What are the pitfalls of running Java or JVM-based applications in containers? In this article, Jörg Schad and Ken Sipe discuss the challenges and solutions.
The Java Virtual Machine (not even with the Java 9 release) is not fully aware of the isolation mechanisms that containers are built around. This can lead to unexpected behavior between different environments (e.g., test vs production). To avoid this behavior one should consider overriding some default parameters (which are usually set by the memory and processors available on the node) to match the container limits.
One question that we've been hearing a lot recently is "how can I run my Java applications in containers?" Many businesses that rely on Java applications are moving to a containerized microservices architecture. Containers are becoming the preferred method for such deployments because:
Container images allow for easily packaging of an application together with all its dependencies (such as a specific JRE or JDK) into a single package/container. Deployment is much simpler when we are no longer concerned with setting up the right environment (because it is packaged into the container).
Multiple running containers can be isolated from one another using standard Linux kernel features. This post discusses the scope and limitations of this form of isolation.
As containers are simple Linux process groups, they are very quickly deployed (orders of magnitude faster than Virtual Machines). This allows for fast scale-up and scale-down, often an important criteria for microservice based architectures.
This article is structured as follows:
We will first try to understand what containers actually are and how they are build from Linux kernel features. We will then recall some details of how the JVM deals with Memory and CPU. Then, finally, we will bring both parts together and see how the JVM runs in containerized environments and which challenges arise. Of course, we will also discuss how to solve these challenges. The first two sections are mostly intended to provide the prerequisites for the last part, so if you already have deep knowledge about container or JVM internals feel free to skip/skim over the respective section.
Containers
While many people know about containers, how many of us know that much about the underlying concepts, like control groups and namespaces? These are the building blocks for understanding the challenges of running Java in containers.
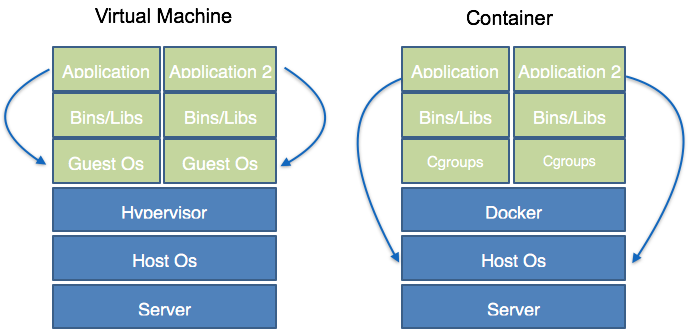
Containers are a powerful and flexible tool to package applications and basically write once, run anywhere, but only up to a certain degree. That's the promise of containers, anyways. To what degree is this promise holding true? Many of us working with Java have heard this promise before: Java claims that you can write an application and run it anywhere. Can these two promises be combined in Docker containers?
On a high level, containers appear like a lightweight virtual machine:
I can get a shell on it (through SSH or otherwise)
It "feels" like a VM:
Dedicated process space
Dedicated network interface
Can install packages
Can run servers
Can be packaged into images
On the other hand, containers are not at all like virtual machines. They are basically just isolated Linux process groups. One could even argue containers are just an artificial concept. This means that all "containers" running on the same host, are process groups running on the same Linux kernel on the host.
Let us look at what that means in more detail and start two container using Docker:
$ docker run ubuntu sleep 1000 &
[1] 47048
$ docker run ubuntu sleep 1000000 &
[2] 47051
Let us quickly check both are running:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f5b9bb7523b1 ubuntu "sleep 1000000" 10 seconds ago Up 8 seconds lucid_heisenberg
b8869675eb5d ubuntu "sleep 1000" 14 seconds ago Up 13 seconds agitated_brattain
Great, both containers are running. So what happens if we look at the processes at the host? Just a warning, if you try this with Docker for Mac, you will not be able to see `sleep` processes, as Docker on Mac will run the actual containers inside a virtual machine (and hence the host the containers are running on is not your Mac, but the virtual machine).
$ ps faux ….
So here we can see both `sleep` processes running as child processes of the cointainerd process. As a result of "just" being process groups on a Linux kernel:
Containers have weaker isolation compared to virtual machines
Containers can run with near-native CPU and IOspeed
Containers launch in around 0.1 second (libcontainer)
Containers have less storage and memory overhead
Memory Isolation
As we have seen earlier, at the core containers are standard Linux processes running a the shared kernel.
But what is the view from inside one of those container? Let us investigate that by starting an interactive shell inside one of the containers using `docker exec` and then look at the visible processes:
$ docker exec -it f5b9bb7523b1 bin/bash
root@5e1cb2fd8fcb:/# ps faux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
From inside the container, we can only see one sleep task as it is isolated from the other containers. So, how do containers manage to provide such isolated views?
There are two Linux kernel features coming to the rescue: cgroups and namespaces. These are pretty much utilized by all container technologies, such as Docker, Mesos Containerizer, or rkt. Mesos has had its own containerizer from the early days and we use also cgroups and namespaces internally. As a result, Mesos can even utilize Docker images without having to rely on the Docker daemon.
Namespaces are basically used for providing different isolated views of the system. So each container can see its own view on different namepaces like process IDs, on network IDs, or user IDs. For example, in different containers we can have different processes with ID 1 which is usually "init" process having some special properties.
While namespaces provide an isolated view, control groups (cgroups for short) are what isolates access to resources. So cgroups can be used for either limiting access to resources (for example, a process group can only use a maximum of 2GB of memory) or accounting (for example, keeping track how many CPU cycles a certain process group consumed over the last minute). We're examine this in more detail later.
Namespaces
As mentioned before, every container has its own view of the system and namespaces are used to provide these views for the following resources (amongst others):
pid (processes)
net (network interfaces, routing…)
ipc (System V IPC)
mnt (mount points, filesystems)
uts (hostname)
user (UIDs)
Consider, for example, the process ID namespace and our previous example of running two Docker containers. From the host operating system we could see the 13347 and 13422 as process IDs for the sleep processes:
But from inside the container it looks slightly different:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
So from inside the container the `sleep 1000000` process has the process id 1 (in contrast to 13422 on the host). This is because the container runs in its own namespace and hence has its own view on process ids.
Control groups
We're diving a little deeper into control groups here, and to avoid any potential confusion, we're talking about cgroups v1, not cgroups v2. As mentioned previously, control groups can be used for both limiting access and also for accounting purposes. As everything in Linux or Unix, it's just like a hierarchical folder which can be viewed as a tree. Here's what such structure could look like:
Note that:
Each subsystem (memory, CPU…) has a hierarchy (tree)
Each process belongs to exactly 1 node in each hierarchy
Each hierarchy starts with 1 node (the root)
Each node = group of processes (sharing the same resources)
The interesting part is that one can set limits for each node in this tree. Consider for example the memory subsystem:
Each group can have hard and soft limits
Soft limits are not enforced (i.e., only trigger a warning in the log), which may or may not be useful, for example for monitoring or trying to determine the optimal memory limit for a certain application.
Hard limits will trigger a per-group OOM killer. This often requires some changed mindset for Java developers, as they are used to receiving an `OutOfMemoryError` which they can react to accordingly. But the in case of containers with a hard memory limit, the entire container will simply be killed without warning.
When using Docker we can set a hard limit of 128MB for our containers as follows:
$ docker run -it --rm -m 128m fedora bash
CPU Isolation
After having looked at memory isolation, let us consider CPU isolation next. Here, we have two main choices: CPU shares and CPU sets. There's a difference between them, which will be relevant.
CPU shares
CPU shares are the default CPU isolation and basically provide a priority weighting across all all cpu cycles across all cores.
The the default weight of any process is 1024, so if we start a container as follows docker run -it --rm -c 512 stress it will receive less CPU cycles than a default process/container.
But how many cycles exactly? That depends on the overall set of processes running at that node. Let us consider two cgroups A and B.
sudo cgcreate -g cpu:A
sudo cgcreate -g cpu:B
cgroup A: sudo cgset -r cpu.shares=768 A 75%
cgroup B: sudo cgset -r cpu.shares=256 B 25%
Cgroups A has CPU shares of 768 and the other has 256. That means that the CPU shares assume that if nothing else is running on the system, cgroup A is going to receive 75% of the CPU shares and cgroup B will receive the remaining 25%.
If we remove cgroup a, then cgroup b would end up receiving 100% of CPU shares.
Note that you can also use CFS isolation for more strict, less optimistic isolation guarantees, but we would refer to this blog post for details.
CPU Sets
CPU sets are slightly different.They limit a container's processes to specific CPU(s). This is mostly used to avoid processes bouncing between CPUs, but is also relevant for NUMA systems where different CPU have fast access to different memory regions (and hence you want your container to only utilize the CPU with fast access to the same memory region).
We can use cpu sets with Docker as follows:
docker run -it -cpuset=0,4,6 stress
This means we are pinning the containers to CPUs 0, 4, and 6.
Let's talk Java
Let's review some details of Java.
First of all, Java consists of several parts. It's the Java language, the Java specifications, and the Java runtime. Let's focus on the Java runtime, since that actually runs inside our containers.
JVM's memory footprint
So, what contributes to the JVM memory footprint? Most of us who have run a Java application know how to set the maximum heap space. But there's actually a lot more contributing to the memory footprint:
Native JRE
Perm / metaspace
JIT bytecode
JNI
NIO
Threads
This is a lot that needs to be kept in mind when we want to set memory limits with Docker containers. And also setting the container memory limit to the maximum heap space, might not be sufficient...
JVM and CPUs
Let's take a short look at how the JVM adjusts to the number of processors/cores available on the node it is running on. There are actually a number of parameters which by default are initialized based on core count:
The number of of JIT compiler threads
The number of Garbage Collection threads
The number of threads in the common fork-join pool
And more
JVM meets Containers
Finally, we have all the tools available and all the background in place and we're ready to bring it all together!
Let's assume that we have finished developing our JVM-based application, and packaged it into a Docker image to test it locally on our notebook. All works great, so we deploy 10 instances of that container onto our production cluster. All of a sudden the application is throttling and not achieving the same performance that we had seen on our test system. This doesn't make any sense because our production system is a high-performance system with 64 cores and our test system was just a notebook.
What has happened? In order to allow multiple containers to run isolated side-by-side, we have specified the JVM container to be limited to one cpu (or the equivalent ratio in CPU shares). Unfortunately, the JVM detects the overall number of cores on that node (64) and uses that value to initialize the number of default threads. As started 10 instances, we end up with:
10 * 64 Jit Compiler Threads
10 * 64 Garbage Collection threads
10 * 64 ….
Our application, being limited in the number of CPU cycles it can use, is mostly dealing with switching between different threads and cannot get any actual work done.
All of a sudden, the promise of containers to "package once, run anywhere', seems to have been violated.
Let's compare containers and virtual machines, paying particular attention to where in each case the JVM collects its information (i.e., # cores, memory, …):
In JDK 7/8, it gets the core count resources from sysconf. That means that whenever I run it in a container, I am going to get the total number number of processors available on the system, or in case of virtual machines, on the virtual system.
The same is true for default memory limits. The JVM looks at the host overall memory and uses that to set its defaults.
The result is that the JVM ignores cgroups and that causes the performance problems we have seen above.
If you have paid attention you might wonder, why are namespaces failing to come to the rescue. After all, we said that they create container specific views of resources. Unfortunately, there is no CPU or memory namespace (and remember, namespaces are not providing the same isolation as a VM), so a simple `less /proc/meminfo` from inside the container will still show you the overall memory on the host, not on the container.
But Java 9 supports containers...
With (Open)JDK 9, that changed. Java now supports Docker CPU and memory limits. Let's look at what `support` actually means.
Memory
The JVM will now consider cgroups memory limits if the following flags are specified:
-XX:+UseCGroupMemoryLimitForHeap
-XX:+UnlockExperimentalVMOptions
In that case the Max Heap space will automatically (if not overwritten) be set to the limit specified by the cgroup. As we discussed earlier, the JVM is using memory besides the heap, so this will not prevent all out of memory scenarios where the cgroups oom killer will kill the container. But, especially giving that the garbage collector will become more aggressive as the heap fills up, this is already a great improvement.
CPU
The JVM will automatically detect CPU sets and, if set, use the number of CPUs specified for initializing the default values discussed earlier.
Unfortunately, most users (and especially container orchestrators such as DC/OS) use CPU shares as the default CPU isolation. And with CPU shares you will still end up with the incorrect value for default parameters.
So what should you do?
Do the challenges above mean that you shouldn't deploy JVM-based applications in containers? No!
We would still encourage you to do so because it has many benefits, such as isolation of Metaspace.
The most important thing is to simply be aware of the issues described above and consider whether they apply to your environment.
If not, great.
If so, then you should consider overwriting the default JVM startup parameters for memory and CPU usage (discussed above) according to your specific cgroup limits.
Furthermore, OpenJDK 10 will also improve support container drastically. It will for example include support for CPU shares so your JVM-based containers will also work nicely with modern container orchestration systems like Mesos and DC/OS.
This post is adapted from a session presented at Codemotion 2017 and was originally posted on jaxenter.