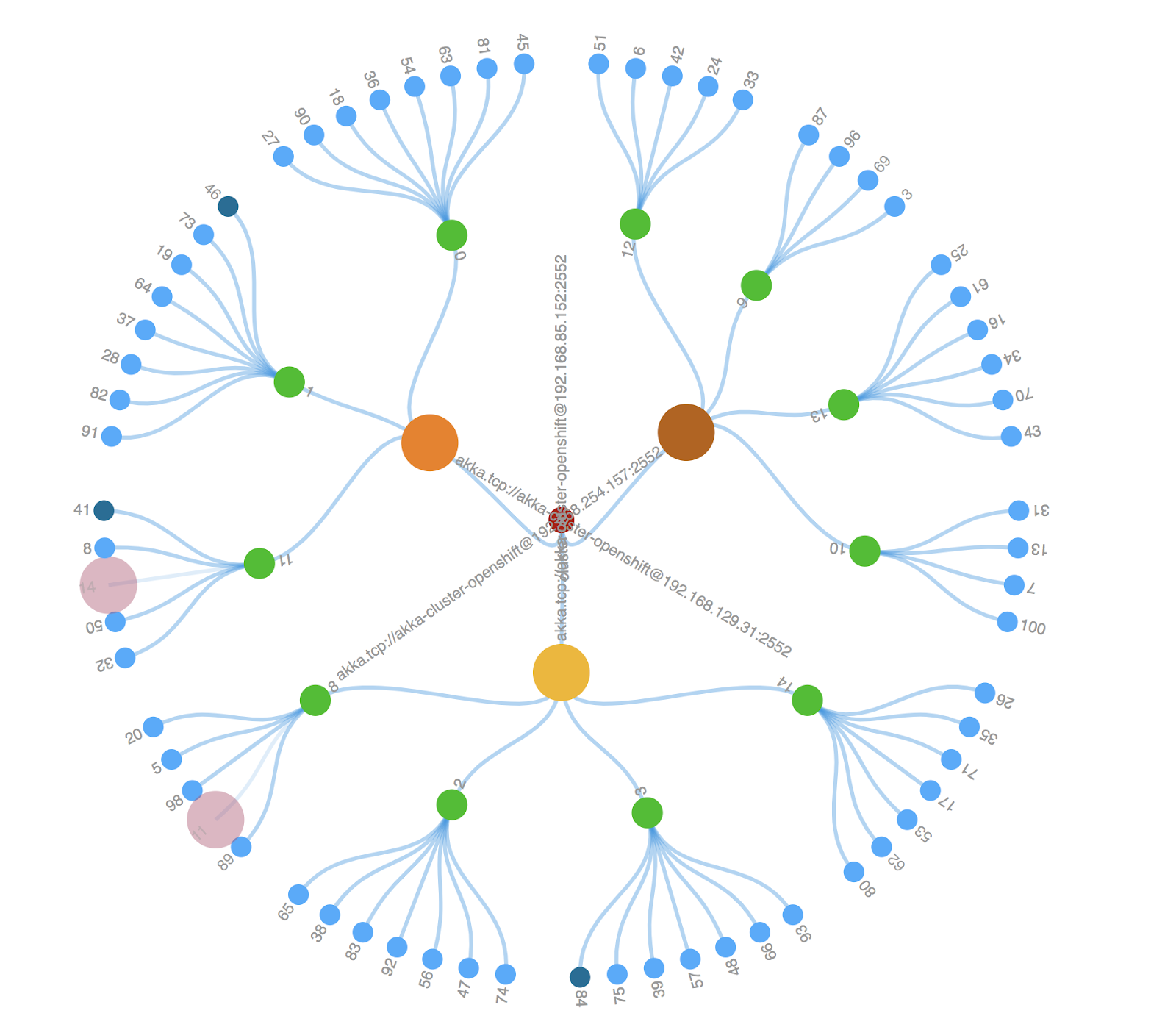
As an Operator you want that when cluster nodes fail that they get automatically restarted by the Akka Cluster operator. We simulate the failure by deleting a cluster pod running the following.
kubectl delete pod akka-cluster-demo-...
Monitoring the cluster visual we see the cluster nodes are going to 3 with respective shard reallocation. The Akka Cluster operator detects the situation and brings the cluster back to the NODE_COUNT goal state of 4.
Upgrade
As an Operator you want to be able to upgrade running Akka Cluster instances as newer versions of the Akka Cluster implementation become available. A new version of an Akka Cluster implementation is supported by a new version of the Akka Cluster operator. Besides the update of the container image, a new implementation in general can also necessitate other changes to the operator, e.g supporting new parameters, changes to plans, and so on.
We create a new version of our sample Akka Cluster operator with edits of the following YAML artifacts.
- operator.yaml
set operatorVersion: "0.2.0"
- templates/deployment.yaml
set image: kwehden/akka-cluster-demo:1.0.3
From the templates/akka/operator folder run the KUDO upgrade command.
kubectl kudo upgrade . --instance myakka
Monitoring the cluster visual we see that one by one the cluster nodes get replaced. Checking the new pod’s YAML we see that the new image version is used.
kubectl get pod akka-cluster-demo-... -o yaml
Conclusion
The combination of Akka and Kubernetes has unlocked the delivery a whole new class of Cloud Native applications; an elastic, responsive, resilient, stateful application layer (Akka), with a battle tested, dynamic infrastructure orchestrator (Kubernetes) gives developers the power to manage vast and complex state models as if they were local, single threaded representations of data. KUDO goes further than Kubernetes to deliver a simple, rich set of descriptors and operations that are key to managing both the runtime, and the persistence stores necessary for stateful applications and systems, so ensuring that you are scaling the database, or the event log at the same rate as the application is trivial. This cannot be underestimated in importance, and the elegance by which these coordination tasks are solved cannot be overemphasized.
To learn more, visit https://kudo.dev/ and https://akka.io/


