






Feb 18, 2016
Joerg Schad
D2iQ
15 min read
This post was written by Max Neunhöffer of ArangoDB and Jörg Schad of Mesosphere.
Scheduling and relocating essentially stateless services in Docker containers is nice, but what about services that need to keep their state?
A Docker container using a volume that refers to an actual directory in the local filesystem cannot easily be stopped and restarted on another machine. But for performance reasons, distributed databases and other stateful services often want to use local storage, preferably solid-state drives (SSDs). Therefore, a datacenter operating system needs to give its applications a way to reserve and access local storage "officially"; make sure a certain task is rescheduled on the same node after a restart; and find its local storage again.
These are the fundamental challenges solved by the persistence primitives that were introduced in Mesos 0.23. In this blog post, we explain how Mesos persistence primitives work and present a concrete case study with the ArangoDB distributed NoSQL database, one of the first Mesosphere-certified frameworks to use persistent volumes.
Overview
In order to allow tasks to access persisted data even after failures, Mesos has to solve two problems:
- How to allow the frameworks to receive resource offers on the same agent node in order to restart the task.
- How to keep the data persistent across failures and task restart. By default, Mesos will clean up all data in a task's sandbox when the task is stopped for any reason.
These problems are solvable with a combination of different persistence primitives.
Dynamic Reservations
A framework can use dynamic reservations to ensure that it will receive resource offers from the particular agent where its persistent data is stored. These dynamic reservations allow a framework to reserve resources that have been offered to it for its role. The reserved resources will not be offered to any other role. Please refer to the Reservation documentation for details regarding reservation mechanisms available in Mesos.
Persistent Volumes
Persistent volumes allow frameworks and operators to create a persistent volume from disk resources. Persistent volumes exist outside the task's sandbox and will persist on the node even after the task dies or completes. When the task exits, its resources (including the persistent volume) can be offered back to the role, so that a framework in that role can launch the same task again, launch a recovery task, or launch a new task that consumes the previous task's output as its input. Note that persistent volumes can only be created from reserved disk resources.
Refer to the Persistent Volumes documentation for details on how to create and destroy persistent volumes. Furthermore, Mesos contains a sample framework that shows the basics of handling of persistent volumes.
Best practices for using persistence primitives
Hera are a handful of tips for getting started with persistence primitives:
- Create both the dynamic reservation and persistent volume with a single acceptOffers call.
- Applications should be prepared to detect failures and correct for them (e.g., by retrying the operation) because attempts to dynamically reserve resources or create persistent volumes might fail. This could happen, for example, because the network message containing the operation did not reach the master or because the master rejected the operation.
- Be aware that it can be difficult to detect that a dynamic reservation has failed when using the scheduler API. Reservations do not have unique identifiers and the Mesos master does not provide explicit feedback on whether a reservation request has succeeded or failed. Techniques for dealing with this behavior are discussed below in the example of ArangoDB. Note that in the future, Mesos will support Reservation Labels, thus making this process much easier.
- Because there are a large number of potential states, it often makes sense to structure application logic for persisting frameworks as a "state machine." The application transitions from its initial state (no reserved resources and no persistent volumes) to a single terminal state (necessary resources reserved and persistent volume created). The ArangoDB example demonstrates this in more detail.
- Because persistent volumes are associated with roles, a volume might be offered to any of the frameworks that are registered in that role. For example, a persistent volume might be created by one framework and then offered to a different framework in the same role. This can be used to pass large volumes of data between frameworks in a convenient way. However, this behavior might also allow sensitive data created by one framework to be read or modified by another framework in the same role.
See Programming with Persistent Volumes for more details.
What is ArangoDB and why does it need persistence?
ArangoDB is a distributed multi-model database, meaning that it is a document store, a key/value store and a graph database, all in the same engine and with a unified query language that allows it to use all three data models within a single query.
As a distributed application, ArangoDB benefits greatly from running on Apache Mesos or the Mesosphere Datacenter Operating System because the infrastructure software takes care of distribution and scheduling of tasks, management of cluster resources, and failure detection. Mesos can deploy software via Docker containers, thus solving for developers many of the headaches of distributed systems.
However, the very purpose of a database is to keep mutable state, and because the database also has to be durable, ArangoDB needs access to persistent storage. Ideally, this in the form of locally attached SSD drives. These days, such local SSD drives offer the best option for I/O performance, durability guarantees and predictable behavior with respect to sync operations.
An entirely different approach would be to delegate all durability issues to a distributed file system and just build the data store as a distributed application that relies on a locally mounted volume. For ArangoDB, we decided against this approach because of performance considerations and for greater durability. As a consequence, the various tasks of an ArangoDB cluster need local storage and strongly prefer to find their own data again when they are restarted (after a version upgrade, for example). This is why we chose to use the persistence primitives in Apache Mesos.
Overview and different task types
There are four different types of ArangoDB tasks:
- Agency tasks: The agency is a central low-volume and low-speed datastore that stores the ArangoDB cluster configuration and information about databases and collections in the cluster. The agency also uses Raft, a consensus protocol, to maintain a highly available replicated log for cluster-wide synchronization and locking operations. The agency's data changes infrequently, but is crucial to the operation of the cluster. That means the agency data needs to use persistent volumes but the I/O speed is not important.
- Coordinator tasks: The coordinator tasks are the client-facing ArangoDB instances. They are essentially stateless: they take the HTTP requests from the outside, know about the cluster configuration by means of the agency, and distribute the query workload across the cluster. The coordinators also know about the details of the sharding and can thus devise distributed query execution plans and organize their execution.
- Primary DB server tasks: The primary DB servers hold the data. They have the mutable state and do the heavy lifting for the database as a whole. Therefore, they need persistent volumes and good I/O performance.
- Secondary DB server tasks: The secondary DB servers are asynchronous replicas of the primary DB servers. They regularly poll their respective primary for changes and apply them to their copy of the data, so they also need persistent volumes. If a primary DB server fails, its secondary can immediately take over.
Duties of the framework scheduler
An ArangoDB cluster launches in the following sequence:
- The agency tasks launch.
- The primary DB servers start.
- The secondary DB servers start after the primaries so that a secondary does not runon the same machine as its primary.
- The coordinators launch.
- ArangoDB cluster bootstrap procedures run. These can only execute when all tasks are up and running.
The framework scheduler also has to take action and observe similar dependency requirements in the following cases:
- The cluster needs to be scaled up or down in the DB server layer to change its data capacity.
- The cluster needs to scaled up or down in the coordinator layer to change its query capacity.
- The cluster needs to upgraded without service interruption.
- The cluster needs to be shut down and later be restarted.
The framework scheduler also handles much of the failover management. Because the Apache Mesos master informs the framework scheduler about killed tasks and lost Mesos agents, the framework scheduler organizes automatic failover. In order to do this, the framework scheduler observes the state of tasks in the cluster and, in many cases, maintains timestamps and watch timeouts.
To perform these duties, the framework scheduler runs a main event loop. The main event loop gets resource offers from other threads, receives updates from Mesos, observes timeouts and reacts to these events. We explain this in greater detail in the next sections.
The state diagram of a DB server
Here is the state diagram of a task in an ArangoDB cluster that requires a persistent volume (one of the DB servers, for instance):
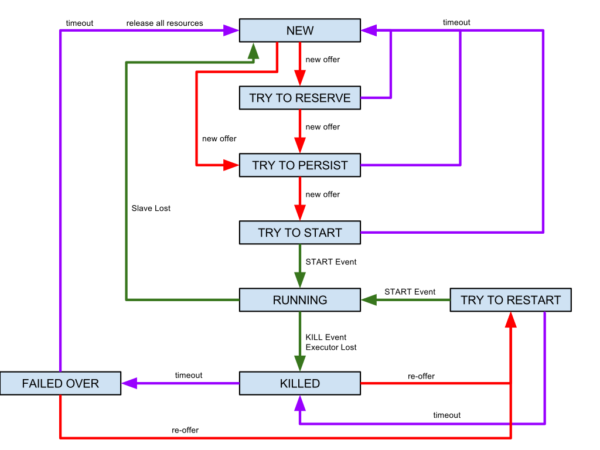
State NEW
The task begins in the NEW state: it does not yet have the dynamic resource reservation and persistent volumes it needs. Once a resource offer comes in (for the generic role "*") that contains enough CPU, memory, disk and port resources, the framework scheduler tries to dynamically reserve the necessary resources for the role "arangodb" by returning a mesos::Offer::Operation message of type RESERVE. When this happens, the task state transitions to TRY TO RESERVE.
State TRY TO RESERVE
The Mesos master will usually answer the task's reservation request by sending a new offer from the same Mesos agent, this time with the requested part of the resources dynamically reserved for the role "arangodb." Once this happens, the framework scheduler tries to create a persistent volume for the task by returning a mesos::Offer::Operation of type CREATE and moves the task state to TRY TO PERSIST. A persistent volume with a new globally unique ID is created for the configured principal of the framework.
State TRY TO PERSIST
The Mesos master answers the creation request by sending a new offer from the same Mesos agent, this time with the reserved resources and the persistent volume. At this point, the framework scheduler asks Mesos to launch the task based on the latest offer with the persistent volume. As a result, the Docker containerizer launches the Docker container and mounts the persistent volume to a well-defined path in the container. The task state now changes to TRY TO START.
State TRY TO START
After a short staging phase, the Mesos Master informs the framework scheduler that the task is up and running. The framework scheduler sets the last state to RUNNING.
Once all previous tasks a have reached this state, the framework scheduler can determine which other task types depend on these tasks and launch them. If all the tasks in the cluster have started, the framework scheduler runs the cluster bootstrapping procedures.
The framework scheduler can go directly from NEW to TRY TO PERSIST if there is a static reservation for the role "arangodb" on some Mesos agents. In this case, the framework scheduler would immediately get resource offers with enough reserved resources and can try to create the persistent volume right away.
All "TRY"-states, from TRY TO RESERVE to TRY TO START, have a timeout because the next expected offer from the Mesos master may not come in. If the state times out, the framework scheduler resets the state of the task to NEW in order to receive incoming resource offers from other Mesos agents.
States RUNNING and failure states
Ideally, task in the RUNNING state does not need to interact with the framework scheduler. However, tasks can die and even complete Mesos agents can get lost because of a hardware failure or as part of a planned maintenance procedure. An outage can be real node failure or can appear to happen due to some network connectivity failure.
A resilient distributed system has to react gracefully. Persistent volumes allow a task to restart quickly, reconnect to the cluster and continue its work. When the framework scheduler is informed about a killed task (or a lost Mesos agent), it moves its state to KILLED and waits for resource offers as usual.
Provided the network is up, a resource offer will usually arrive from the same Mesos agent the task was running on. It will contain the task's reserved resources and the persistent volume, which is marked with a unique ID for that task. If this happens, the framework scheduler immediately tries to restart the task and moves it to TRY TO RESTART. TRY TO RESTART is essentially equivalent to TRY TO START, except that the timeout behavior is different. From state TRY TO RESTART, the task goes back to state KILLED when a timeout happens, rather than to NEW. There is another, longer timeout for automatic failover.
If a killed task on a primary DB server cannot be restarted quickly enough, the framework scheduler switches the role of this primary with its secondary server. The old secondary becomes the new primary and immediately takes over the service. The old primary now becomes the secondary and is moved to state FAILED OVER. The framework scheduler will still try to restart it, since its persistent data makes it quicker to get it back to fully synchronized service than a completely new instance, which would have to synchronize all the data. Therefore, a new incoming offer can lead to a TRY TO RESTART state exactly as for the KILLED state.
Eventually, the framework scheduler will have to give up on that task and its persistent state. After a longer timeout, the FAILED OVER task goes back to NEW. Behind the scenes, the framework scheduler declares the task dead and creates a new one. The framework scheduler then destroys the dead task's persistent volume and releases the dynamically reserved resources.
If the scheduler did not clean up after dead tasks, the Mesos cluster could leak resources: the resources would be permanently reserved for our framework and could not be reused by other frameworks. In the case of the persistent volume, our framework could not even use it, since its unique ID binds it permanently to a particular task instance.
Whenever the framework scheduler receives an offer with a persistent volume or a dynamic reservation that none of the planned tasks are waiting for, it answers with a mesos::Offer::Operation message to destroy the volume or release the dynamic reservation respectively. This also gets rid of resources that were left over after a timeout in the creation phase.
Target, plan and current
Like any part of a distributed system, the framework scheduler itself needs to be resilient against faults. We achieve this in two ways. First, the framework scheduler is started up as a Marathon application with one instance, so Marathon makes sure that there is always one instance running in the Mesos cluster. Second, the internal state of the framework scheduler is persisted via the Apache Mesos state abstraction, which usually stores data in Zookeeper. If a new instance of the framework scheduler starts up, it can load the state of its predecessor from Mesos and continue with the usual operation.
For this to work seamlessly, we implemented the suggested reconciliation protocol: if the framework scheduler finds a persisted state, it first tries to reconcile its view of the states of running tasks with Mesos' view. To do this, the framework scheduler sends corresponding messages to the Mesos master for all tasks it knows about. The Mesos master responds with a status update message that updates the state in the framework scheduler.
The persisted state of the framework scheduler is subdivided into three parts: target, plan and current. The user of the ArangoDB cluster modifies the target with relatively coarse information about the cluster, such as number of DB server tasks, number of coordinator tasks and so on. The framework scheduler constantly monitors the target and, whenever there is a change, derives from the plan from that.
The plan is more concrete than the target and contains, for instance, the state of the individual tasks and what the framework scheduler wants to achieve for each of them. Since the plan is machine-generated, it will always be in a sensible state and thus always describes a viable situation to achieve.
The current part of the state is constantly updated by the framework scheduler, which uses messages it receives from Mesos. Information about successfully started tasks, killed tasks and the like are used to update current, which always reflects the actual current truth about the ArangoDB cluster. The framework scheduler constantly tries to make current the same as plan by reacting to resource offers accordingly.
The "trinity" of target, plan and current is a very general approach to building a resilient, self-healing distributed system. We expect it to be useful for many such systems. We use the same approach within an ArangoDB cluster with very good results with respect to robustness and self-healing properties.
Conclusion
Persistence primitives are a powerful new tool to enable more stateful frameworks. For example, they made it possible for ArangoDB to develop a distributed persistence framework that easily scales out to several hundred nodes.
Here, we presented our experience this system—one of the first attempts to build a framework using persistence primitives. Given the large number of different states and timeouts, we would recommend modeling the persistent volume logic as a state machine where we want to converge to a target state (all persistent volumes created and mounted). This approach also allows you to implement important failover operations in the framework scheduler, building a robust stateful framework.


