Dec 19, 2017
Joerg Schad
D2iQ

12 min read
Recent advances in computational resources, amount of data available, and machine learning research have made neural networks a powerful and popular tool for many users. This trend is also reflected in the growing number of deep learning frameworks such as TensorFlow, mxnet, Keras, caffe, or pyTorch.
While probably TensorFlow is currently receiving most focus (including the DC/OS TensorFlow package that enables one-click setup of a fault-tolerant, distributed TensorFlow cluster), there is no one-size-fits-all framework for every team and every use case. In fact, many teams actually deploy multiple frameworks for different models. Therefore, it is critical that data science teams choose a platform that support multiple frameworks so they can have the flexibility they require.
In this blog post, we will look at the rationale behind deploying multiple frameworks and how to deploy them. We will first look at the differences between PyTorch and TensorFlow then deploy our first PyTorch model on DC/OS. Then we will utilize the DC/OS GPU support in order to accelerate model training.
Deep Learning with PyTorch vs TensorFlow
In order to understand such differences better, let us take a look at PyTorch and how to run it on DC/OS.
PyToch, being the python version of the Torch framework, can be used as a drop-in, GPU-enabled replacement for numpy, the standard python package for scientific computing, or as a very flexible deep learning platform.
Where does this flexibility come from? To understand this, let us implement a simple model in TensorFlow and PyTorch and compare each implementation. The model we are trying to learn is trivially y= 3*x and is adapted from this blog post.
Let us first look at the TensorFlow implementation:
import tensorflow as tf
import numpy as np
X = tf.placeholder("float") Y = tf.placeholder("float")W = tf.Variable(np.random.random(), name="weight")
pred = tf.multiply(X, W)
cost = tf.reduce_sum(tf.pow(pred-Y, 2))
optimizer = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for t in range(10000):
x = np.array(np.random.random()).reshape((1, 1, 1, 1))
y = x * 3
(_, c) = sess.run([optimizer, cost], feed_dict={X: x, Y: y})print c
Here we first specify the network graph and optimizer configuration and then below sess.run([optimizer, cost], feed_dict={X: x, Y: y}) actually does one training pass of the network. This approach is often described as Static Compute Graph, as one first defines a static graph and then does multiple training runs over the complete graph.
Let us look next at the PyTorch version of the same model:
import numpy as np
import torch
from torch.autograd import Variable
model = torch.nn.Linear(1, 1)
loss_fn = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for t in range(10000):
x = Variable(torch.from_numpy(np.random.random((1,1)).astype(np.float32)))
y = x * 3
y_pred = model(x)
loss = loss_fn(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print loss.data[0]
With PyTorch one defines the Dynamic Compute Graph during the execution. That means each step is immediately evaluated as opposed to the Static Compute Graph, which was evaluated after it was completely specified. Another way of describing these approaches is Define-and-Run for TensorFlow/Static Compute Graph and Define-by-Run for PyTorch/Dynamic Compute Graph.
What are the implication of this? First of all, the PyTorch/Dynamic Compute Graphs allows for a very flexible setup. For example, one can change the graph between different runs of the same model. This is especially useful when dealing with recurrent neural networks and variable size inputs. Also, debugging PyTorch is simpler as one can use the standard python debugging tools such as pdb (or even just lazily print at different steps ☺).
On the other hand, TensorFlow/Static Compute Graphs have a larger potential for optimization and batching given that the entire Graph can be optimized at once.
For more discussion of the differences between both frameworks/Compute Graph Models there are many good articles available, check out the following blog posts as a starting point:
As we can see there are use cases applicable to both models, and so it might even make sense for a single team to utilize both. They might, for example, consider PyTorch for explorative projects benefiting from the simple debugging capabilities and recurrent neural networks with varying inputs benefiting from the flexibility of the Dynamic Compute Graph. On the other hand the team might consider TensorFlow for highly optimized large convolutional neural networks (CNNs).
That raises the question, how can one operate both frameworks easily, potentially on the same infrastructure?
Running and operating multiple distributed frameworks on a shared infrastructure is one of the key strength for DC/OS and especially its GPU isolation makes it very suitable for Deep Learning Frameworks which often utilize GPUs for faster, more efficient learning.
PyTorch on DC/OS
How can we run PyTorch on DC/OS? There is not yet a complete DC/OS package--like the package for DC/OS TensorFlow package--available, but that doesn't stop us.
There are multiple Docker images available for PyTorch, we prefer this one over the official one as it contains many useful tools from the PyTorch ecosystem. Please note that if you plan to use GPU isolation, you should make sure that the Docker Images contains the right Cuda version for your infrastructure.
We assume you have access to a running DC/OS Cluster (>= 1.9) and a configured DC/OS CLI. We can then deploy the application definition below either via the UI or CLI:
{"id": "/pytorch",
"instances": 1,
"cmd": "while true; do sleep 1000000; done",
"container": {"type": "MESOS",
"volumes": [],
"docker": {"image": "mesosphere/anibali-pytorch:0.2.0"
}
},
"mem": 2000,
"cpus": 1,
"gpus": 0
}
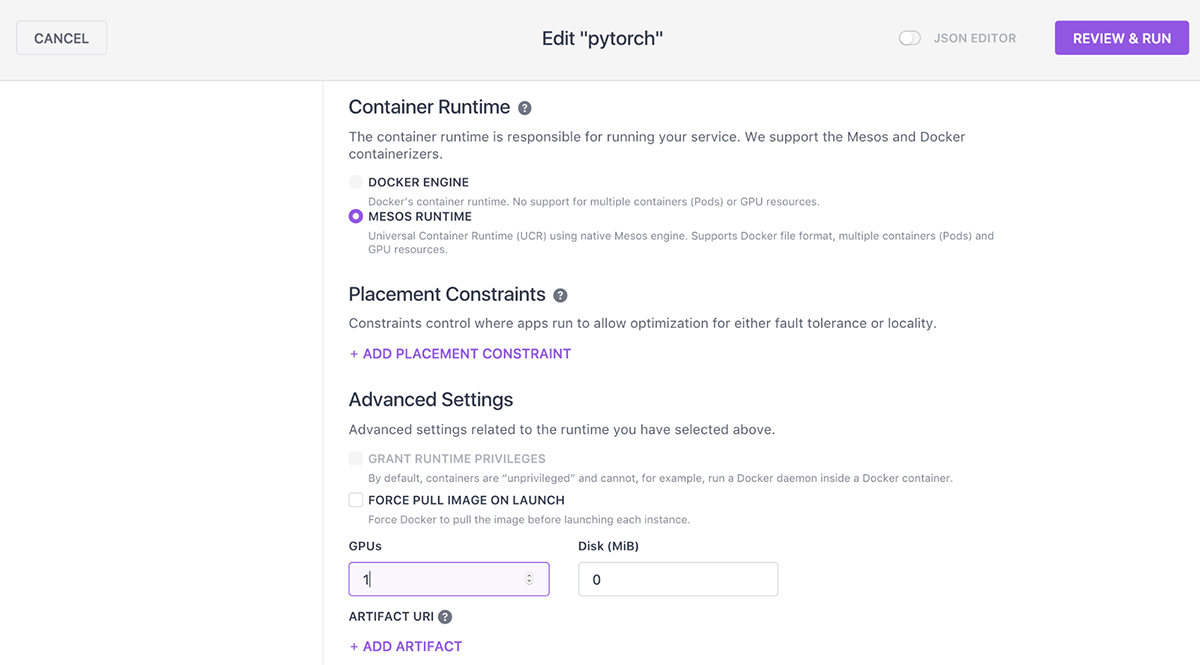
Figure 1: Starting Service from DC/OS UI.
The application definition starts a single container using the Mesos Containerizer/Universal Container Runtime and access the following resources:
- 1 CPU
- 2 GB of Memory
- 0 GPUs (we will add GPU support later)
Note that, the start command is a simple "sleep" as we will use the container interactively.
Once the service is running, we can use the DC/OS CLI to access the container:
dcos task exec -it pytorch bash
Next, we need to add PyTorch to our path and we will clone the PyTorch example repository.
export PATH=/home/user/miniconda/envs/pytorch-py36/bin:$PATH
export CONDA_DEFAULT_ENV=pytorch-py36
export CONDA_PREFIX=/home/user/miniconda/envs/pytorch-py36
git clone https://github.com/pytorch/examples.git
cd examples
From there we can now run the 101 example of Neural Networks, mnist:
time python mnist/main.py
At the end we should see some output similar to:
Test set: Average loss: 0.0543, Accuracy: 9816/10000 (98%)
real 14m49.390s
user 15m35.794s
sys 0m41.390s
Congratulations, you have just trained your first PyTorch model on DC/OS! Now let's see how easy it is to accelerate model training by using the GPU support provided by DC/OS.
Training Models Faster in PyTorch with GPU Acceleration
GPUs are really well suited for training Neural Networks as they can perform vector operations at massive scale. Fortunately, DC/OS supports isolation and scheduling GPU resources between different tasks.
Note: For the following part you will need access to a DC/OS cluster with GPU resources, please refer to the documentation for details on setting up such cluster.
First, we must enable GPU support for the DC/OS Docker container. Please note that accessing Nvidia GPUs in containers usually requires a special wrapper to start the container: nvidia-docker. Fortunately, our application definition uses the Universal Container Runtime, which already supports the same functionality.
One can enable GPU support for the above application definition by changing the GPU attribute to:
…
"gpus": 1
As an alternative, we can also utilize the DC/OS UI for our already deployed PyTorch service:
Figure 2: Enabling GPU support for the pytorch service.
Once the deployment has finished we again use the DC/OS CLI to access the running container:
dcos task exec -it pytorch bash
Also we again set the PATH and clone the PyTorch example repository:
export PATH=/home/user/miniconda/envs/pytorch-py36/bin:$PATH
export CONDA_DEFAULT_ENV=pytorch-py36
export CONDA_PREFIX=/home/user/miniconda/envs/pytorch-py36
git clone https://github.com/pytorch/examples.git
cd examples
Before running the Mnist example again, let us experiment a bit with the GPU isolation in DC/OS. Nvidia-smi is a helpful tool to view the available GPUs:
# Set up environment to access Nvidia GPU libraries and run nvidia-smi
export LD_LIBRARY_PATH=/usr/local/nvidia/lib64
export PATH=$PATH:/usr/local/nvidia/bin
nvidia-smi
As we only specified a single GPU in our application definition, nvidia-smi inside our container should only report one GPU despite potentially more GPUs available on the node:
Sun Dec 3 01:49:20 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 367.35 Driver Version: 367.35 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GRID K520 Off | 0000:00:03.0 Off | N/A |
| N/A 31C P8 17W / 125W | 0MiB / 4036MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
The simplest way to test whether GPU support is enabled in PyTorch is probably:
python3 -c 'import torch; print(torch.rand(2,3).cuda())'
0.2775 0.6453 0.6349
0.4785 0.4630 0.2352
[torch.cuda.FloatTensor of size 2x3 (GPU 0)]
Now, we can finally train our mnist model using GPU support:
time python mnist/main.py
This time the output should look similar to
Test set: Average loss: 0.0538, Accuracy: 9814/10000 (98%)
real 2m50.693s
user 2m50.486s
sys 0m10.924s
Congratulations, you have achieved acceleration of more than 5x by utilizing GPUs while training your PyTorch neural network!
Enhancing PyTorch Support in DC/OS
Please note that deploying PyTorch in a single container is not a production-grade setup. A framework for deploying and operating a distributed and fault-tolerant PyTorch cluster similar to the DC/OS TensorFlow framework would be a logical next step. If you are interested in contributing to such framework (or have any other feedback) please reach out via the tensorflow-dcos Google group or the #tensorflow Slack channel.
If you want to learn more about deploying TensorFlow models on DC/OS please watch the Running Distributed TensorFlow on DC/OS talk from MesosCon Europe and checkout the example tutorial.