






Aug 14, 2015
Ken Sipe
D2iQ

3 min read
Running machine learning algorithms and big data analytics can no longer be done on a single machine. Instead, we look at breaking down our analysis and algorithms into smaller pieces. While the analysis of large volumes of data pre-dates it, Google's 2004 paper on MapReduce represented a significant push toward new ideas for simplifying big data processing on large clusters.
This paper identified at least two needs necessary for big data processing: (1) cluster management and orchestration, and (2) data storage. Since then, Apache Hadoop has dominated as a big data solution for many organizations, acting as the open source implementation of the system Google described in its paper. Originally, Hadoop provided its own flavor of MapReduce, as well as the Hadoop Distributed File System (HDFS) for the storage of large data sets. It has since added a layer called YARN for cluster orchestration.
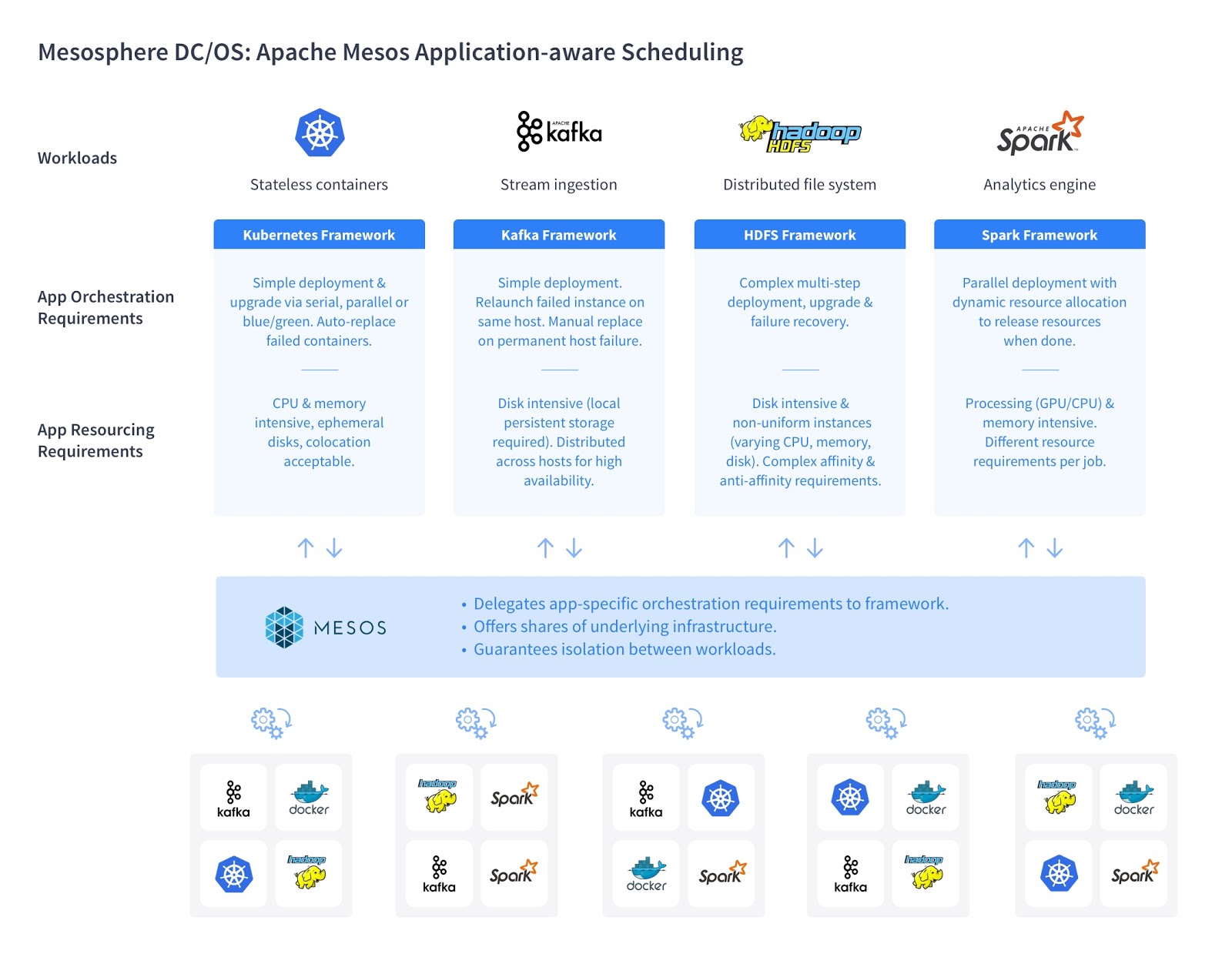
Based on a number of factors -- performance being the largest -- there has recently been a migration to Apache Spark for MapReduce-style computing. And the most powerful option for task orchestration with Spark is Apache Mesos with an HDFS backend. HDFS and Spark running on Mesos allows you to easily run big data solutions in your datacenter, and take advantage of Mesos features such as ease of administration, scalability, error recovery and fault tolerance, and efficient resource utilization.
Indeed, we're already seeing leading companies build their analytics environments around Spark, HDFS and Mesos.
Setting up Spark and HDFS on Mesos
In order to establish this technology stack, you will need to:
- Establish a Mesos cluster of at least 1 master and 5 Mesos agent nodes
- Provision HDFS
- Provision Mesos-DNS
- Start the Spark Framework
- Optionally provision Docker
At Mesosphere, we strive to simplify these steps as much as possible. The fastest possible way to get started is to use our Datacenter Operating System (DCOS) with the details below. An alternative is to use the Mesos provisioning tool for Google Cloud Platform.
When you use the Google provisioning tool, the cluster will provision Apache Mesos along with Docker. Taking this approach, it is necessary for you to set up Mesos-DNS followed by running the HDFS and Spark services. Below is an 11-minute video on setting up this environment. At the completion of following these steps, you will be ready to run Spark jobs on your Mesos cluster.
[embed]https://www.youtube.com/embed/UhA12S_uoTE[/embed]
DCOS FTW
However, a big focus here at Mesosphere is to build a product that helps users get up and running quicky on new projects -- in this case, advanced analytics. That's why we developed the DCOS. At the core of DCOS is Apache Mesos, along with a cluster visualization UI and a set of command-line tools. Additional conveniences include:
- Provisioning with Docker Support
- Provisioning with Mesos-DNS
- Packaging for many popular services, including Spark and HDFS
While we need 11 minutes to setup Spark and HDFS on Mesos using the provisioning tool with GCE, setting up the same environment using DCOS requires only a few commands. The script would include the following:
# update dcos
dcos package update
# install hdfs
dcos package install hdfs
# install spark
dcos package install spark
That's it! After all the installed services indicate that they are healthy, you are ready to run Spark jobs. The entire big data stack is install in just a few minutes.


