






Mar 01, 2017
Peter Guagenti
D2iQ

5 min read
Outages are no one's idea of a good time. If you have worked in technology for any significant period, you have been through one before. The angry customer calls, the lost business, the hit to employee morale, and the humiliating post mortems. It can happen to anyone, which is why IT projects have always included an explicit strategy to ensure high availability, disaster recovery, and business continuity. If you accept that downtime of some parts of your systems is inevitable and plan for it, you reduce its impact.
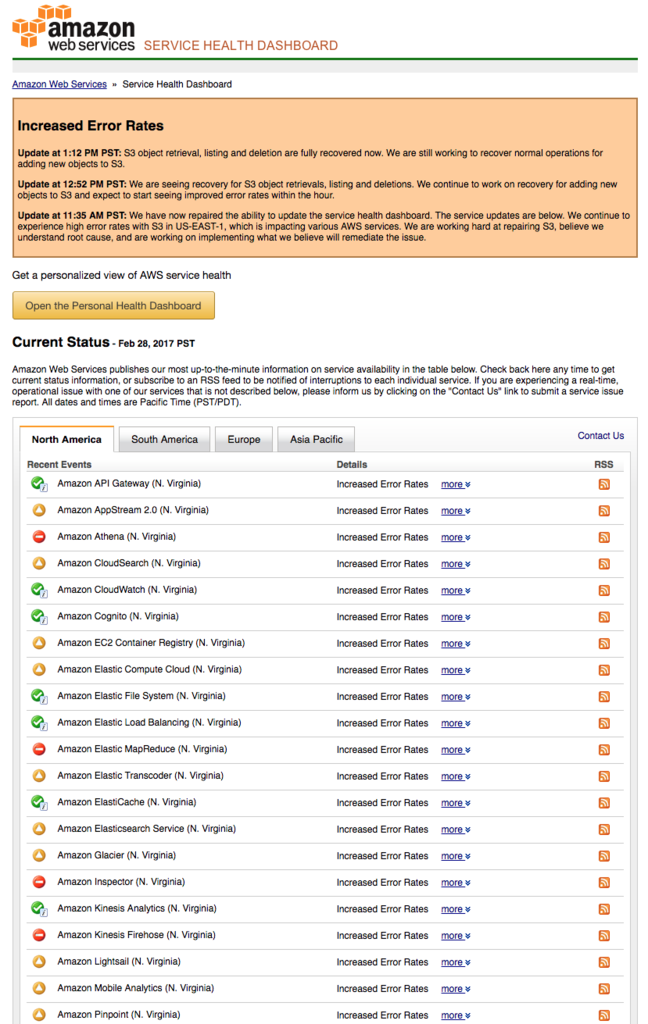
Yet yesterday's massive outage of Amazon Web Services' S3 (Simple Storage Service) platform, and the subsequent downtime of a broad array of Amazon's services that depend upon S3, tells us a different story. S3 is one of AWS's oldest and most popular services, and is used extensively by Amazon's cloud customers. This didn't just affect the usual suspects in the startup world (Zendesk, Slack, and Nest all had outages). Large companies and governmental organizations were hit, too; users reported outages at the United States Securities and Exchange Commission, News Corp., Kellogg's, Procter & Gamble, and more. When Amazon's service went down, it quickly exposed that (at least in the case of many high profile enterprises and SaaS companies) the there was no Plan B and instead thousands of websites failed, affecting and frustrating millions of users across the globe. It even exposed an issue in one of our own services.
In today's always-on, hyper-connected world, downtime of any sort is unacceptable. Even a few seconds of latency results in massive bounce rates, decreased future visits, and (especially in highly competitive categories like media, travel, and retail) a high switch rate to competitors. Significant downtime alienates customers and prospects and has a sizable impact on lost revenue.
Unfortunately this is not the first cloud outage that has affected a large number of customers, and is unlikely to be the last. For example, AWS had another recent outage in its database service, which affected a plethora of services (including internet giants Netflix and Airbnb). Major outages in the cloud giant's Elastic Cloud Compute (EC2) infrastructure in the past have taken thousands of servers offline, and locked customers out of adding new instances in other regions due to oversubscribed demand. These problems are in addition to the minor outages that are not publicized and affect smaller segments of customers.
With generally high uptime and a well-earned reputation for reliability, it's easy to take the public cloud for granted, and many companies are happy to delegate their responsibility for application availability and resiliency. That is not a recipe for long-term success, especially as companies move increasingly into software that doesn't just provide information or entertainment, but instead power our homes, our cars, and our industry.
Today's outage should serve as a reminder to us all that moving to the cloud does not relieve us of the responsibility of business continuity and disaster recovery planning for our applications. High availability needs to be included in every part of our applications, including the underlying infrastructure. That counts for IaaS and cloud providers, too.
Let's all remember the basics:
- Always ask "what if?" — When architecting and developing your application and the underlying services and infrastructure, you need to explore every "what if" scenario. You should explore all potential scenarios and develop an appropriate approach for each, no matter how infrequent. For example, a best practice that has emerged in parallel with the shift to APIs and microservices is to expect downtime or lost connectivity between services and have a fall-back plan, such as caching, failover to alternate systems, or graceful degradation of features.
- Test your application expecting unresponsive services — To identify unknown or less obvious dependencies, don't just test your applications under ideal or most common scenarios. Include some amount of testing that includes downtime in specific services and observe the results. Use the insight you gain to identify high priority areas to address.
- Develop a redundancy plan — We would never think of launching an application without having redundancy in servers, or in your load balancer, or without data back-ups. So why would we then launch an application without redundancy in other critical services? Or in the cloud infrastructure underneath it? If you assume failure and have a clear redundancy plan, you'll never be caught off guard.
We believe that one powerful answer to infrastructure redundancy is to adopt a hybrid or multi- cloud strategy. The most robust solution to protect your application from infrastructure downtime is to spread your workloads across multiple data centers, zones, or cloud providers. Leading analyst firm Gartner has stated that as enterprises move the cloud, the majority are choosing a hybrid cloud strategy.
But the path to hybrid cloud isn't easy. First generation hybrid and private cloud platforms were difficult to install, configure, and operate; never really fulfilling on the promise of elasticity and easy migration. That has changed with the rise and maturation of Mesos and of containerization. You now have choice in how to implement a hybrid or multi-cloud strategy, with Mesosphere's open source and commercial offerings being one of the easiest platforms to deploy and operate.
We believe that companies should be able to tap into the rich cloud capabilities we have all grown to expect from companies like AWS, Google, and Microsoft, but we should be able to do so on top of whatever infrastructure we choose. Companies should be able to deploy and scale their applications easily, and should be able to use the best available resources—from their own data centers, to co-located facilities around the world, or on IaaS virtual machines from the lowest cost and most highly available providers. This is the fundamental premise that led to the creation of Mesosphere DC/OS.
If a hybrid strategy might be of use to you, we hope you'll try DC/OS for yourself.


