





It may surprise you to learn that container technology isn’t new. There are valuable lessons about the future found in its origins.

Oct 11, 2017
D2iQ
D2iQ
8 min read
Florian Leibert, CEO of Mesosphere, recently sat down with Chuck McManis to talk about the challenges he faced developing early distributed systems, the origins of container technology, and the future of computing. If you're on Hacker News, you probably already know Chuck, who is active under his handle, ChuckMcM. This fascinating conversation delves into the early problems Chuck and his teams had to solve when building distributed systems, the lessons they learned, and how they've shaped the present - and probably the future of computing.
Finding the Mechanism Within the Mechanism
Florian Leibert (FL): Hi Chuck, can you give us a background of your engineering career, which is as long as it is impressive. You've really worked in the lower layers of the stack for a very long time, and maybe you can just tell us a little bit about that.
Chuck McManis (CM): I came to the Bay Area in the mid '80s and I went to work for Intel. Then I was recruited out of Intel by a startup called Sun Microsystems. I joined in '86, the day after they went public, in the kernel group. It was a very fun place to be, with a lot of smart people, and a lot of people a lot smarter than I was, so I could learn from day-to-day there. We were working very closely with Berkeley on the BSD distribution of Unix. I was part of the Basic Open Network Computing (BONC) group that was doing networking for the kernel. We had just come up with a distributed file system format called Network File System, and were implementing remote procedure calls. The explosion of networking was very exciting. Sun was bringing its entire company onto a network and we might have had over 1,500 machines. It was a huge number, impossible to recreate elsewhere, but today it would be trivial.
This was all new ground, and we started running into complications when we built these systems and distributed them, and how we made that possible. Kernel programming was exciting to me because there was no room for error. Then I discovered the most exciting role of all, network programmer. If the network programmer makes a mistake in their code, they could bring the entire network down and crash 1,500 kernels. I was drawn to that level of complexity because I've always enjoyed solving really complex problems and finding the mechanism within the mechanism. I designed a very complicated service called NIS+, the first service that didn't exist on a single machine. It was actually a collection of machines, presenting as a single service.
We ran into a lot of problems that plague distributed systems even today, about naming, time synchronization, logging, and making new transactions. This was around the time that Leslie Lamport published a groundbreaking paper on the Byzantine general problem that influenced us. I re-read that paper a little while ago, because it was on Hacker News, and I think it still does a great job of providing the core, basic understanding you have to have to build distributed systems. Distributed systems evolved very rapidly in the late '80s and early '90s. There was a tremendous effort to make procedure calls go across machines and to make them transparent so that a program could be written with a procedure, and the procedures could be distributed across multiple machines, and would just run as it always had.
Making Distributed Computing Easier
FL: Chuck, you're probably familiar with Mesos by now, and you know that the idea of Mesos was to really make it super easy to write distributed systems. Of course, now with Kubernetes, as well, you have something similar. People want to make distributed programming much easier. That's still as true today as it was back then.
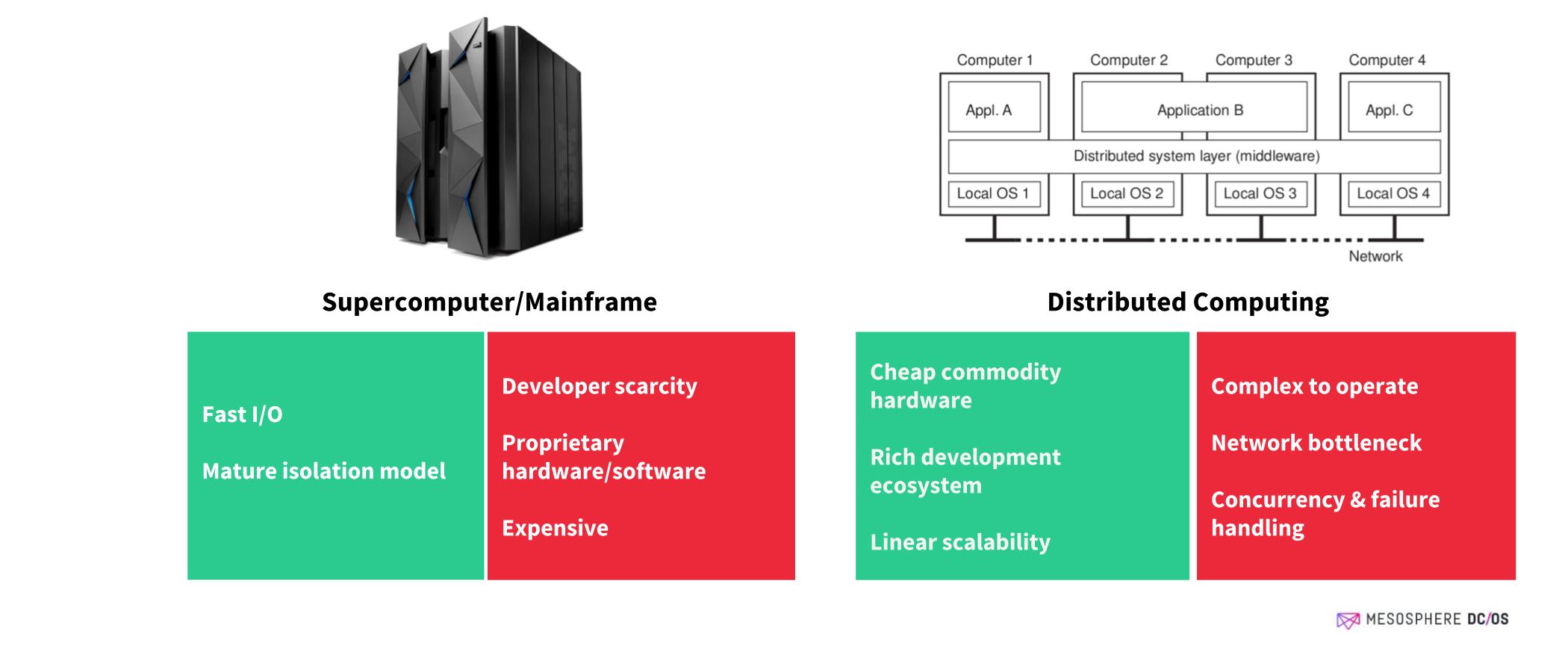
CM: Yes, absolutely. Early on there was a war between multiprocessing and distributing processing, supercomputing versus network computing, and this has been an ongoing battle even to today. A distributed system requires a network fabric between nodes and this is always much, much less bandwidth than what's internal to a single node. After Sun Microsystems, I did a couple of startups, then went to Network Appliance which was building filers. At that point I started to focus on distributed systems from the angle of scaling client storage independent of the architecture of the processor scaling and building distributed RAID arrays. The thing with distributed file systems is that they're very state dependent. You can't have a bunch of people changing and moving files without properly managing state. So one of the things we discovered was that you have a lot of metadata that has to be true across all nodes before you can finalize a transaction. The metadata and how fast you could move it around the network was the constraint on how fast you could run these transactions.
Origins of Container Technology
FL: At Sun Microsystems back in the day, you guys were already working in the kernel, on the operating system side on isolation and packaging, right? You basically came up with Docker before Docker was around, or at least with things like Solaris zones and C groups. From your experience, what actually motivated that work at Solaris, and why did it take so long for the world to really pick up this topic? And why are so many today hyping a technology that's old?
CM: So that's a really good question, and it relates to this battle between parallel processing systems and distributed systems. Within Sun Microsystems there were two efforts: Beowulf clusters and typical multiprocessing machines. In the Beowulf cluster, which was inexpensive, one of the features it brought to the table was that you could take out a node and use it in the cluster and it would not affect the bandwidth, it would not affect the resource utilization on other nodes. This made Beowulf clusters desirable, but the parallel processing guys didn't have the same luxury, so they really wanted to develop architectures where dedicated servers ran specific tasks using a kernel that could isolate the parallel processes. Each server would be sized to the appropriate task, and when the mission changed for the server, it was basically useless junk. There was a tremendous demand from customers who said, "I don't want to buy a new machine every year. I want to be able to reuse the same hardware in different ways. I want to be able to reconfigure it."
The key needs were better resource utilization, process isolation, and the need to prevent information leakage. It turned out that about twenty years earlier IBM did sort of solve that problem with partition isolation, but they did that on custom mainframe hardware and architecture. It turned out that everyone wanted that too, but on low-cost commodity hardware. And it was at that particular insight that Google had internalized in early 2000 and gotten really good at.
And right about that time, I got recruited to work at Google in their platforms group to scale storage. And that was a tremendous opportunity because I was developing extremely large network storage systems. I realized a very important point about distributed systems, that there's a point where the metadata between the systems overwhelms the actual service.
The amount of network bandwidth available to support the service actually becomes the factor that decides how much data you can get in and out of the system. Google was very famous for having a policy where every node was uniformly the same, so that you could just schedule things on top of them. I brought in a somewhat heretical notion that perhaps storage can be a first-class service running on equipment that did nothing but provided a storage API to the network.
Containers Go Mainstream
FL: So it looks like a lot your work, throughout your career, has been around isolation, has been around making resources shared more efficiently. We've talked a little bit about the early origins of container technology at Sun Microsystems. Just to double-click on container technology, why do you think it took so long for this technology that was built into Solaris to become mainstream with Docker?
CM: The reason is because computer performance improved faster than the need for process isolation and greater system efficiency so people could just solve their problems with more hardware. That held us for a while, but then having more and more hardware started to create its own set of problems. Computers are so fast today, disks are so dense, memory is so cheap, that it takes a fairly big problem for you to actually want to partition it. Most people buy cheap hardware and if it's only utilized by 20 percent, they don't care because they don't have a lot of money invested in it. That was not the case for AWS, Azure, Google, or Facebook. If you look at the early work in containers, it came from the ability for these companies to simplify and manage their infrastructure and run the most efficient operation they could.
They started offering these things as a service, and their customers started to see the benefits of being able to deploy standardized configurations quickly. Then those customer started to want that infrastructure in their own datacenter to gain the efficiency and functionality of a Google or Amazon. Plus, when employees from Amazon and Google left those companies and went elsewhere, they wanted these tools so they started to recreate them. What started as a resource utilization problem inside very large companies became a lot of open source tools that the rest of the world could use.
What's Next for Containers?
FL: Based on your experience with distributed systems, do you think that we're going to have a similar path where some of these companies like Google, where you've really solved hard networking problems, the solutions there will actually trickle into mainstream maybe even with initiatives such as the Container Network Interface and other projects that are out there?
CM: Yes, and I think this is a big data problem. Plus, it's all the rage today for you to take very large data sets and apply algorithms that are collectively known as machine learning or correlation algorithms, and you can extract insights from the data that were not previously visible. That's being done by distributed systems because they're more cost effective to scale and this exacerbates the network bandwidth problem.
The Future of Distributed Computing
FL: It sounds like you're saying that you believe there's going to be a future where there are a lot more clouds than just the three or four centralized clouds we currently have and there are going to be clouds at the edge.
CM: Yes. Much of this revolves around how cheap processors have gotten. We can build clouds of cheap processors connected to very inexpensive sensors and readers at the edge. They'll be a self-contained cloud. You could have tens of thousands of these in a single location. They may not even need to be connected to the Internet as they can function on their own. They're their own cloud. It's similar to the technology we were building at the very beginning of distributed computing.
Please follow Chuck on Twitter and Hacker News.


