






Dec 18, 2017
Kevin Stoll
D2iQ

5 min read
The following is a summary of the presentation "Distributed Deep Learning on Apache Mesos with GPUs and Gang Scheduling" delivered by Min Cai, Alex Sergeev, Paul Mikesell and Anne Holler of Uber at this year's MesosCon North America. The Uber team shared how they built a distributed learning platform on Apache Mesos (the core technology underneath Mesosphere DC/OS) to conduct research for self-driving vehicles, forecast rideshare trends and prevent fraud. Uber has adopted a distributed deep learning platform, named Horovod, which allows the company to optimize models designed for a single GPU to run across multiple GPUs and to schedule them in gangs through the use of a custom scheduler named Peloton.
https://www.youtube.com/watch?v=Ktc3GjshHcc
Distributed Deep Learning Optimizes Uber Operations
Uber's ability to use distributed deep learning techniques is the secret to their success in several key areas. Autonomous vehicles at Uber are a core component of the company's future business. Training compute clusters to process the 3D models for computer vision and depth perception, local maps, weather, and many other factors involved in navigation require massive amounts of data and compute. A key metric for the success of such a program is how quickly a new computational model can be trained by a deep learning cluster. While research for autonomous vehicles represents the future, the company also runs numerous models around today's rideshare service, which faces the same problems as any other supply chain model. In the case of trip forecasting, demand is predictable over time and the supply consists of online and available drivers. Uber analyzes historical data, combined with weather, upcoming local events, and other data to alert Uber drivers of upcoming peaks in demand so they can be ready to drive. The same deep learning system is also used to flag and prevent fraud on the part of customers and drivers.
Distributed Deep Learning for Speed and Scale
Uber works with data on a remarkably large scale. The datasets and the deep learning models that they use to train models are much larger than what could be serviced by a single host, GPU or task. The usual single-threaded model of a job owner with many workers doesn't scale to meet the demands presented by developing and training deep learning models on this much data and the aggressive time-to-market constraints faced by Uber and other leading Silicon Valley companies. Uber engineers realized that a fully distributed, many-to-many model is more valuable because it can be scheduled, prioritized, resourced and treated as groups of services. They improve model training efficiency by training models across hundreds of GPUs and sharding data across the cluster for to minimize delays caused by network latency. Uber's core distributed deep learning platform is built on a combination of Apache Mesos, Peloton and Horovod.
Deep Learning on Apache Mesos
Uber evaluated a number of solutions before choosing Apache Mesos due to a combination of the strength of the community and the platform's features. The platform's broad adoption in the market across both enterprise and web-scale companies moved initially got their attention. The maturity of the Mesos community ensures that upstream commits are timely, relevant and stable. The combination of field-proven scale, reliability and a high degree of customization combined with features such as native GPU support, nested containers, and Nvidia GPU isolation were all considerations for Uber as they looked for a scheduling platform focused on distributed deep learning analytics. Apache Mesos provides native support for GPUs, whereas with other container frameworks Uber would likely have been required to pull an upstream patch, develop their own codebase of that framework and support it themselves in production. Apache Mesos also has the correct CUDA versions embedded in its containerizer which simplifies deploying distributed deep learning frameworks. Uber draws on Apache Mesos' unique abilities to run containerized distributed TensorFlow that allow them to wrap their management code for TensorFlow into a sub or nested container separate from the developer specific workload. As a result, Uber's developers can be more efficient because they can focus on model development and training instead of on managing TensorFlow itself.
Uber Peloton for Gang Scheduling
While Apache Mesos is the perfect tool for scheduling tasks, managing resources and recovering from task failures, Uber wanted to add their own functionality so they could run distributed deep learning workloads they way they wanted. In particular, Uber added more granularity for TensorFlow workload management and scheduling. For this reason, the Uber engineering team developed Peloton their own workload manager with a focus on customizing job/task lifecycle management, task placement and task preemption.
Now Uber can manage tasks at a granular level and treat a job submission with hundreds of tasks as a single gang. Gangs are then treated as a single atomic unit by Peloton even though each task runs independently in a separate container.
Uber Horovod Improves TensorFlow Multi-GPU Support
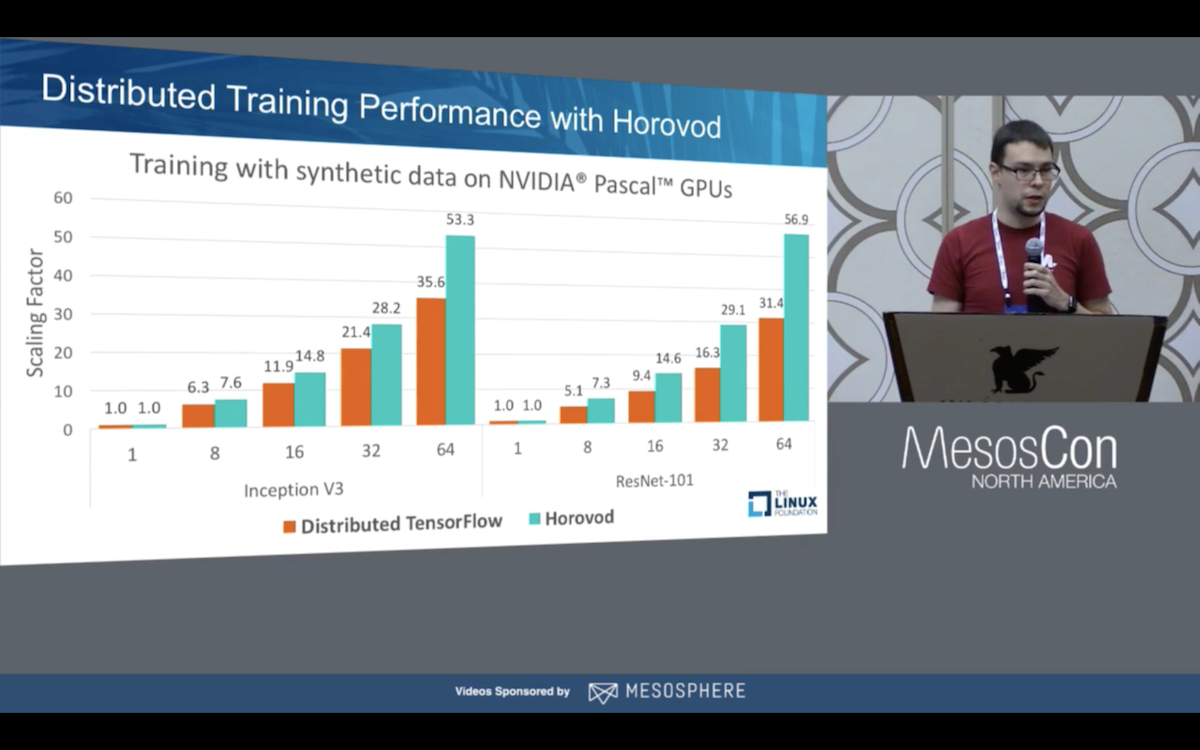
After Uber solved for core resource management and gang scheduling, engineers turned their attention towards developing a solution to schedule multi-GPU tasks in a developer friendly manner. At Uber, they use TensorFlow for their deep learning models but find the developer experience with multiple GPU support to be cumbersome and error prone for developers. To improve on this, the team developed Horovod, a developer interface to multi-GPU job creation based on a single GPU model job. As a result, they have significantly reduced developer error and time to complete jobs. In one example presented at MesosCon North America, they went from roughly 56% efficiency out of their GPU cluster to roughly 82% with Horovod, a 28% improvement.
Learn More About Distributed TensorFlow On DC/OS
To learn more about deploying TensorFlow models on DC/OS please watch Running Distributed TensorFlow on DC/OS from MesosCon Europe and checkout the example tutorial.
If you have questions about distributed TensorFlow on DC/OS, please reach out via the tensorflow-dcos Google group or the #tensorflow Slack channel.


