






Feb 29, 2016
D2iQ
D2iQ
6 min read
Want to road test your shiny new DCOS cluster to see what it can do? Well, I've been doing scale testing from our San Francisco lab and have some tips I can share with the community. Read on to learn more!
On your marks . . .
If you've read our recent post "Meet Marathon: Production-ready containers at scale", you know that a properly tuned DCOS cluster can run like a Formula 1 racer with a tailwind. However, just like with running a race car, you'll get the best scale performance with careful tuning of your cluster. DCOS is a suite of interacting parts, and their timings can be adjusted for maximum performance in any condition. Similar to the way a high-performance auto is tuned to match the track and driver, we can tune our cluster for best behavior across a variety of workloads and cluster layouts.
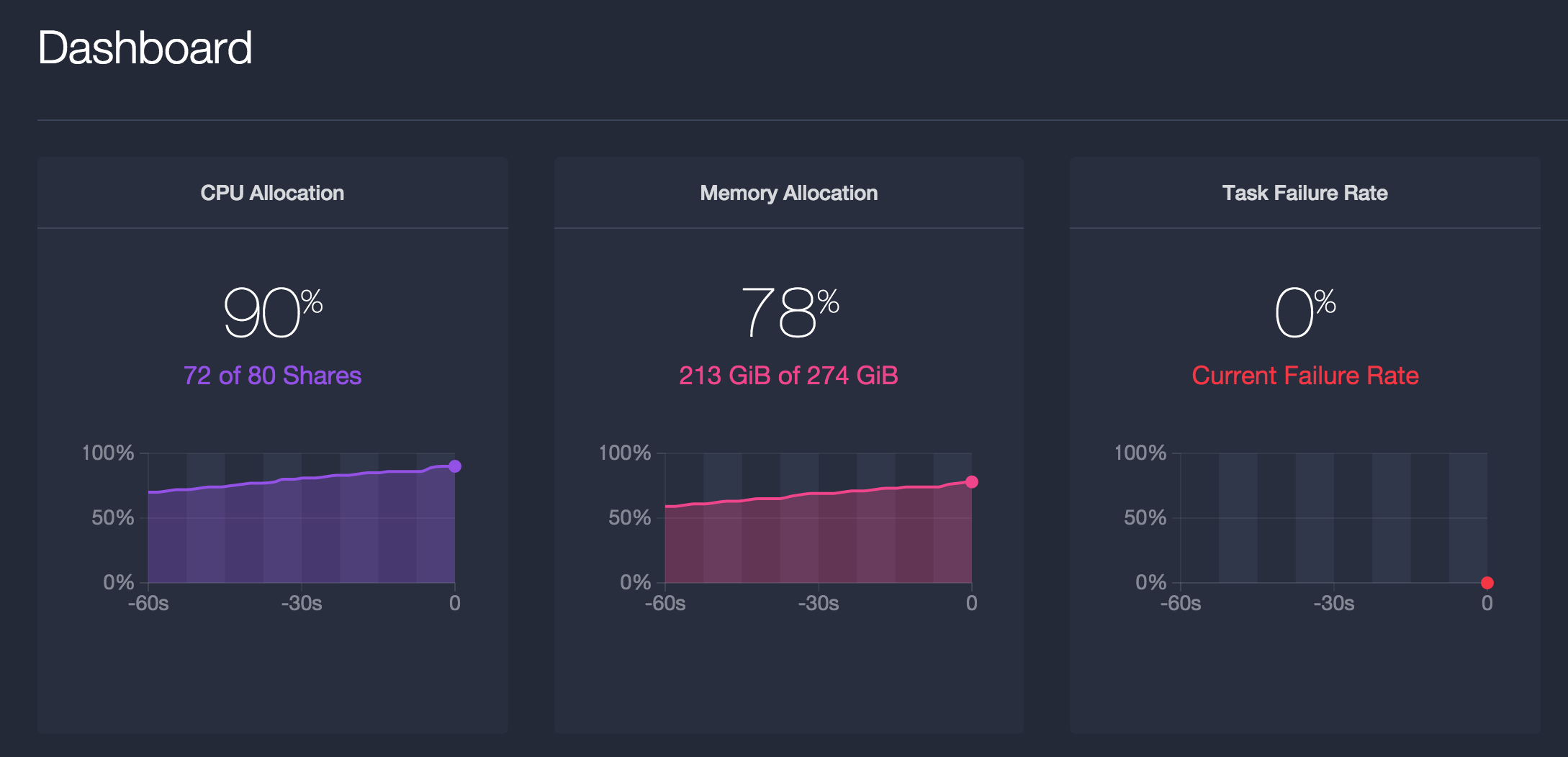
To get prepared, we'll need to consider factors such as the number, type and size of the machines in the cluster. For my testing, I used a 20-node AWS cluster of m3.xlarge instances, but your considerations may be a bit different (especially if, for example, you have access to some of the high-performance computing units I assist folks with in my day job).
Protip: AWS instances don't have the horsepower of bare metal, so it pays to be a bit conservative when configuring Marathon for that scenario. With its roots in large-scale datacenter operations, Mesos can present quite the firehose to these EC2 units and we need to be conscious of this.
Calculating configuration
With 4 CPUs and 15GB of RAM per node, I figured I could host dozens of tasks per agent as long as I didn't overwhelm them with task launches. Here are some general guidelines about how your cluster size will affect the choices you make, and how I have addressed them:
I've chosen 3 instances of Marathon for high availability.
I've set launch_tokens to about 5x the total number of nodes. This limits the total number of task launches that can be in flight for the whole Marathon environment, so it's important to adjust this for high throughput.
My max_tasks_per_offer should be no more than 125 percent of the total number of cores on my smallest machine (4 cores, in this case). This will prevent us from sending too large of a volley of launch requests to the same agent.
Just to stay on the safe side, let's put both heap-min and heap-max at a somewhat generous 1536mb.
Sometimes I like to set heap-min equal to heap-max; we expect to use all of the heap quickly, and don't see a value to reserving less. This way, we can prevent resizing delays if Marathon has to ask for a malloc.
I like a 100 percent margin over my heap-max to make sure I never OOM, so mem for the container is 3072.
Marathon can be verbose with its logging, so I'll set that to a lower level.
Get set . . .
To make things easy, and because I have a surfeit of resources in my cluster, I decided to use high-availability Marathon on Marathon, as a DCOS package. This made configuring the Marathon settings simple. Here's a peek at my options.json file:
{ "application": { "cpus": 2.0, "mem": 3072.0, "instances": 3 }, "jvm": { "heap-min": 1536, "heap-max": 1536 }, "marathon": { "logging-level": "warn", "max-tasks-per-offer": 5, "launch-tokens": 100 }}More information about this can be found in our documentation, on a page called "Customizing a DCOS Service."
Selecting a test application
I knew I wanted something small and fast to deploy at scale, so I elected to pull the python:2-alpine docker container to run python -m SimpleHTTPServer $PORT0. At less than 30MB, this container will pull, stage and run as fast as anything.
Protip: Make sure your test application stays running on its own and opens at least one port that will give a HTTP 200 response to incoming traffic, so that it will pass Marathon health checks. Also, unless forcePullImage is set to "true," the image only gets pulled once per agent. A huge time and bandwidth saver!
Go!
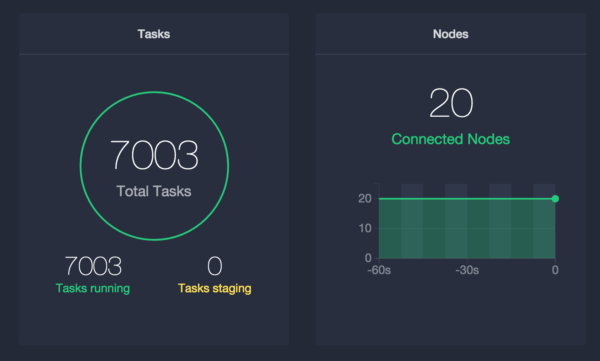
With my Marathon all loaded up and ready to go, it's time to scale some apps! I did some quick back-of-the-envelope math and figured that the lower of my aggregate 80 CPUs divided by the CPU share of 0.01 (8000), or 274 total gigabytes divided by 32MB per task (8562) with a bit of safety margin, brings me to 7000 tasks. To make sure my tasks can pass their health checks, it's important to consider these resource reservation values the bare minimum in AWS environments, because you should never lie to the executor.
Let's talk about that . . .
Don't lie to the executor
I was standing around the water cooler discussing the scale tests with some of the Mesos core team members, and what topic came up but that of lying to the executor by understating the amount of resources needed for a test task. A co-worker overheard us talking and said, "Why wouldn't you lie to the executor? They're about to kill you!"
We explained to him that we were not talking about an executioner, but in fact the executor process that Mesos spawns to look over each soon-to-be container. All joking aside, it's important to remember that the Docker executor and other processes need room and CPU cycles to support your tasks. Failing to give them enough room opens up the risk of the executor failing to make timely reports to Mesos, which in turn can result in the executor (and, thus, the task) being lost.
Here's a look at my app description (some objects removed for brevity):
{"id": "/python","cmd": "python -m SimpleHTTPServer $PORT0","instances": 7000,"cpus": 0.01,"mem": 32,"container": { "type": "DOCKER", "docker": { "image": "python:2-alpine" }},"healthChecks": [ { "path": "/", "protocol": "HTTP", "portIndex": 0, "gracePeriodSeconds": 100, "intervalSeconds": 20, "timeoutSeconds": 20, "maxConsecutiveFailures": 3, "ignoreHttp1xx": false }],"upgradeStrategy": { "minimumHealthCapacity": 0.8, "maximumOverCapacity": 0.2 }}This is found at the Marathon REST API, accessible at http://<dcos-url>/service/marathon/v2/apps. A full specification of the API can be found here.
Protip: I've tweaked my upgradeStrategy to allow more pain-free upgrades and restarts. By allowing less than 1 minimumHealthCapacity, I'm enabling the cluster to remove a small number of tasks before their replacements are online. With maximumOverCapacity less than 1, I'm preventing the cluster from over-reaching by trying to start an entire 7,000 task armada prior to letting the old tasks go in an upgrade scenario.
Finish line and final notes
Scaling up to 7,000 tasks was quick and painless with this recipe. In a few minutes, I had an army of Docker containers serving anything I need.
I'll share a few final notes about this configuration:
I'm using tighter than usual healthChecks because I'm launching a lot of Dockers simultaneously on the nodes over a period of time, and we want to make sure that any fails are detected and cleaned early.
It's important to be careful about setting the container's cpu and mem to sensible values for your hardware or VMs.
Let us know your thoughts on Hacker News!


