Oct 04, 2017
Susan Huynh
D2iQ

5 min read
Overview
Data pipelines are important architectural components of the fast data infrastructures that allow business leaders to make real-time data-driven decisions. Data pipelines, the combination of datasets and the processing engines that act on those datasets, are the backbone of many of today's hot technologies such as IoT, real-time recommendation engines, and fraud detection.
Data pipelines rely on multiple tightly-coupled technologies in order to be successful. Building a data pipeline involves integrating varied technologies such as distributed analytics engines (Apache Spark), distributed message queues (Apache Kafka), and distributed storage systems (Apache Cassandra). However, many organizations struggle to build and maintain data pipelines because they are exceedingly complex they are comprised of multiple components that require careful operation and administration to obtain the maximum value and avoid data loss. Moreover, these technologies that make up a data pipeline are typically deployed in silos, which makes them inherently inefficient and complex to scale and maintain.
Large-scale web organizations pioneered the use of a data center cluster managers such as Apaches Mesos to efficiently build and maintain complex distributed systems. Mesosphere DC/OS, powered by Apache Mesos, helps data engineers and DevOps teams simplify the deployment and operations of data pipelines on any infrastructure.
This article will describe how to deploy a data pipeline in under 10 minutes with DC/OS.
Data Pipelines
A typical data pipeline consists of multiple components:
- A data source, such as a web service, which generates events or log files
- Data storage, such as a distributed database like Cassandra, or a distributed message bus like Kafka
- An analytics component, such as Spark
Deploying Data Pipelines with DC/OS
Data pipelines can be difficult to deploy and operate because they are built on varied components. For a web service, the solution may be to use containers, such as Mesos or Docker. Distributed systems such as Cassandra, Kafka, and Spark also need to be configured and deployed across nodes in a cluster. An additional layer of coordination is necessary and this is where DC/OS comes in. DC/OS simplifies the deployment of the entire data pipeline from containers to distributed storage to analytics components.
Data Pipeline Example: Tweeter
In the data pipeline that we will deploy in this example, there is web app called "Tweeter", a Twitter clone, that sends incoming tweets to Cassandra and Kafka. Data is streamed into the Zeppelin analytics notebook and analyzed in Spark. On the frontend, the MarathonLB load balancer handles incoming requests, and a docker based microservice called "PostTweets" continuously pumps tweets into the system.
Prerequisites: DC/OS Cluster, Config Files
DC/OS Cluster
Before deploying a data pipeline, first spin up a DC/OS cluster. This can be done in the cloud or on-premises, following these instructions. In the following example, a 6-node (5 private, 1 public) DC/OS cluster runs in AWS.
Config Files
To obtain the example configuration files, clone this GitHub repo: https://github.com/mesosphere/tweeter.
Step 1: Deploy Cassandra, Kafka, Zeppelin / Spark
(1) To deploy Cassandra, go to the Universe -> Packages tab within the DC/OS UI. Find "cassandra" and click "Install Package":
(2) Click "Install Package" to select the default configuration. This will deploy a 3-node Cassandra cluster within the DC/OS cluster. It is also possible to customize the configuration with "Advanced Installation".
(3) To deploy Kafka, search for the "kafka" package and install it in the same manner. This will deploy a Kafka cluster with 3 brokers within the DC/OS cluster.
(4) Deploy Zeppelin / Spark by searching for and installing the "zeppelin" package. This package will automatically pull in Spark as the notebook's backend.
Step 2: Deploy a Web App from a Docker Image
(1) To deploy the example web app, simply navigate to the Services -> Services tab and click the "+" in the upper-right corner.
(2) Select "JSON Configuration" and replace the template configuration with the one in "tweeter.json", from the GitHub repo you've already cloned:
(3) Add one line near the bottom of the configuration with the public slave DNS address, found in AWS Stack Details (AWS -> CloudFormation -> Stacks -> Stack Details -> Outputs):
"HAPROXY_0_VHOST": "<public slave DNS address>":
(4) Finally, click "Review and Run". This will deploy 3 instances of Tweeter.
Step 3: Deploy MarathonLB and PostTweets
(1) In Universe -> Packages tab, search for and install "marathon-lb".
(2) In the Services -> Services tab, click the "+" in the upper-right corner. Select "JSON Configuration" and replace the template with the one from "post-tweets.json", from the GitHub repo. Click "Review and Run".
To check the deployment status, view the Services -> Services tab. After a few minutes, all the services will reach the "Running" state. The deployment is complete!
View the Example Web App
In a web browser, navigate to the public slave DNS address found in Step 2. In the left column of the web app, you can post a tweet. In the right column, you can see the Shakespearean tweets that are being posted automatically by the bot.
View the Analytics Notebook
Navigate back to the Services -> Services tab, mouseover Zeppelin, and click on the link icon that appears. This will bring up the Zeppelin notebook.
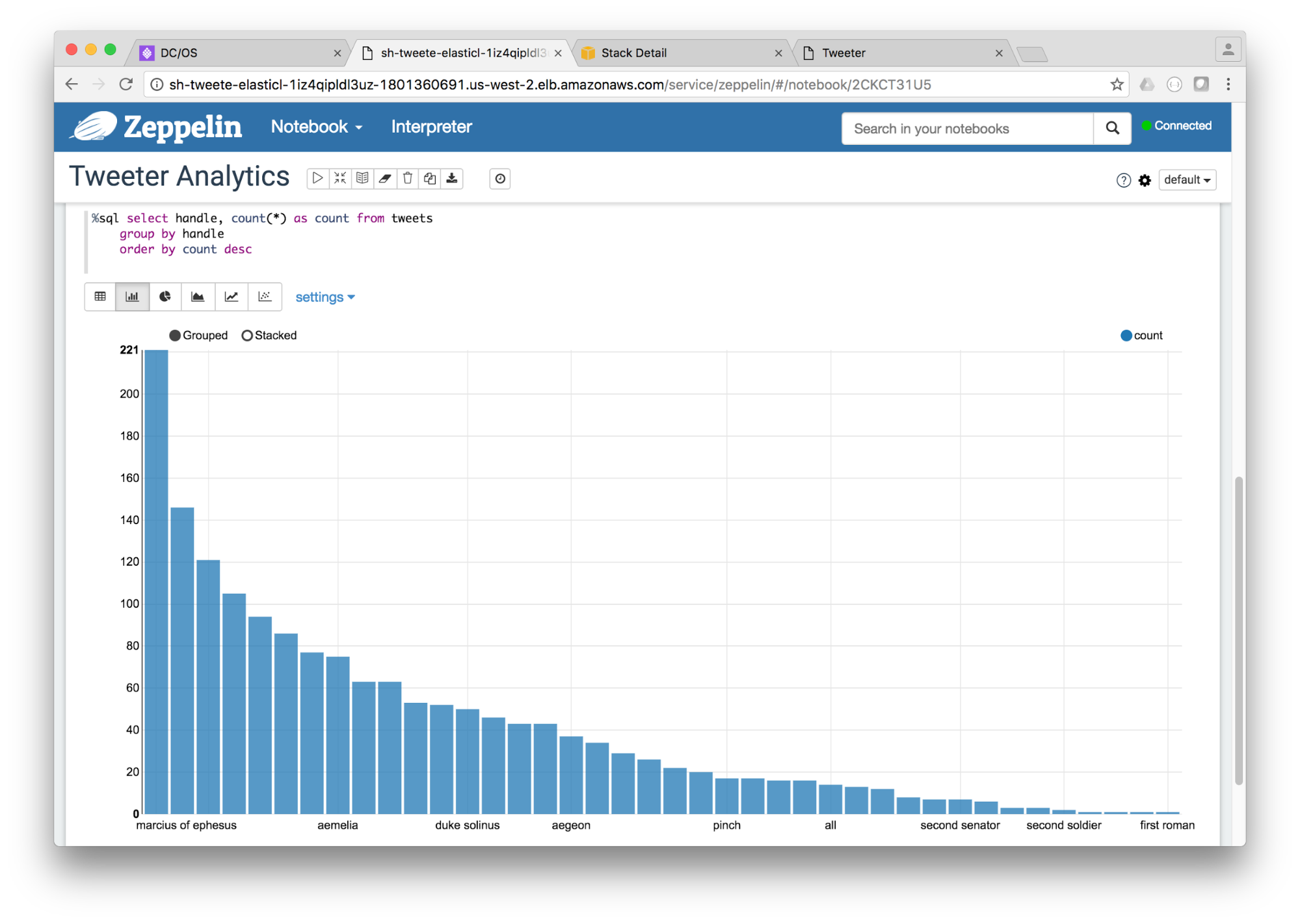
View an example note by clicking "Import Note" and uploading "tweeter-analytics.json", from the GitHub Repo. Then click "Tweeter Analytics". In each section of code, click the "play" button in the upper-right corner to run it. The code will start a Spark Streaming job that analyzes the tweets streaming in from Kafka.
The plot at the bottom of the page shows the top tweeters for the most recent time window.
Recap
Data pipelines consist of complex components such as Kafka, Cassandra, and Spark. DC/OS is a cluster platform that simplifies the deployment and operation of data pipelines. This article shows how to deploy of a data pipeline on a 6-node DC/OS cluster in under 10 minutes. To learn more about DC/OS, visit https://dcos.io/.