Dec 13, 2016
Michael Hausenblas
D2iQ

2 min read
Would you like to learn how to do stream processing with Apache Kafka on DC/OS? If so, read on!
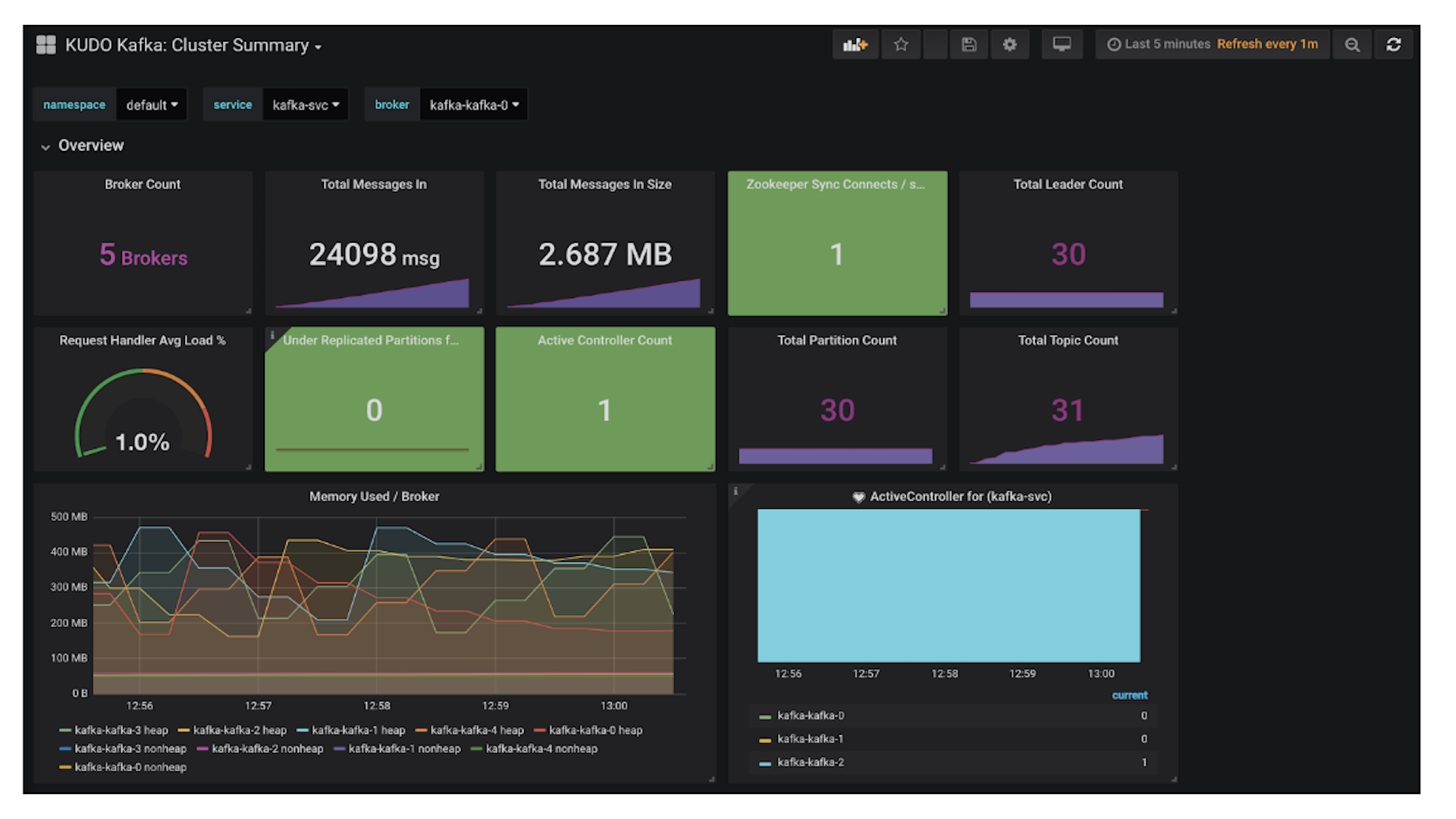
We put together a demo around financial transaction processing demo where we show how to process and visualize a stream of high-volume financial transactions in real time. We show how to aggregate data about recent transactions from multiple locations as well as being able to spot fraudulent transactions, such as money laundering.
System architecture.
In our demo, Kafka plays the central role: it is used as message queue that retains all the financial transactions, ready to be consumed downstream. There are three stateless components, all microservices written in Go:
- The generator continuously produces (random) financial transactions in (simulated) five different cities (organized in Kafka topics) and pushes them into Kafka.
- One consumer reads the most recent transactions out of Kafka and ingests it into InfluxDB which is further connected to Grafana, showing a breakdown of average and total transaction volume per city for the past hour.
- Another consumer of the transactions stored in Kafka is the money laundering detector, a command line tool that alerts when the aggregate transaction volume from a source to a target account exceeds a configurable treshold. The idea behind this is to highlight potential money laundering attempts to a human operator who then has to verify manually if a fraudulent transaction has been taken place.
There is a single command option available that allows you to set up the whole demo in less than 10 min as well as a manual install method, if you want to learn more about how to install Kafka, InfluxDB and Grafana with DC/OS. After completed installation, the following services will be running in your DC/OS cluster, using overall 6 CPU cores and 6 GB of RAM:
All fintrans services installed and running.
Once set up you can view (and toy around with) the transactions in Grafana:

Most recent transaction aggregates in Grafana.
Further you can monitor (potential) money laundering activities via the laundering detector command line tool:
$ dcos task log --follow fintrans_laundering-detector.5e97c906-bd5e-11e6-be40-fecdab8d68a1 POTENTIAL MONEY LAUNDERING: 516 -> 482 totalling 8644 now POTENTIAL MONEY LAUNDERING: 246 -> 308 totalling 9336 now POTENTIAL MONEY LAUNDERING: 856 -> 804 totalling 8994 now POTENTIAL MONEY LAUNDERING: 233 -> 954 totalling 8710 now POTENTIAL MONEY LAUNDERING: 318 -> 273 totalling 8883 now POTENTIAL MONEY LAUNDERING: 303 -> 24 totalling 8431 now ^CUser interrupted command with Ctrl-C
In this demo we used Kafka to handle the storage and routing of the financial transactions and provided two exemplary consumers. While the consumers are deliberately kept simple, you can use them as a basis for a real world implementation. Modulo service health checking and monitoring, the setup is production-ready: Kafka takes care of the scaling issues around data capturing and ingestion and the System Marathon the generator and the two consumers are supervised and can be scaled as needed.
If you want to try out the demo for yourself now, all you need is a DC/OS cluster and then head over to GitHub and follow the instructions there.