






Aug 26, 2015
Niklas Nielsen
D2iQ

4 min read
High-priority, user-facing services are typically provisioned on large clusters for peak load and unexpected load spikes. Hence, most of the time, the allocated resources remain drastically underutilized. While CPU and memory allocation is often close to or above 80% of those peak loads, the average usage is typically below 20%.
Apache Mesos is already known for helping operators increase cluster utilization by co-locating workloads on the same machines. Now, the community has added oversubscription to the Mesos feature list in order to address problems associated with overprovisioning and increase utilization even further. The result is that Mesos users can take advantage of temporarily unused resources to execute best-effort tasks, such as background analytics, video/image processing, chip simulations and other low-priority jobs.
This technology is already used at some of the world's largest clusters for up to 20% of their workloads. Now, this is available for everyone with Apache Mesos.
Introducing oversubscription in Mesos
Thanks to joint work by Twitter, Intel, Mesosphere and the Mesos community, we landed the initial mechanics for oversubscription in Mesos in a record time of two months.
We aimed for extreme flexibility in order to enable custom policies. This allows us to iterate as we gain experience and insights into the deep tech that is required to oversubscribe with high stability. It also helps us avoid choosing too conservative a design, and therefore missing opportunities to run jobs on unutilized resources.
The current architecture lets us achieve three goals:
- The agents can measure slack resources (allocated but unused resources) and apply data processing (smoothing, predictions, etc.) and safeguards to avoid excess corrections or degraded quality of service.
- Mesos Frameworks can register with a Framework Capability, which hints that they know how to run on oversubscribed resources. After doing this, offered resources will include oversubscribed resources.
- One of the biggest concerns about oversubscribing resources is stability; not all resources in a modern computer can be isolated well. Memory bandwidth, shared last-level caches and I/O are some of the resources where even small co-located tasks can have a crippling negative effect on high-priority workloads. When best-effort tasks and high-priority tasks (i.e., regular Mesos tasks) are running side-by-side, a new component in the agent measures the health of the high-priority tasks and can correct for mispredictions, load increase, phase changes in the tasks and accidental interference.
The interactions between the new components are illustrated below:
Mesos Modules are used to enable this flexibility, and Apache Mesos 0.23.0 is now shipping with the first and naïve estimator -- fixed (i.e., static) oversubscription. Here, an operator can define how many resources should be oversubscribed on agent startup. In the recent oversubscription user guide, we describe how to enable this in your organization.
Taking oversubscription further with Project Serenity
However, while static oversubscription enables conservative and predictable oversubscription, dynamic oversubscriptions have shown to make oversubscription even more robust and precise by getting much closer to utilizing the actual slack resources. Mesosphere and Intel collaborated to develop Project Serenity, a module set that enables dynamic oversubscription in Mesos.
Here, we dynamically measure the usage slack available for best-effort tasks (i.e. the allocated but unused resources). Project Serenity also applies dynamic safeguards to protect the high-priority workload from the performance loss due to interference on shared hardware resources, such as caches, the memory system and I/O devices. The combination automatically maximizes the resources available for best-effort computations (high cluster utilization), while minimizing the impact on the quality-of-service (QoS) for the high-priority workloads.
To do this, Serenity is composed of pipelines of decoupled data transformations for both resource estimations and QoS corrections. This kind of oversubscription was demonstrated and proven at Google with Heracles.
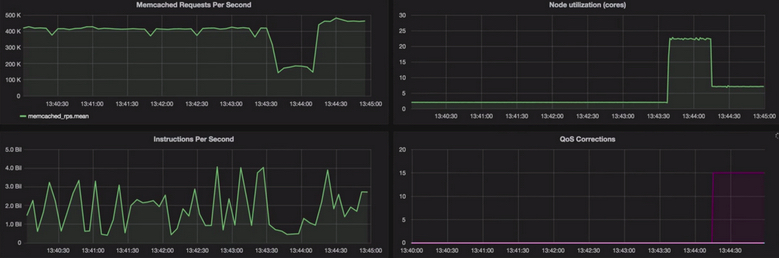
The first version of Serenity was demonstrated at MesosCon 2015 and the Intel Developer Conference 2015. In the demo, we showed in action the dynamic slack measurement and dynamic QoS corrections to preserve the expected throughput for memcached.
In this example, we go through three phases:
- First, we run an instance of memcached that only consumes 2 cores out of 36 (72 hyper threads).
- Then, we oversubscribe the unused resources with a carefully constructed aggressor that, despite being throttled by minimal number of CPU shares, consumes large portions of the memory bandwidth on this system and causes a significant drop in Requests Per Second. In this scenario, the drop in Requests Per Second is strongly correlated with a drop in Instructions Per Second.
- Next, Serenity detects this drop by monitoring hardware performance counters and corrects the inference by evicting some of the oversubscribed tasks. This restores the Requests Per Second for our high-priority memcached job.
Project Serenity is still very experimental in nature and there is a long way between proof-of-concept to productization. However, it is a flexible system that allows capturing many different workload types and interference signals. With time, our goal is to evolve this into a general-purpose dynamic oversubscription solution that works -- safely and efficiently -- for a majority of the existing workloads running on Mesos clusters around the world.
To wrap up, there are so many interesting technologies and algorithms that can come out of work around resource oversubscription and this is only the humble beginning. Research and productization of performance profiles, signals and signatures indicating interference are just some of the topics we will continue working on to increase cluster utilization even further. Stay tuned.


