For more than five years, DC/OS has enabled some of the largest, most sophisticated enterprises in the world to achieve unparalleled levels of efficiency, reliability, and scalability from their IT infrastructure.
But now it is time to pass the torch to a new generation of technology: the D2iQ Kubernetes Platform (DKP). Why? Kubernetes has now achieved a level of capability that only DC/OS could formerly provide and is now evolving and improving far faster (as is true of its supporting ecosystem).
That’s why we have chosen to sunset DC/OS, with an end-of-life date of October 31, 2021. With DKP, our customers get the same benefits provided by DC/OS and more, as well as access to the most impressive pace of innovation the technology world has ever seen.
This was not an easy decision to make, but we are dedicated to enabling our customers to accelerate their digital transformations, so they can increase the velocity and responsiveness of their organizations to an ever-more challenging future. And the best way to do that right now is with DKP.
Jul 29, 2020
Karsten Jeschkies
D2iQ
4 min read
Part III: Test Pipeline
So far we covered team culture which amplifies our code culture and design. It was kind of abstract so far and you’ll be forgiven if you skipped right a way to this part. I will cover our test and release pipeline, the thing that probably has had the biggest impact on Marathon’s stability. The pipeline enabled us to discover issues before our users did.
I will first give an overview of the pipeline stages and dive deep into the Loop. You will soon see what I meant by that.
Overview
Marathon is shipped to customers as part of DC/OS to customer clusters. Some even have air gapped clusters. That means we cannot have a complete continuous deployment pipeline. We cannot patch clusters a few times a week. Thus, we have to concentrate our efforts on continuous integration, CI, and make sure that we cover as many use cases as we can.
Our CI pipeline has roughly three stages. We have testing, soaking and mixed workloads. The first tests that run on each code change are unit tests. They are followed by integration tests. The integration tests create a local Mesos cluster and call the Marathon API. We call this white box testing, as we make assumptions about the state of the small cluster. Once a code change passes these tests and lands, it is integrated into DC/OS. The pipeline then runs a system integration test against a full blown cluster. We call this black box testing, since we test the system as if we were a user that knows little about it. During the system integration tests, we also inject some simple failures such as network partitioning and leader crashes.
All tests run in less than an hour. They are fairly short lived and cannot catch bugs such as memory leaks. As such, they do not cover long term use cases. This is where our soak cluster comes in. The soak cluster is a long running cluster of DC/OS master with a predefined workload. It is the ideal test bed for different scenarios requiring different services we want to test in combination before a release.
After the soak cluster we have something called the Mixed Workload Test. It is a one day test run on a truly large cluster with over one hundred fifty c5.18xlarge EC2 instances (Note 4). We start hundreds of Marathon and Jenkins instances and thousands of Mesos tasks. This simulation really stresses the system and uncovers bugs customers would only see under heavy workloads.
The Loop
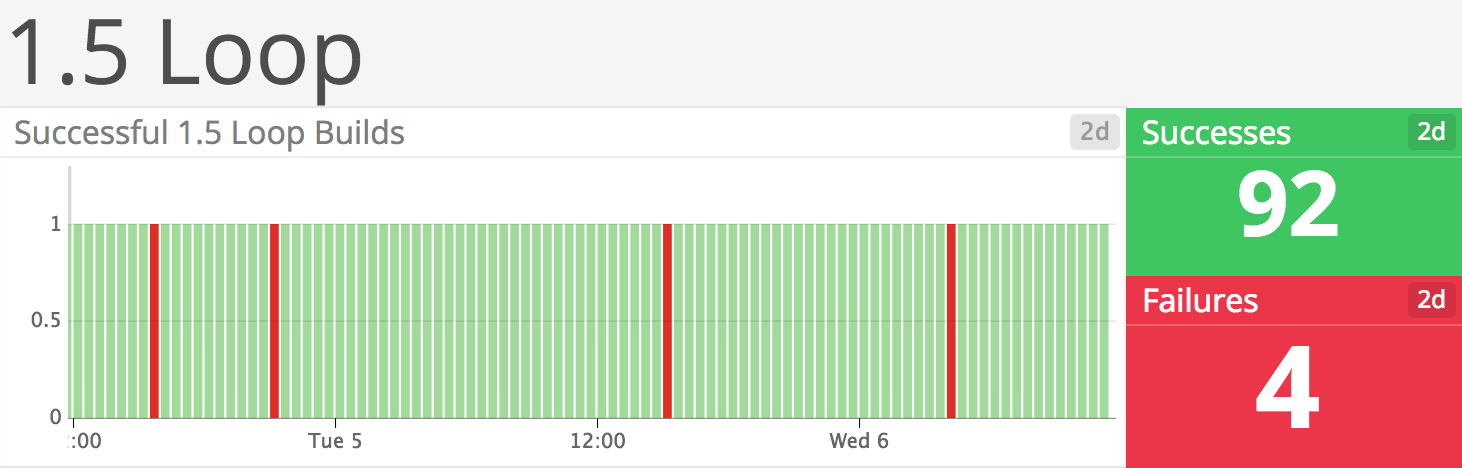
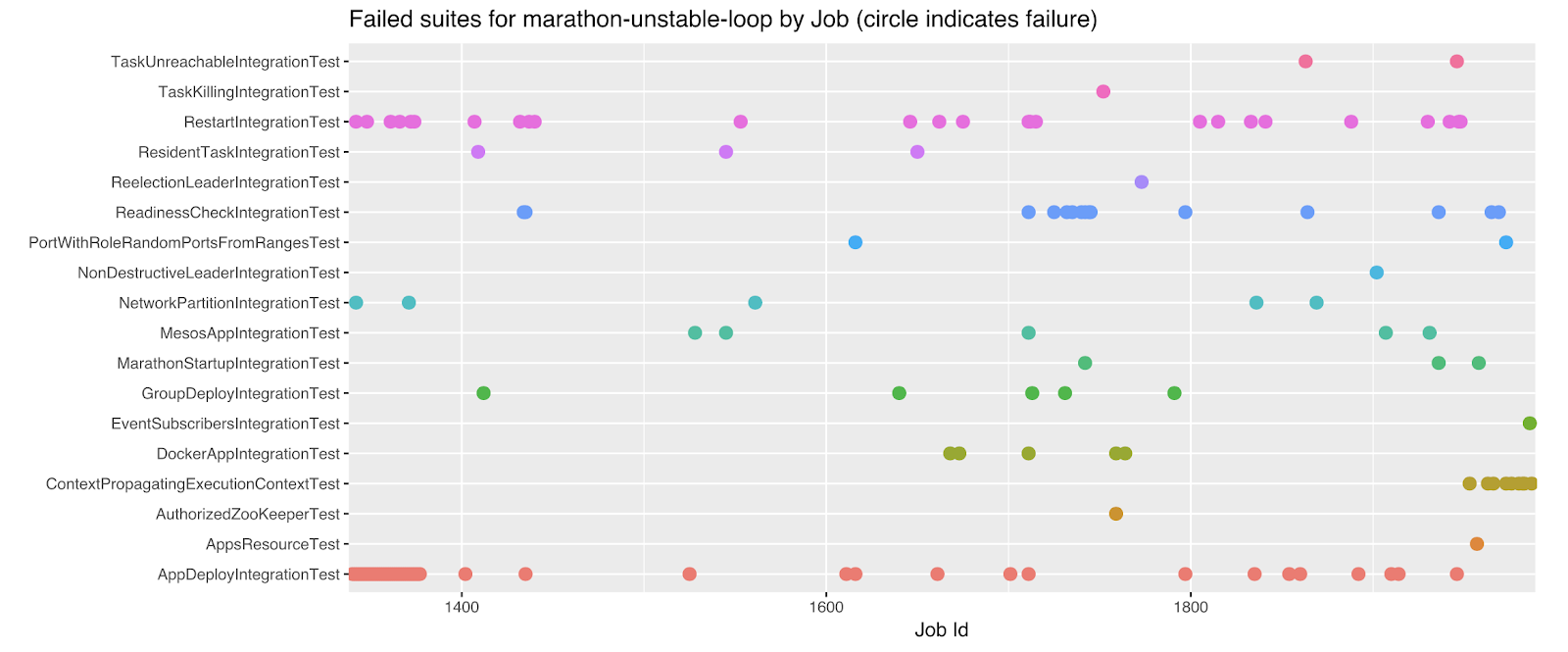
As nice as the pipeline sounds, it was tough to get running in practice. The integration tests especially gave us a headache; they would fail roughly thirty percent of the time. The goto solution for these flaky tests is to retry them a few times in the pipeline or even to ignore errors. This is an approach I do not feel comfortable with. Any flaky test has a potential bug at its core. To find these bugs, we needed more data and to generate this data we introduced the loop. The loop runs a Marathon branch roughly fifty times a day and reports to a dashboard (please see Figures 1 and 2). So after two days, we had one hundred runs and had enough data to see which tests were failing and to debug why. We deemed two failed runs in one hundred noise. Anything above that level was not accepted. It took us roughly a year to get to this two percent failure rate. It was worth it, as it gave us confidence to tackle more impactful refactoring and features.
Figure 1: The loop dashboard for Marathon 1.5 showing four failed builds.
Figure 2: Visualization of flaky tests we used to have.
Retrospective
I would like to do a little retrospective on the last three years. We made big steps. However, in recent months I’ve found that our solutions were often tailored for Marathon. It is not trivial to use our pipeline for other projects. There is also no magic bullet. Some systems are not designed to crash. Some teams found other ways to work together and be successful. So my advice should be taken with a grain of salt.
That said, Marathon became much more stable and we shipped features we never dreamed of shipping. I am proud of that.
Outlook
Where are we going from here? The first step is our new library, USI (Note 5). It abstracts away a lot of Marathon’s scheduling and enforces the declarative pattern we’ve found essential. We also went a step further and reduced the size of asynchronous code. USI is basically an event loop that updates an internal state and emits new events for Mesos and the framework (Note 6). It also comes with a lot of test tooling we want to share with any developer of Mesos frameworks.
I would also like to see more failure injection in our test pipeline and generate random input. This should help us catch more errors before our customers do.