Mesosphere's Chris Gaun and Joerg Schad show how to turn raw data into knowledge by using Kubeflow to deploy a basic data science workflow.

May 16, 2018
Joerg Schad
D2iQ

5 min read
Kubeflow is great for deploying a basic workflow for data-scientists, but is only one piece of a complete, production-ready data-science pipeline. Depending on your ecosystem and architecture you might require access to additional components, for example for data preparation or data storage. This blog post reviews our talk at KubeCon that was also covered by a The New Stack podcast "Modernize Your Data Pipeline for the Machine Learning Age".
Data analytics and especially deep learning is now how we turn raw data into knowledge. With the deluge of data that has come from our increasingly connected world, the need to automate its processing, analysis and implementation has driven interest in deep learning tools. Starting your first deep learning project with TensorFlow on your laptop is very simple, but at the larger scale required for most big data sets, organizations often struggle with managing the infrastructure. Kubeflow, a new tool that makes it easy to run distributed machine learning solutions (e.g. TensorFlow) on Kubernetes can be combined with modern data tools to simplify this complexity.
Kubeflow makes it very easy for data scientists to build their own data science pipeline with Jupyter Notebooks, TensorFlow, TensorBoard and Model serving. However, building a production grade data science pipeline requires additional components.
For example, illustrated below, to have a complete deep learning solution, an organization would need to consider data preparation (frequently performed using Apache Spark or Apache Flink), data storage (using HDFS, Apache Cassandra), or request streaming (using Apache Kafka).
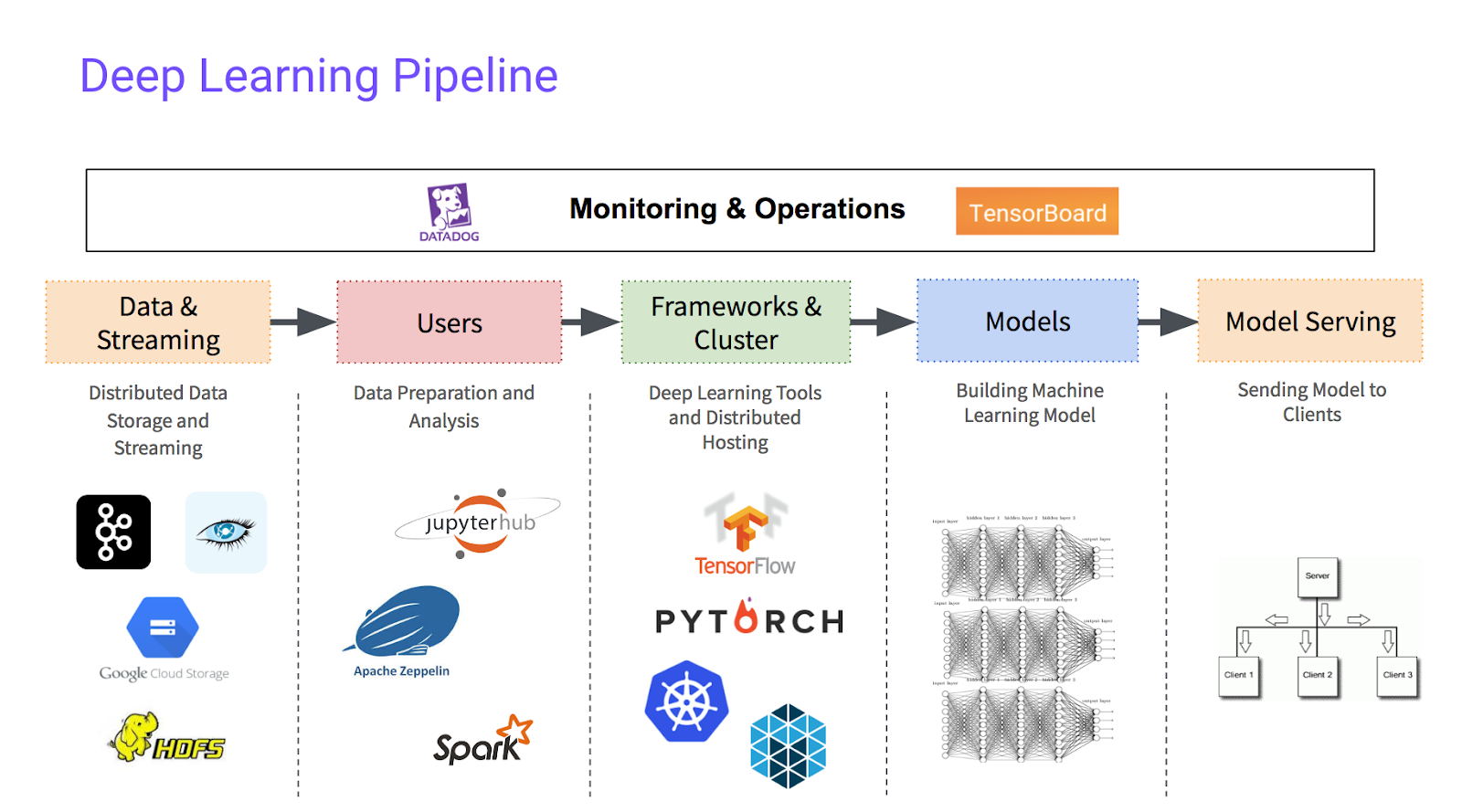
Distributed data storage, preparation and, to some degree, model serving is handled separately from Kubeflow's automation, which gives users the freedom of choice to fit their data pipelines to the deep learning service of choice. Some organizations will use managed public cloud services to fill in the whitespace. However for most larger organizations, data that can feed machine learning algorithms is often already in existing distributed data stores. Also, user preference often comes from a familiarity with existing tools, such as Spark or HDFS, or they may want to use open source services instead of relying on premium tools from cloud providers. For these use cases, knowing how to provision and manage the entire deep learning pipeline is imperative.
The Deep Learning Pipeline
The Deep Learning Data Pipeline includes:
Data and Streaming (managed by IT professional or cloud provider) - The fuel for machine learning is the raw data that must be refined and fed into the processing framework. With large data sets this is accomplished by horizontal scaling that spreads processing and storage across multiple machines.
The pre-processing and post-processing of data is often the most time consuming stage, typically eating up to 40% of the cycles for any machine learning project. Data scientists need to correct wrong or inconsistent data and fill in missing values where necessary. They then need to normalize the data set, making sure that date format, metrics, and distribution range is consistent.
There are several modern open source tools that can help manage distributed storage and pre and post processing:
- Storage - Apache HDFS and Apache Cassandra provide a very scalable store comparable to proprietary public cloud services such as AWS DynamoDB.
- Streaming - Apache Kafka provides high throughput and low latency streaming to transfer data from a source to a deep learning framework.
- Pre-processing - Apache Spark, which is sometimes used as a machine learning framework, provides micro batch processing that can help clean up data. When data is coming in through a fire hose then Apache Flink provides a means for real time cleansing.
User Interaction (managed by data scientist) - Like in high level programming, there needs to be an abstraction that allows the data scientist to focus on conveying the desired outcomes and not the minutiae of how those outcomes are processed. There are several user interfaces that have become popular that allow data scientists to work quickly. Jupyter Notebooks are an open-source web application and user documentation with a focus on sharing. Jupyter is packaged with Kubeflow. Zeppelin Notebooks is a slightly older option that is focused on Spark. The feature set of these notebooks and other user tools are converging so it is more a matter of preference.
For the machine learning pipeline, the notebook needs to be exported to a versioned repository and then distributed to the framework for model training.
Deep Learning Frameworks (managed by DevOps or IT professional) - the keystone for any deep learning pipeline is the framework with the statistical and other mathematical libraries to perform the modeling. TensorFlow often gets the most attention.
Cluster Management (managed by IT or DevOps professional) - container orchestration is an ideal way to distribute the deep learning framework.
- Kubernetes - currently the most popular container management solution and its open source version is the standard. Kubernetes is a good choice if that is the existing container orchestration preference or if sophisticated use cases beyond machine learning are required. Kubeflow provides an easy method to get distributed TensorFlow up and running on Kubernetes with a few steps.
- Marathon - provides lightweight container orchestration for organizations and may be a good fit if the organization is trying to only do deep learning versus using a generalized, feature rich solution.
Mesosphere DC/OS, powered by Apache Mesos, delivers both Kubernetes (and Marathon) as a Service everywhere. DC/OS automates the delivery and management of container orchestration, TensorFlow, deep learning, CI/CD tools and the entire data pipeline as a service.
Model Management (managed by IT or DevOps Professional) - deep learning requires many models, perhaps hundreds or thousands of different models with different data sets and hyperparameters, that need to be stored and later served. In some cases it might even make sense to have multiple models for different execution environments. For example, if you are considering serving your model on a mobile phone or embedded device, you might want to take a look at TensorFlow light. The storage of the models should be highly available,distributed, and should consider the metadata as well.
- Model storage - To store the models, open source distributed data tools such as HDFS or GFS are good options that have been in the market for a while and have a relatively high number of IT professionals that are familiar with their operation.
- Metadata - Metadata includes additional information about the model such as training/test accuracy, model provencence which is required for comparing different models . The open source document stores of choice are MongoDB and ArangoDB.
Model Serving(managed by IT or DevOps professional) - Once the models are processed and stored, the optimal one needs to be served when requested. This stage is what we see as the output of deep learning. When we ask to identify an object, the best model will be served in order to do the job. TensorFlow has essential model serving that comes with Kubeflow. IT professionals may also want to set up Kafka for direct streaming of the models.
Monitoring (managed by IT professionals and data scientist) - There are two pieces involved in monitoring the deep learning pipeline. IT professionals should monitor the cluster hosting the deep learning framework itself. Prometheus, a Cloud Native Computing Foundation (CNCF) project, provides a powerful open source option for cluster monitoring.
The model performance should also be monitored by the data scientist. TensorBoard is a tool that is used to optimize and visualize TensorFlow.
Debugging & Profiling: Debugging and profiling deep learning models can be a challenge, especially with TensorFlow's static compute graph. Luckily there are tools such as TFdebug and the TensorFlow Profiler (now available from the TensorBoard UI), which make understanding the computation and optimizing for performance across CPUs, GPUs, and TPUs much simpler.
As noted above, there are many different options for these components and the choice of a specific component often depends on the concrete environment Kubeflow and your data science pipeline is running in. While Cloud Providers such as Google Cloud, AWS, or Azure have managed solutions for these challenges, an on-prem environment might require alternative open-source solutions such as Spark, HDFS, or Kafka. Note, that open source tools might even be beneficial in a cloud environment as it may be less expensive, interoperable among clouds, and familiar to developers.