






Dec 13, 2017
Chris Gaun
D2iQ
4 min read
Editor's note - This blog post reflects our Kubernetes efforts in 2017. To learn more about Kubernetes on DC/OS, see Kubernetes-as-a-Service Now Available in DC/OS 1.11.
I just returned from Kubecon 2017 last week and the enthusiasm was palpable. There were four times as many users there as the last conference, which gave attendees the chance to interact with tons of vendor practitioners and end users. One salient theme from talking to attendees is that if you ask 1000 Kubernetes users about their solution stack, you will get 1000 different answers.
During my two plus years of talking to the community, around 80% of the thousands of Kubernetes users I meet are using the cluster, along with a panoply of other source frameworks, to build a stack for a particular solution. For example, in my last blog post I mentioned that I hear questions like "how do I use Kubernetes as part of my connected car application" four times more often than "how do I set up single Kubernetes cluster so we have something all developers can share." Most of the users directly involved in delivering a single solution to customers in the best way possible are unconcerned about the grand strategy of IT. One company I've talked to several times, a large European conglomerate, has at least four different Kubernetes projects, whose leads never talk to each other. I always thought that reflects the current stage of the market, but what I learned from the keynotes at Kubecon is that the multiple cluster approach is the correct path for organizations. The challenge is how does operations support the approach of running multiple clusters, each serving as a separate stack.
According to the Kelsey Hightower's keynote at Kubecon 2017, operations should not try to fit everyone into a single shared cluster. That's not how Borg works at Google. Gmail has a different solution stack and isolated cluster from Docs. There are different clusters for different stages of the lifecycle and regions so that if something fails, the impact on customer experience is minimized. Hightower indicated, and I agree, that having different clusters makes it easier to manage life-cycle, organizational structure and use cases.
Yet, a multi-cluster Kubernetes environment of separate stacks presents numerous challenges to DevOps teams. Anyone who has installed Kubernetes knows it is not trivial to manage. Each business group may want to update their cluster on a different schedule as they test new Kubernetes features to make sure they don't affect the solution. Some clusters will need to scale differently. You wouldn't expect an end-of-day portfolio analysis to require same resources and nodes as other applications that run in a steady state. Creating identical clusters on drastically different cloud and data center infrastructure also presents challenges.
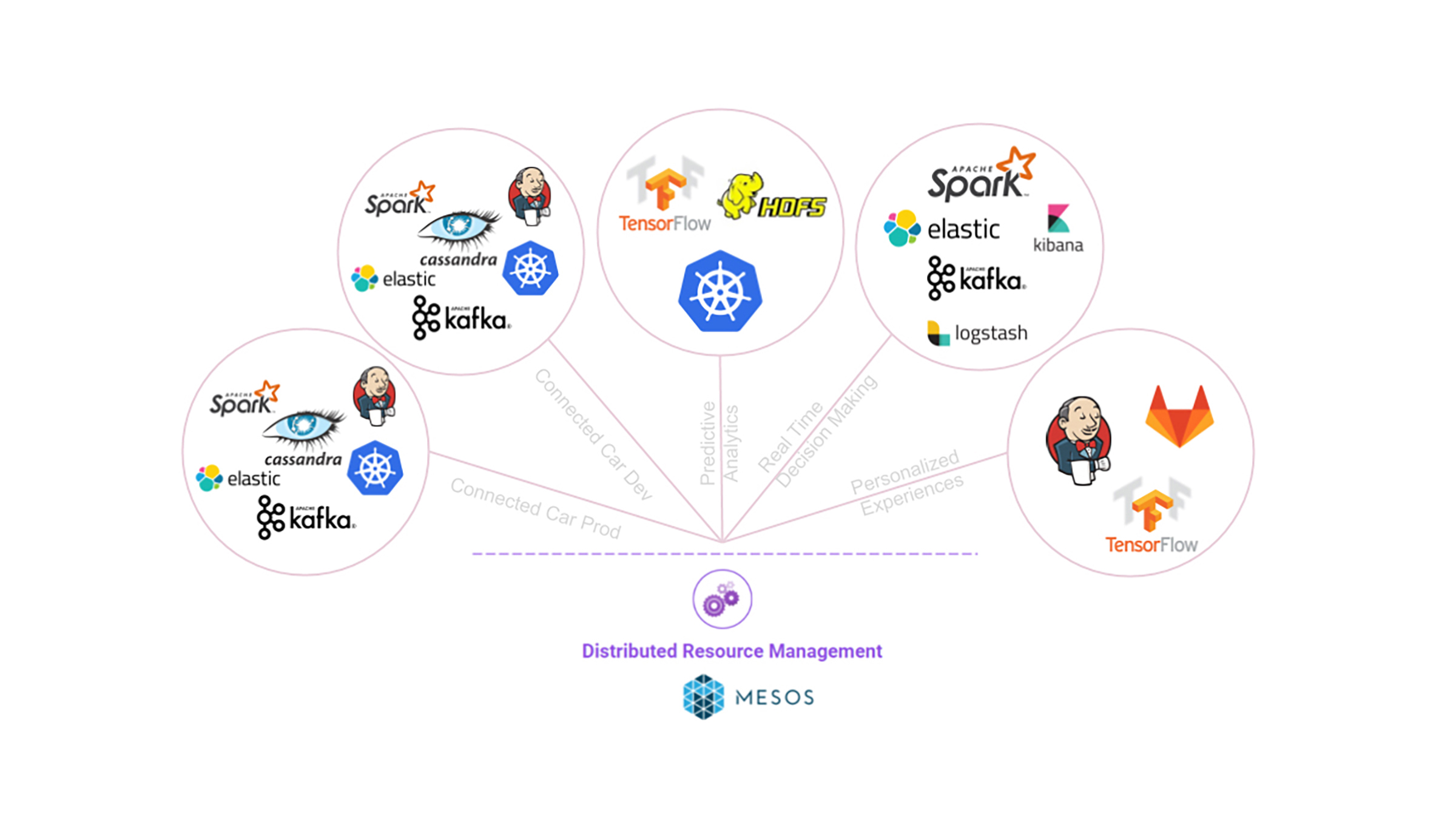
Meet The Multi-Cluster Kubernetes Future
Unlike the utopian notion of a single, shared, omnipresent Kubernetes cluster provisioned across both data center and cloud, individual stacks that include Kubernetes should be deployed and managed according to an organization's needs. Further, Kubernetes is not an island. At a minimum, it is almost always coupled with a CI/CD solution. In addition, the majority of applications require multiple modern fast data services and a growing number of solutions rely on machine learning frameworks in order to meet customer expectations.
It is just a matter of time before these siloed stacks of Kubernetes and other open source tooling are centralized so they can be managed by operations. This presents several challenges for operations. A viable solution must be:
DC/OS Supports Multiple Stacks
Many bespoke stacks with Kubernetes as a component are heading towards production in the future. This presents numerous challenges for operations managing many different configurations and annicarily open source components. One of the reasons I joined Mesosphere was I was impressed with how effortlessly its customers solve this challenge because that is exactly what Apache Mesos was designed to do. Mesos itself is tracking and offering underlying resources to open source frameworks with widely different configuration and scheduling needs. Deploying and scaling applications, services and frameworks from the DC/OS service catalog is trivial because Mesos handles the contractual infrastructure needs of the cluster.
As a Kubernetes user myself, Mesos felt like the answer to many multi-cluster pain points. Mesosphere DC/OS serves as a platform for operations and complete lifecycle management of platform services like container orchestration engines (e.g., Kubernetes), data services (e.g., Apache Kafka, Apache Spark) and machine learning (e.g. Tensorflow). DC/OS provides a universal toolkit enabling companies to power scalable and data-intensive applications. More on Kubernetes on DC/OS can be found in this blog post.
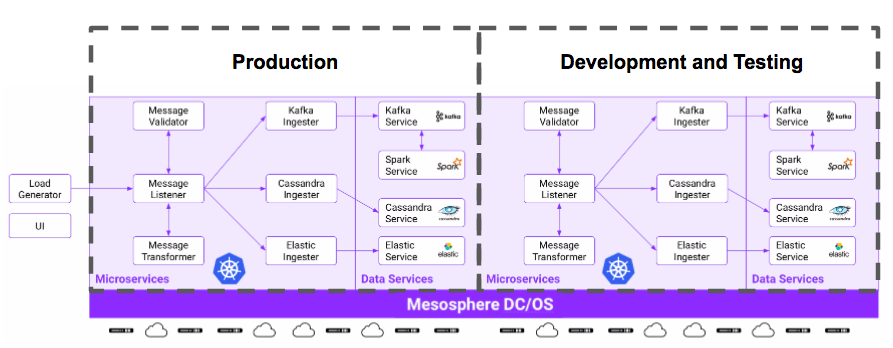
For example, six of the world's leading automotive and automotive technology companies are building their infrastructure on Mesosphere DC/OS. At Kubecon, we demoed an easy way for customers to tackle setting up multiple open source frameworks. In the near future DC/OS releases, it will be easy to set up multiple copies of the stack required for connected cars and run them in multiple Kubernetes clusters. Then, operations will have no problem supporting developers and lines of business with the cloned environments they need. In this way, developers can focus on building new functionality and not on deploying environments.


