






Jul 11, 2017
Amr Abdelrazik
D2iQ

6 min read
Businesses today are looking for ways to better engage customers, improve operational decision-making, and capture new value streams. To do this IT organizations are tasked with building modern data rich applications, which means adopting an ever growing list of platform services and technologies. Containers, fast data, and machine learning are just a few examples of these underlying technologies. Adopting each of these technologies in production on existing infrastructure solutions is non-trivial and time consuming work, making it harder and harder for business to keep up and remain competitive.
Today's Enterprise Architecture Stakeholders
One reason adopting new technologies is difficult is that it needs to meet the expectations of business, application, and operations/infrastructure teams. Each of these stakeholders have key responsibilities, each with valid concerns around speed, flexibility, and costs.
App Development and
DevOps Teams | Operations and
Infrastructure Teams | Data Engineer and
Scientist Teams
Accelerating microservices initiatives
Moving to Docker containers
Building scalable, performant continuous integration continuous development systems | Maintaining uptime, security & compliance
Delivering platform services faster
Managing Cost/reducing risk of cloud lock-in | Building reliable, efficient fast data services
Easily introduce machine learning and deep learning
Easily Scaling up and down to accommodate data processing demands
To meet these challenges, IT organizations need to develop three inter-related capabilities, and select an appropriate infrastructure that can service those capabilities.
Developer Agility: Helping developers build and ship faster
Rolling out new services quickly means enterprises need to change how they build and operate software. Rolling out software faster increases customer satisfaction and retention, improves employee morale, and allows the business to quickly respond to competitive threats.
Application development teams embarking on many initiatives to increase developer agility, such as shifting from monolithic apps to microservices to improve speed and agility, or migrating those applications to Docker containers to increases application portability and tool flexibility. Supporting the above initiatives with reliable CI/CD toolchain enables development teams to release faster without compromising quality.
The challenge for IT organizations is how to choose the right tool chain that integrates in an efficient, scalable and reliable manner, while coexisting and supporting existing legacy applications that may benefit from some of those capabilities.
Data Agility: Enabling real-time, actionable insights from large pools of data
Modern enterprise applications need to serve many users concurrently and process data at scale - often in real-time. One example is giving users highly personalized experiences (e.g., the Uber rider UI, Twitter's feed, or Netflix's browsing experience), which entails processing real-time data to anticipate behavior or provide real-time recommendations.
To meet performance, availability and scale requirements for modern, data-rich applications, organizations have found that they need to move to distributed computing technologies. One emerging approach is the SMACK stack.
Example fast data pipeline using the SMACK stack
Distributed computing is critical for two main reasons. First, the large volume of data processed cannot be performed on any single computer. Second, having a potential single point of failure is unacceptable. In an era when decisions are made in real-time, loss of access to business data is a financial disaster, and end users won't tolerate even small amounts of downtime.
The challenge becomes how can businesses effectively run these data services in a fault-tolerant, distributed manner. Most data services have been developed in isolation from one another and never designed to run on shared infrastructure. This means that deploying each data service is complex and time consuming, operating data services is manual and subject to human error, and infrastructure is siloed with high potential peaks but very low average utilization.
Operational Agility: Simplifying the introduction and operation of new services on any cloud
Operational teams are stretched thin trying to introduce, manage, and support a plethora of new technologies like containers and distributed data services, while still managing legacy systems across on-premise and cloud infrastructure (many times with capped budgets and headcount).
The reason operations team are facing these challenges is that the Infrastructure-as-a-Service (IaaS) model that served the client-server era well is proving inadequate for modern, distributed applications. VM-based infrastructure fails to meet these new application needs, for two main reasons. First is that running microservices and distributed data services in VMs means proliferation of high-overhead VMs, making ineffective use of computing capacity and overwhelming administrators. Second, modern distributed applications are highly dynamic, so manually deploying, scaling and recovering from failure is very complex and labor intensive, even with the use of configuration automation tools. While some organizations have addressed these issues by building on top of public cloud platforms, moving entirely to a public cloud provider has also resulted in unpredictable costs, even greater fragmentation, and loss of control. In addition, applications and operational tools are being locked into a specific cloud provider, so the need for hybrid cloud is starting to be more pressing.
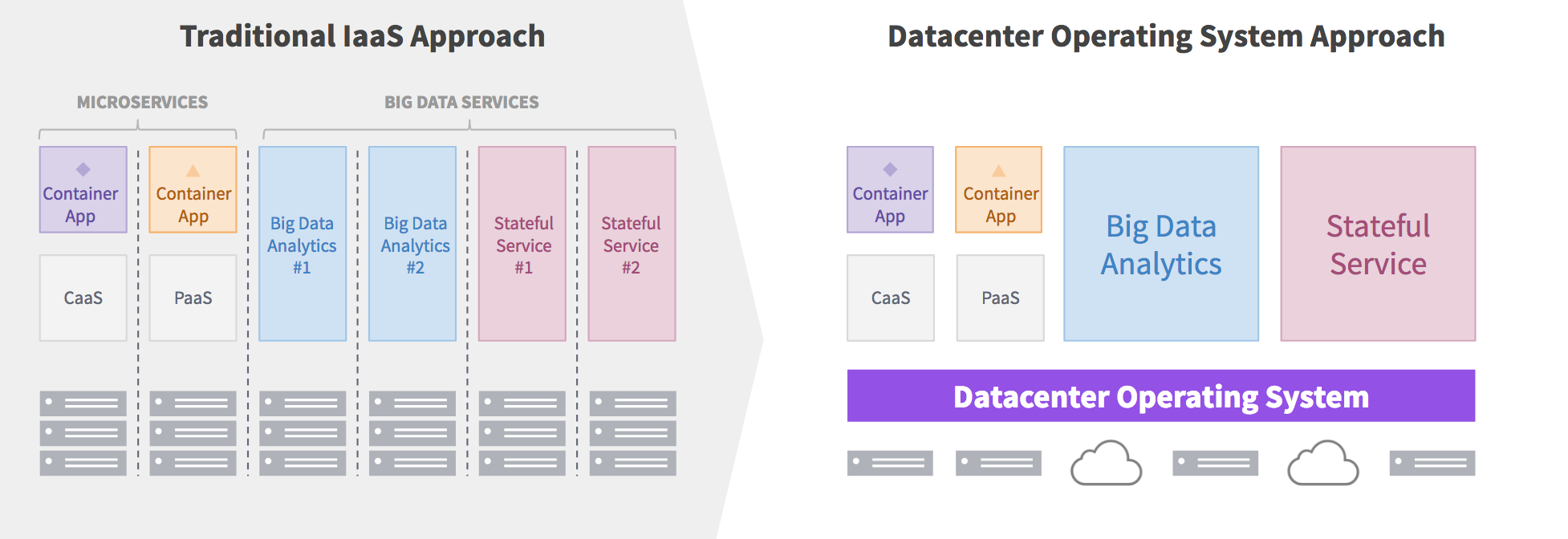
A New Approach to Infrastructure
Companies like Google, Facebook, and Twitter were the first companies to face web scale and embrace microservices. These innovators introduced and pioneered the use of the cluster manager or datacenter-level manager such as Borg and Apache Mesos running on commodity server hardware, successfully solving these challenges with tremendous flexibility, control, and cost-efficiency.
Datacenter managers provide two main benefits: (1) they abstract datacenter resources into one giant resource pool, making it easy to deploy, scale and share resources across any number of workloads.; and (2) they automate many of the operational tasks for distributed systems such as monitoring, fault detection and recovery without user intervention, increasing uptime and reducing operational overhead.
While the systems for Google and Facebook were developed internally on proprietary technology, Twitter made its transition to modernize its infrastructure using open source software out of Berkeley's R&D lab, Apache Mesos. Apache Mesos was released in 2010 to build a technology that works on any infrastructure, not just in Google's proprietary data centers like Google's Borg. In addition to being a cluster manager/datacenter manager, Mesos's breakthrough was the introduction was application-aware scheduling, which greatly simplified the adoption of new technologies on top of Mesos.
Application-aware scheduling with Mesos automates many of the application-specific operational logic such as deployment, scaling, upgrade which simplifies operation and reduces human error for new datacenter services. Mesos modular architecture and resource isolation capabilities increases efficiency through workload pooling, accelerate technology adoption, and provides a resilient platform to support production workloads from small to web-scale applications.
Apache Mesos was critical to Twitter's success on several fronts. First, Mesos allowed Twitter to simplify operations, increasing uptime and improving utilization. Second, Mesos saved Twitter millions of dollars in infrastructure cost while allowing the company to rapidly scale and accommodate unprecedented growth. Third, Mesos enabled application development teams at Twitter to ship software faster and be more innovative by moving to microservices and an early version of containers (cgroups). Lastly, and perhaps most importantly, Mesos also enabled Twitter to manage massive amounts of real-time data.
The challenges of Google, Facebook, and Twitter yesterday have become mainstream enterprise challenges today. To stay competitive, and address the needs of the business, development, and operations, many organizations are transitioning to a next-generation enterprise architecture in the same manner that Twitter did nearly a decade ago. The good news is there is a number of emerging open source tools and technologies such as Docker containers and Mesosphere DC/OS (which is powered by Apache Mesos) that help enterprises accelerate the adoption of new technologies and meet the requirements for developers, data scientists and operators.


