






Apr 13, 2020
Chris Gaun
D2iQ

Apr 13, 2020
Sam Briesemeister
D2iQ

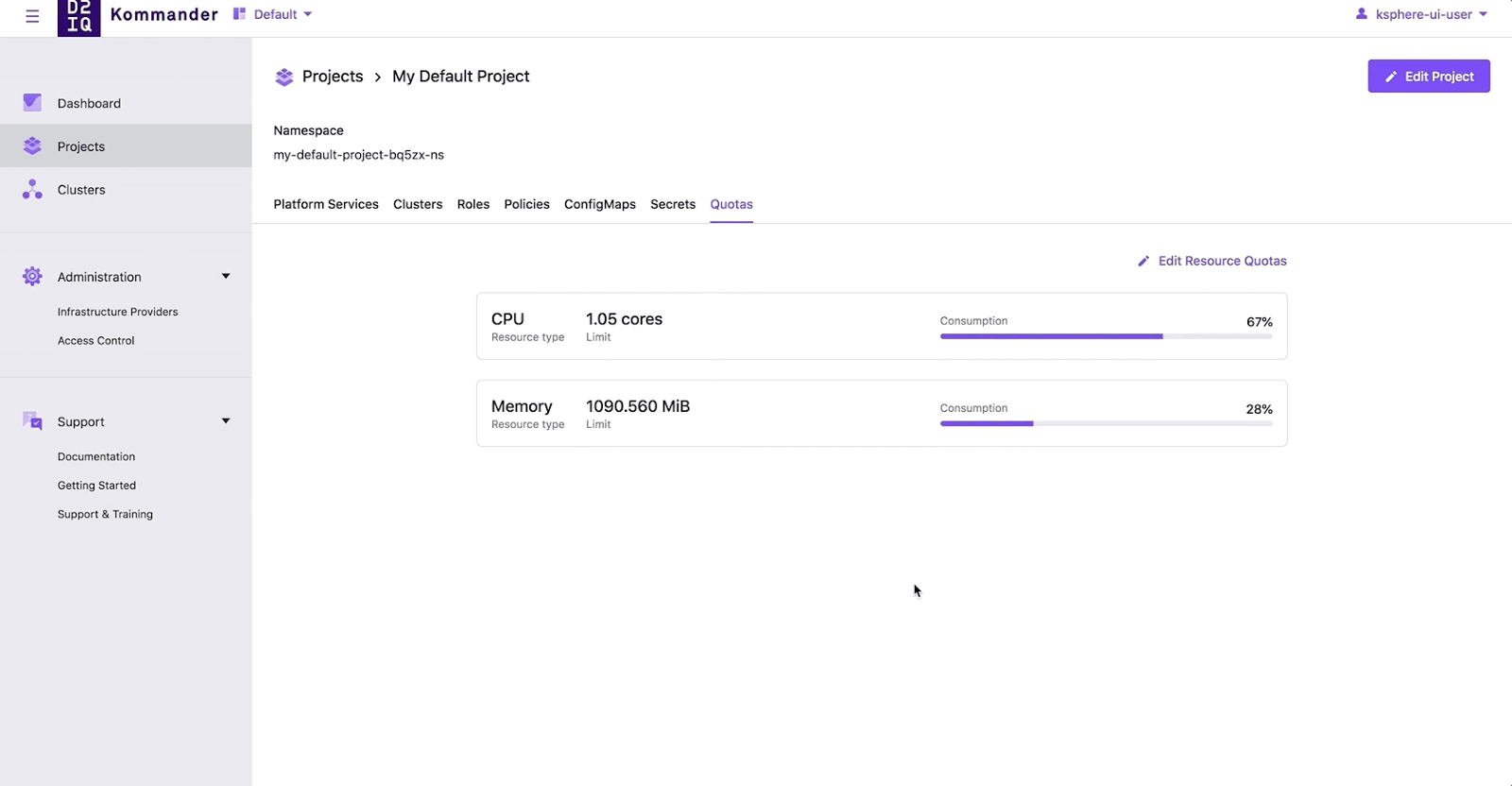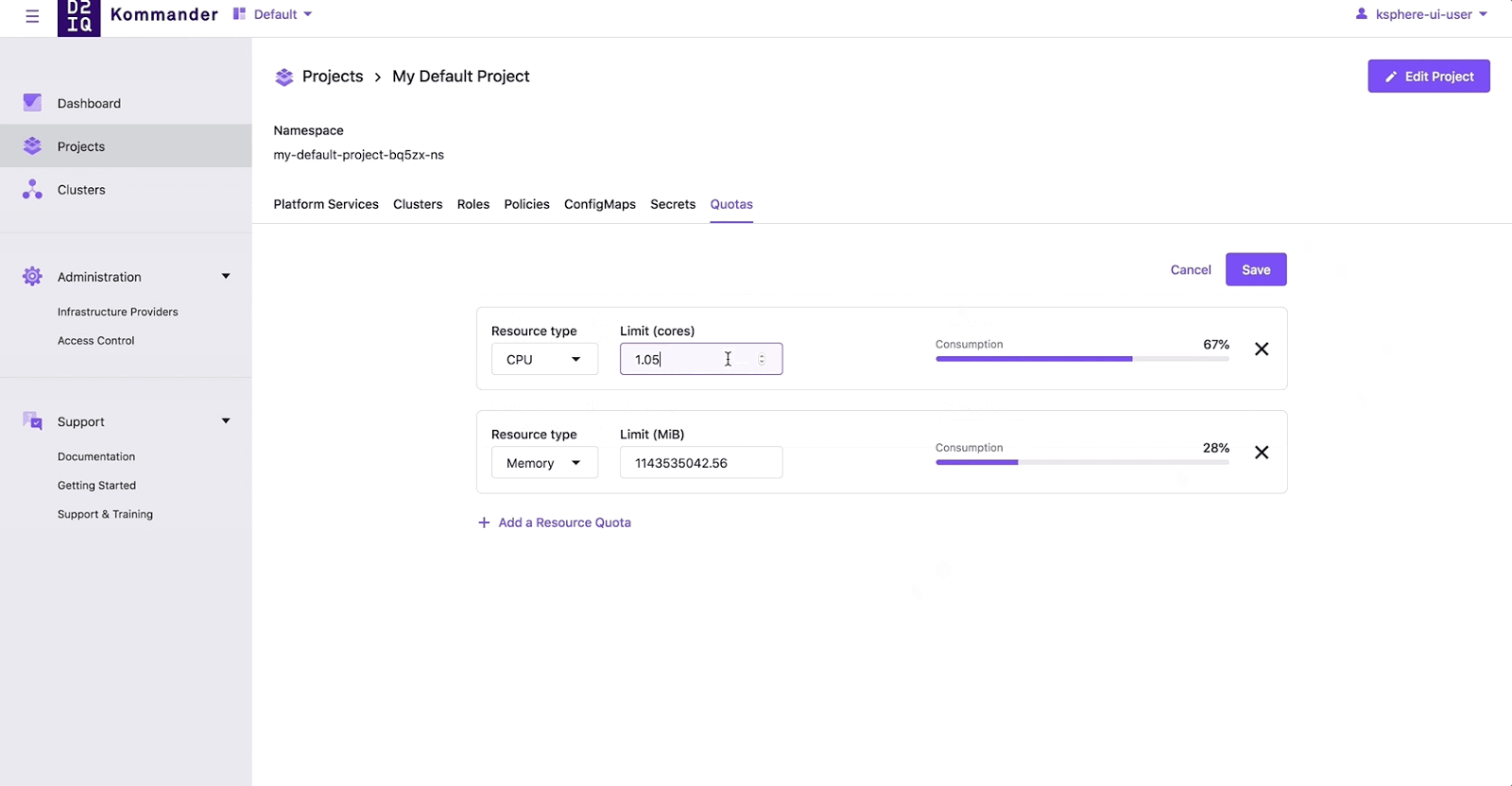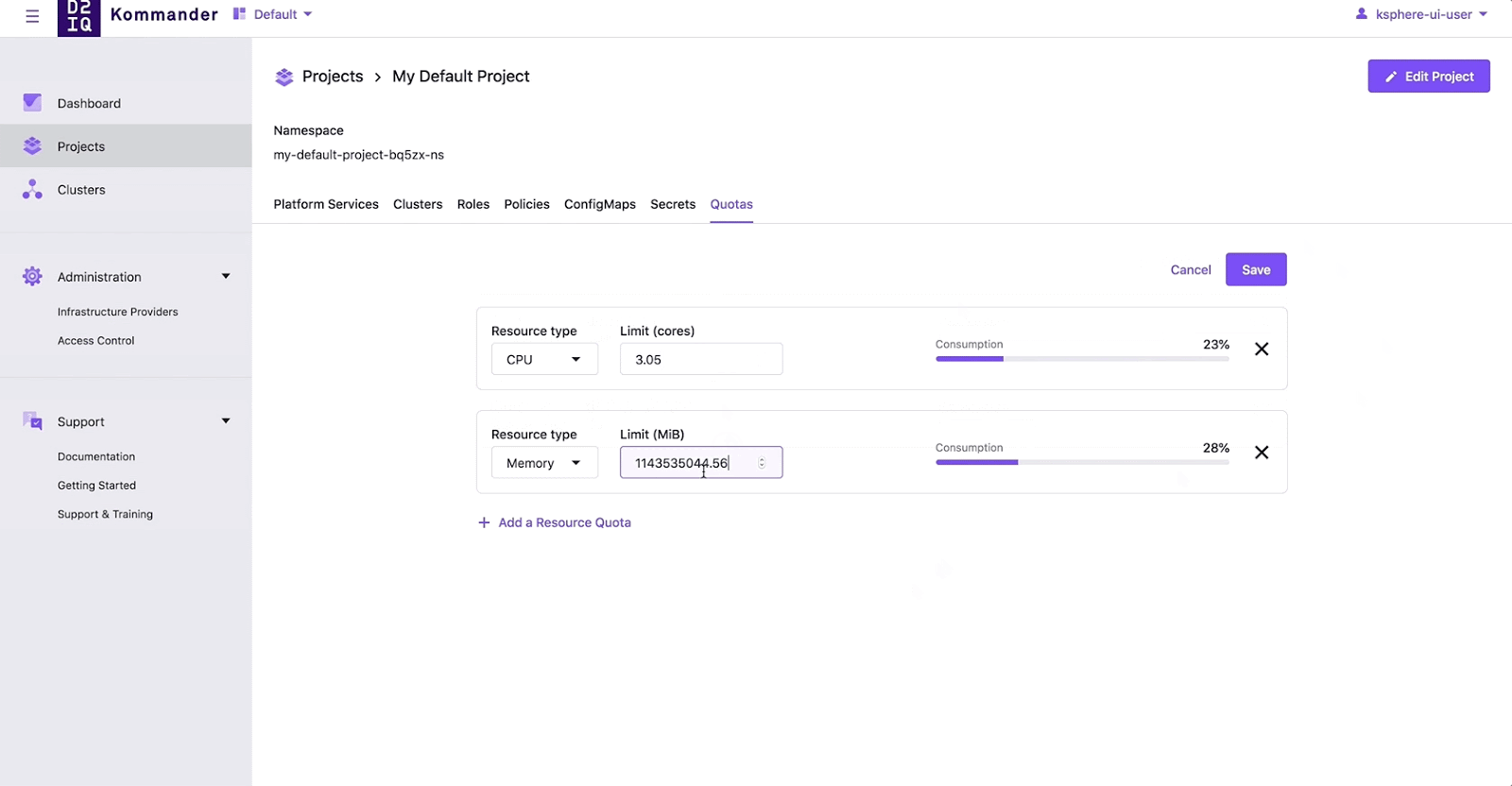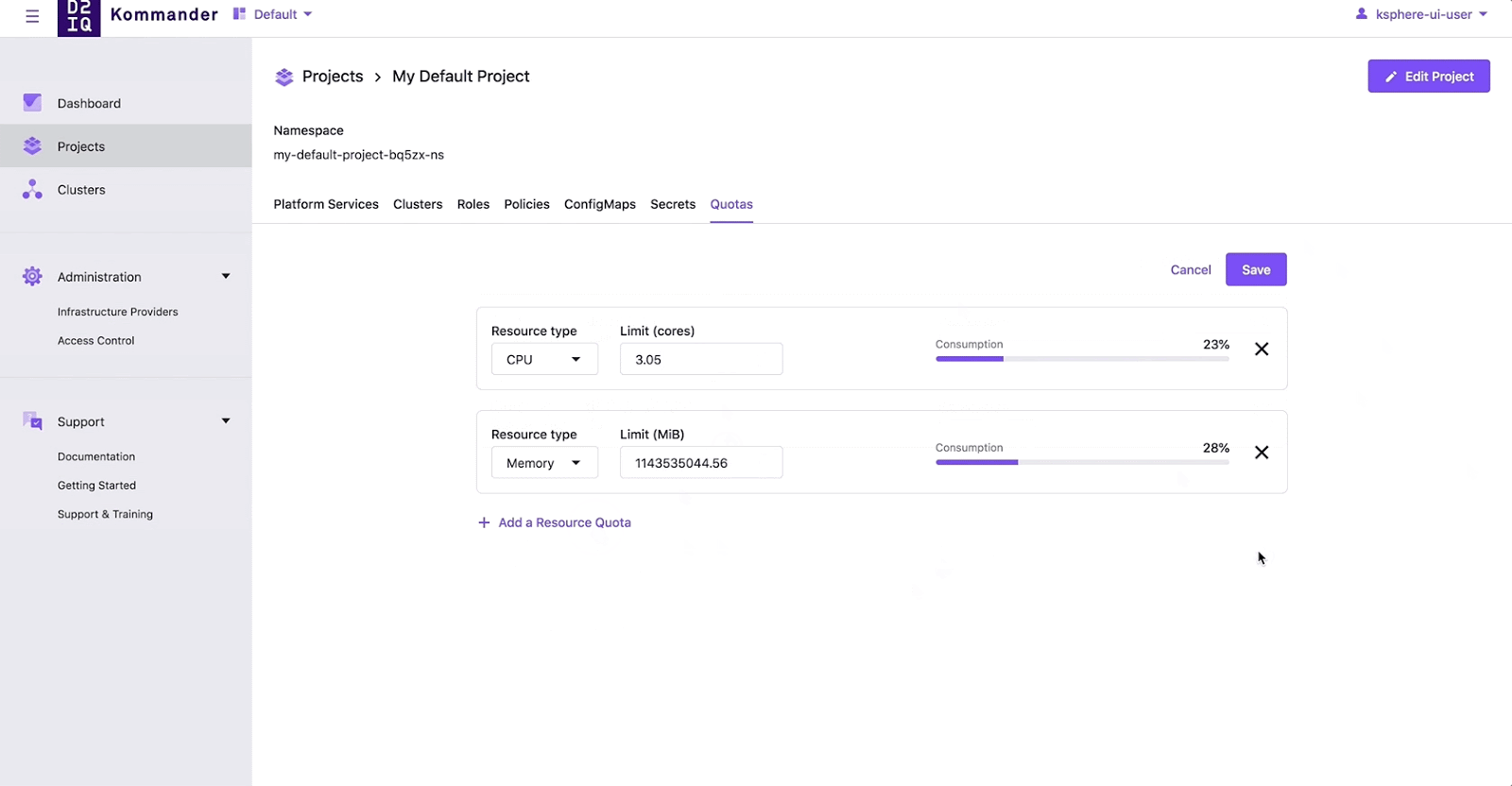
Managing Kubernetes at scale is an increasing—and increasingly important—challenge.
The current best practices for managing workloads on Kubernetes is to have many clusters to fit various administrative or lifecycle needs. This means potentially having a cluster for each team, lifecycle or, for mission-critical services, each production workload. The challenge of managing these clusters is often focused on lifecycle management, but that is only a small part of the picture.
For example, say your organization is running Kafka on 50 clusters and a critical security vulnerability is announced in that service. You will then have to upgrade Kafka across 50 clusters, one-by-painful-one. What about managing secrets, configmaps, and resource quotas? You can see how the growth of permutations of clusters and configurations quickly grows and becomes unmanageable, even with small numbers of clusters, requiring unsustainable levels of manual effort.
At D2iQ, we want to provide our customers with a dead simple method to easily manage configuration, whether it’s for as little as two or as many as 1,000s of Kubernetes clusters. Systems like this also need to handle the eventual turnover of adding new clusters to replace old clusters, scaling and recovering seamlessly through various lifecycle stages.
Kubefed for Kubernetes Fleet Configuration

One of the product religions we adhere to here at D2iQ is that we actively avoid reinventing things. If there is a community open source effort, (“community” being the key word here) we want to adopt it. Even if it doesn’t completely fill our needs 100% of the time, it is easy to fill gaps on community efforts and we don’t want the “standard” proliferation that comes from single vendor open source efforts. When looking for tools that could easily distribute arbitrary resources (workloads, CRDs and configurations), we found one that fit the bill: Kubefed.
Kubefed is one of the earliest Kubernetes projects and was meant to be a tool to enable “Kubernetes federation,” or “Ubernetes,” which would almost treat Kubernetes clusters like Kubernetes treats nodes—orchestrating workloads across clusters and data centers with ease.
The idea that Kubefed would be completely able to orchestrate workloads across data centers has always been a bit of a moonshot, but its fundamental purpose is to use a Kubernetes control plane to distribute arbitrary API resources (workloads, CRDs, quotas, secrets, etc) to the clusters it manages. Kubefed is very good at this.
Adoption of Kubefed allowed us to separate out the tasks of configuration management into two pieces:
- Federation of arbitrary resources: Kubefed has an excellent community with a long, rich history in this problem domain.
- Manifest management (Helm, KUDO, etc): We built a component called Kubeaddons because we identified some needs that the community had not yet fulfilled.
Kommander uses Kubefed as a component to enable Projects, where users can group clusters by label, to configure and maintain application environments across a group of clusters. For example, a line of business or team can group all their clusters in a single Project. Once grouped, a user only needs to deploy their apps (e.g. Kafka), secrets, CRDs, configmaps, resource quota, roles, and policy once. These will get distributed to a namespace (with identical name) in each one of those grouped clusters. Even better, if a user needs to upgrade a configuration or workload, then they also only need to do it on the Project level—the Kubernetes control plane takes care of the reconciliation. What happens if I have a new cluster that is created and put into that cluster? The Kubernetes control plane does what it does best, in conjunction with kubefed, and reconciles the current state to the desired state and configures or deploys workloads to that new cluster.
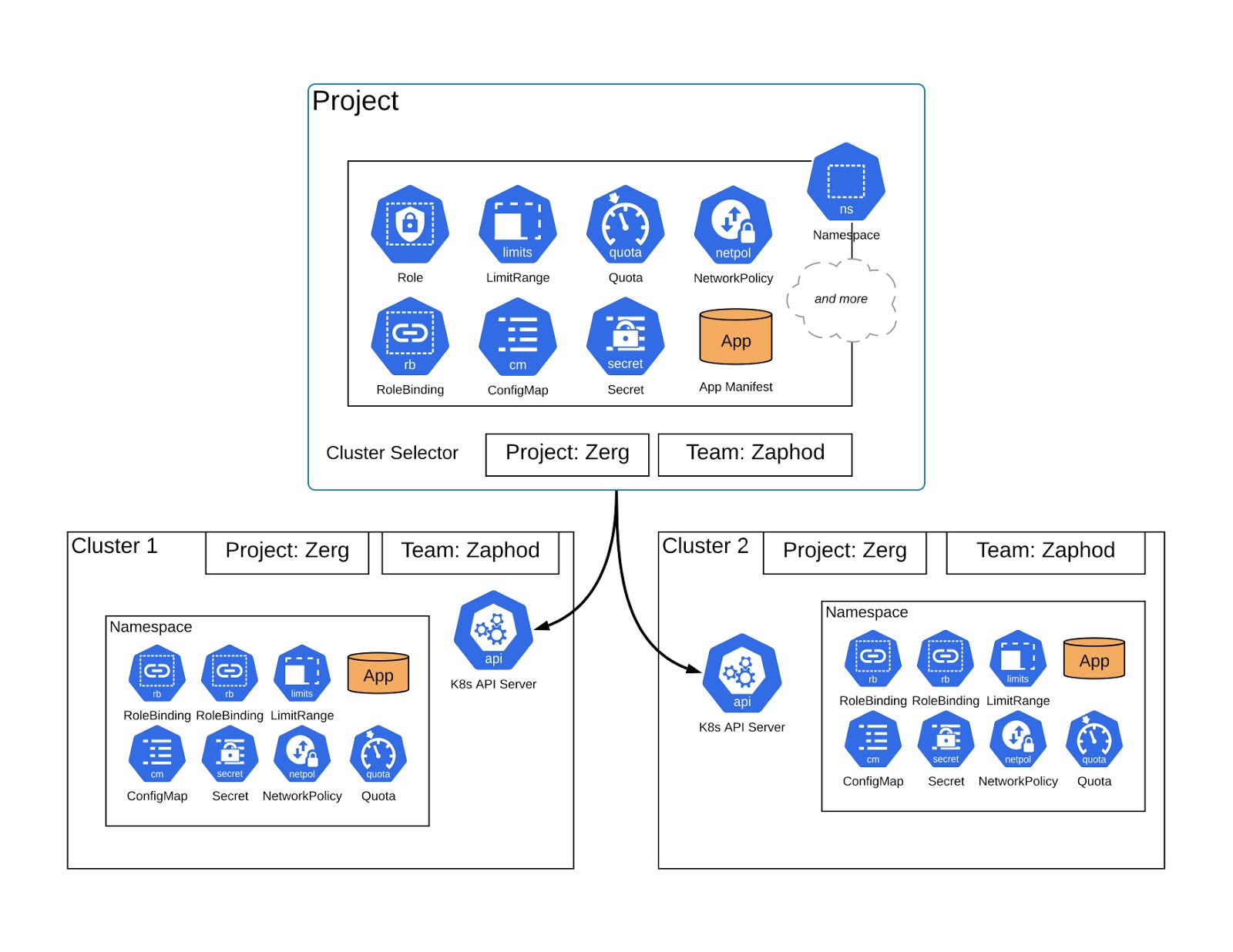
Kommander implements Workspaces to distribute cluster-scoped to an isolated group of clusters, also using kubefed. This scope is mainly for administrative purposes and to enforce various security configurations.
Future of Kubefed
Kubefed has already gone through a couple of versions throughout its history. During the last Kubecon North America conference, the enthusiasm for Kubernetes Federation was tempered compared to the fever pitch of the past, perhaps because of its previous lofty moonshot promises. After the conference, D2iQ stepped into community leadership of Kubefed because we realized how essential it was to help our customers achieve their pragmatic goals.
The plan to improve Kubefed has already been presented to the community. This includes:
- Changing from a push to pull based reconciliation model while still supporting the existing API
- Decentralizing the computation of certain tasks in Kubefed to alleviate the control-plane as a bottle-neck, and improve scalability
- Extending the definition of a federated resource’s status (deployment: running, pending or crashing)
- Creating a notion of “cluster capacity” so that Kubefed knows if a federated resource can be scheduled.
There are a few implementation paths we suggested to the community for its consideration which can be found here. With the support of the community, we look forward to taking Kubefed into its next phase, one that more intelligently understands workloads and its configurations.


