






Feb 04, 2016
D2iQ
D2iQ
4 min read
Our Datacenter Operating System (DCOS) is a great platform for many things, including running big data systems such as Apache Spark, Apache Cassandra and Apache Kafka. In fact, we recently completed a revamped Kafka scheduler, currently available in private beta, built especially for the DCOS. It's everything you love about Kafka, but optimized to run alongside other distributed systems in a shared and scalable DCOS environment.
Kafka, as most readers probably know, was developed at LinkedIn several years ago (where it's currently handling more than 1 trillion events per day) and is the de facto technology for managing the flow of data through big data pipelines. Essentially, Kafka acts as a broker, ingesting streams of data as they flow in from devices, websites or wherever, and then parsing that data and sending it to the backend systems that need it. These systems run the gamut from relational databases to Hadoop to stream-processing systems such as Apache Storm.
If you're building a product—whether it's a website, cloud service or connected device—that's going to fulfill user requirements around personalization, analytics and/or real-time feedback, the chances are you'll look at Kafka and the data-processing systems that it feeds.
There are some inherent benefits to running services such as Kafka on the DCOS. Among them are the simple deployment method of dcos package install kafka (in this case), which installs a complex distributed systems in mere minutes. Another is the ability to run Kafka unchanged across local datacenter and cloud computing environments, a feat that is all but impossible without a standard and portable foundational layer such as the DCOS.
The new features in our updated Kafka-DCOS beta service—which is available by contacting Mesosphere—are:
- The ability to deploy multiple instances of the service (and thus multiple Kafka clusters) to a single DCOS cluster.
- Support for Mesos persistent storage volumes for improved reliability and data durability, and simpler storage management.
- Support for sending performance metrics to a statsd server (i.e., Graphite, InfluxDB).
In the next couple of weeks, the beta version will include:
- Automated runtime configuration updates with breakpoints and rollback.
- Automated runtime software updates with breakpoints and rollback.
The version of Kafka-DCOS that is publicly available in the Mesosphere Universe repository does not presently include these features.
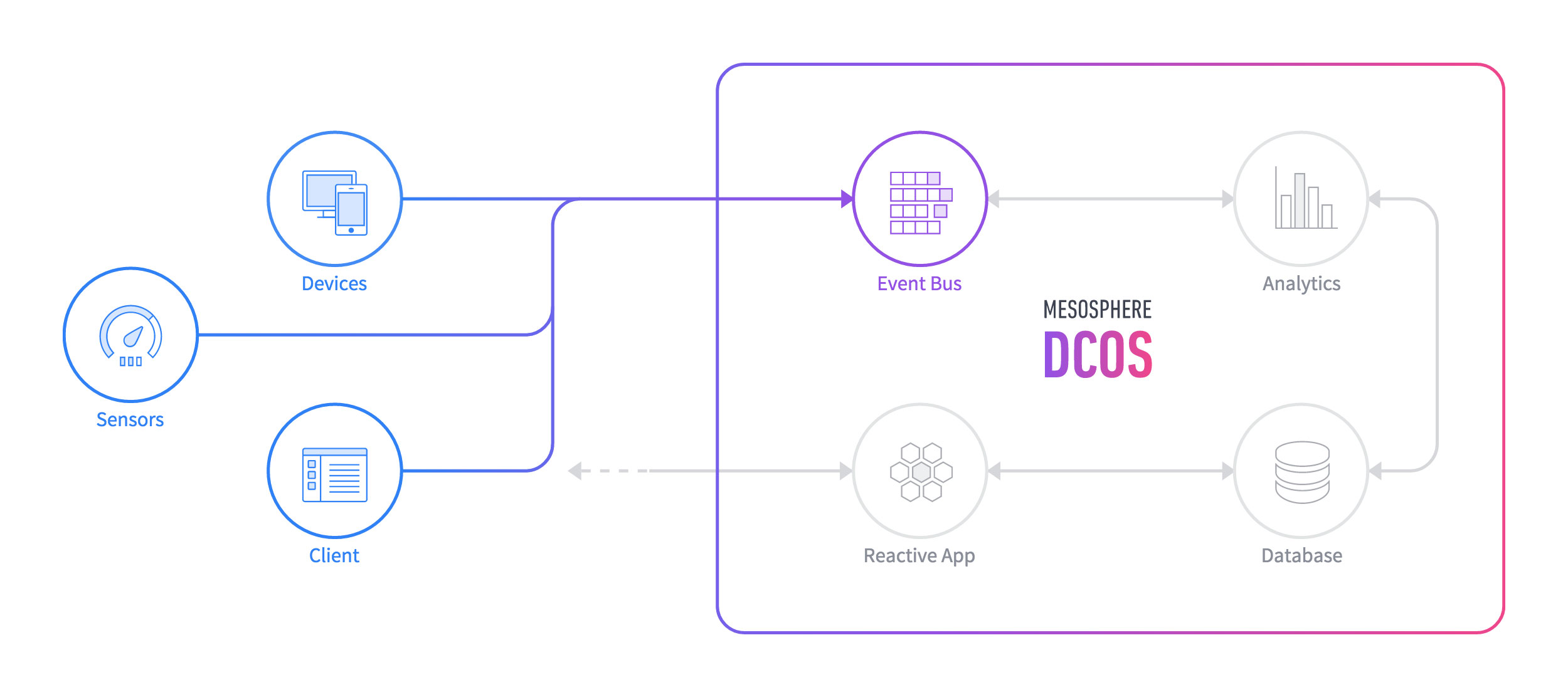
A high-level view of where the DCOS can run, what it provides, and the types of services that can share its resources.
Why building for the DCOS matters
Many readers probably also know that Mesosphere's DCOS is built around a kernel of Apache Mesos, which aggregates datacenter resources and manages the placement and scheduling for systems that run on it. Customized packages designed to take advantage of the multi-tenant, highly available nature of Mesos are called "frameworks" in the Mesos community. There is already a popular Kafka framework for Mesos, as well as frameworks for things including HDFS, Spark, Cassandra, Kubernetes, Jenkins and Mesosphere's Marathon container-orchestration engine.
While some of these frameworks, such as Marathon and Chronos, were developed specifically to run on Mesos, others include custom schedulers designed for Mesos. With distributed systems like Kafka and Cassandra, for example, these custom schedulers provide awesome benefits such as restarting tasks, performing rebalancing and handling many of the edge cases that emerge from running distributed systems in production.
When we port these frameworks to the DCOS, we call them "services," and we're often able to include additional capabilities because the DCOS is a complete software solution. It's a packaged set of open source components that take a fair amount of time and manpower to stitch together manually, as well as a collection of proprietary technologies to make everything easier to use and enterprise-ready out of the box. Think about the Mesos-DCOS relationship like the Linux-Android relationship, and think about DCOS services running across a datacenter full of servers like Android apps running on a single smartphone.
This is how we're able to launch big data services with ease on the DCOS, and to add the types of new functionalities we have added for Kafka and other DCOS frameworks.
We're just getting warm in big data
We're also pleased today to inform our customers that Kafka is just part of our mission to improve the big data experience on the DCOS. At the moment, we're also working on new, feature-rich versions of the HDFS and Cassandra DCOS services, which will be available in the months to come.
Furthermore, we are presently on pace to ship a beta version of our Infinity data-pipeline system in the second quarter of 2016. Infinity is a complete data pipeline solution consisting of Kafka, Spark, Cassandra and Akka. With a few simple steps, users will have an integrated system capable of handling the real-time data needs of next-generations applications—automatically installed and managed on the same cluster where they might already be running CI/CD environments, container-orchestration platforms and more.
If you're interested in learning more about any of these efforts, please let us know directly or check out what's available on our new-and-improved Docs site. And as they start coming online and you start using them, we'd love to hear your feedback about how we can make them even better. Advanced data-processing will be one of the defining features of tomorrow's enterprise and consumer applications, and we want to give our DCOS users the best platform to power them.


