






Jul 02, 2018
Benjamin Hindman
D2iQ

8 min read
We have chosen to sunset DC/OS, with an end-of-life date of October 31, 2021. With D2iQ Kubernetes Platform (DKP), our customers get the same benefits provided by DC/OS and more.
Learn more about D2iQ Kubernetes Platform here.
Learn more about D2iQ Kubernetes Platform here.
This is the recap of a DockerCon 18 talk and Bay Area Mesos User Group Meetup titled "Hybrid Cloud (Kubernetes, Spark, HDFS, …)-as-a-Service. DockerCon slides and Meetup slides are also online.
The overall container ecosystem is maturing to accommodate a growing variety of technologies, architectures, and use cases. At last year's DockerCon many attendees were asking, "how can we deploy Docker containers?". At this year's DockerCon the hot question was, "how can we operate Kubernetes-as-a-Service on-premise?". Our belief is that this trend will continue and next year attendees will be focused on answering "how can we operate Kubernetes or other open source frameworks of our choice, such as Apache Spark, TensorFlow, HDFS, and more, as a service across hybrid clouds?"
This reflects the larger trend that is taking place in systems architecture, an evolution from container orchestration to service orchestration. DevOps teams are hungry for service orchestration to manage the lifecycle of complex distributed systems in much the same way that container orchestration (e.g., Kubernetes or Marathon) manages the lifecycle of a container.
However, service orchestration comes with its own set of challenges. The lifecycle of distributed stateful services, with components running in many containers, is typically more complex compared to that of individual containers. In addition, while users often like the ease of cloud managed services, many still want the flexibility to switch between cloud providers, or to run in a hybrid cloud or multi-cloud architecture.
We will first look at why services are important and different from individual containers, then we will look at the challenges around Service Orchestration and then last at potential ways how we can solve these challenges.
Service Orchestration: What It Is and Why You Need It
In order to understand the importance of service orchestration, let's first take a look at why container orchestration itself is not sufficient to meet all of our needs.
Container orchestration is a great way to deploy microservices, but typically we need other services, for example distributed and often stateful systems such as Apache HDFS, Cassandra, Jenkins, or TensorFlow. Services often can be deployed in containers, but mostly consist of multiple different components that are more tightly coupled than microservices and often have requirements for persistence.
A typical environment must support many different services, each with its own set of dependencies. The number of services rapidly escalates, even for simple scenarios, in fact, especially when working in cloud environments where services (such as s3 storage) are simple to use, but might become expensive over time with large amounts of data).
Orchestrating multitudes of services through the entire service lifecycle in a high-availability and elastically scalable manner is no easy task.
Next, we'll dig into the example of the services required for a Continuous Integration / Continuous Deployment (CI/CD) pipeline, followed by a deep discussion of the challenges in service orchestration and show how DC/OS simplifies service orchestration.
Service Orchestration Example: CI/CD
The services required to operate a CI/CD infrastructure are a great example of the tangled web of complexity that are growing in datacenters and cloud providers every day.
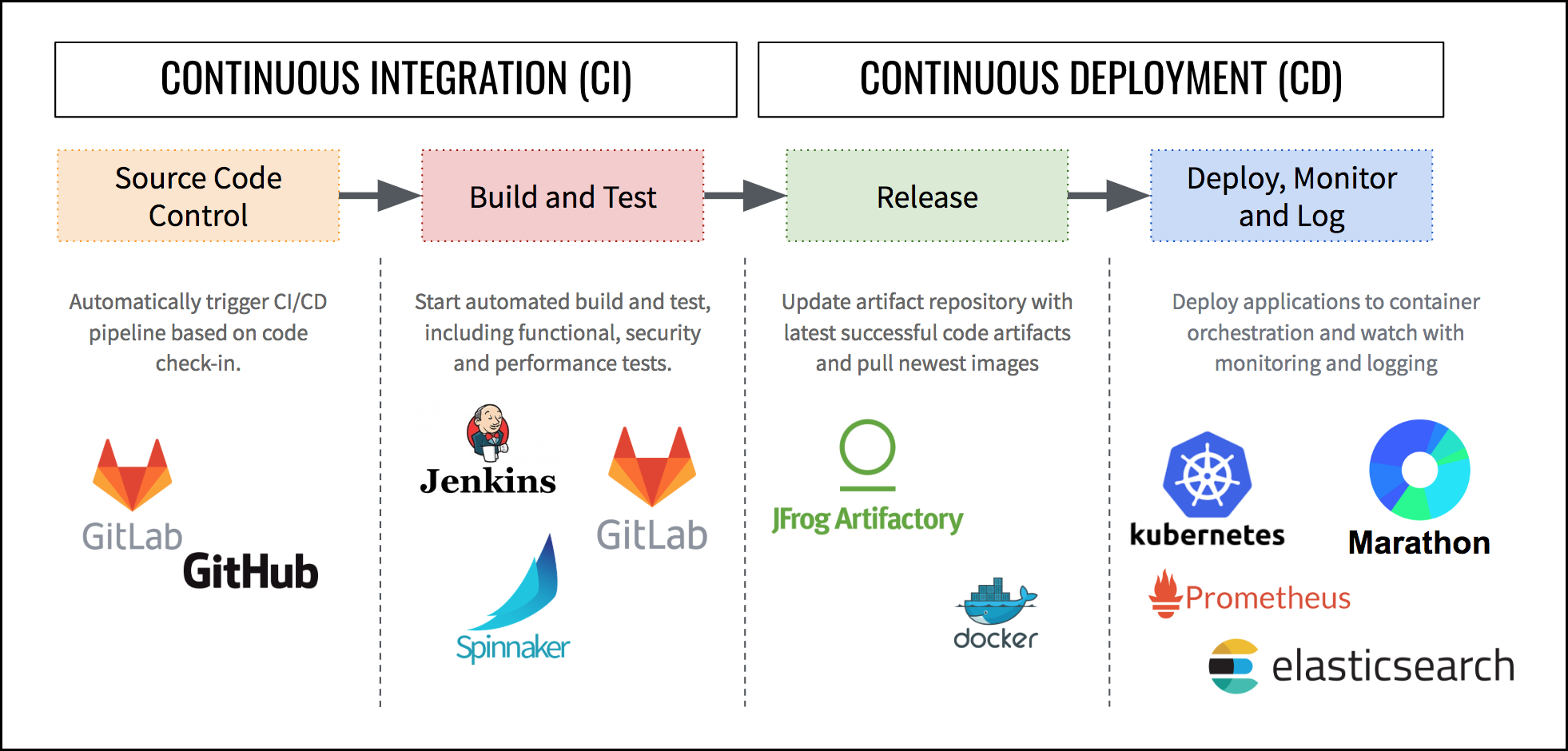
CI/CD is a critical cluster of services for managing applications across their lifecycle. CI/CD is core to DevOps and most developers are accustomed to working with at least a portion of these tools. The CI/CD process is worth understanding because it is widely implemented as a core component of well-run and efficient IT shops.
The services involved in a basic CI/CD setup include:
- Source Code Control: We need to store our source code somewhere, often times people use GitHub (being an external cloud service), but in case you want to keep the code in your own data center (e.g., for data privacy reasons) you might prefer GitLab for storing your code.
- Build and Test: After a developer has commited her code into the source code control system, we need a build and test pipeline to ensure the code meets quality criteria. Jenkins and/or Spinnaker are common tools here, but also GitLab offers support.
- Release Artifacts: After the code has been build, the artifacts need to be stored. Artifacts can be stored either as jars or binaries in a artifact store such as JFrog Artifactory or as a container image stored in a container image registry.
- Deploy, Monitor, and Log: Last, but not least, we need to serve and operate the build artifact. Here container orchestration tools such as Kubernetes and Marathon are very powerful options. In a production environment, you should also include additional services for logging and metrics, such as Prometheus and ElasticSearch.
As you can see, we need at least 4 to 6 different services to run a production-grade CI/CD pipeline. It's easy to see how the management burden of deploying, configuring, scaling, securing, patching, etc of every service quickly adds up. Without a service orchestration solution, the challenges of operating a multitude of services can outweigh the benefits.
Service Orchestration Challenges
Service orchestration faces challenges as the lifecycle of distributed stateful services is typically more complex compared to individual containers. Also, as we scale services, we need to consider the underlying resource utilization and infrastructure on which these services can be deployed.
Challenge 1: Complex Lifecycle Management
Services, especially distributed ones, can have complex deployment steps with multiple dependencies. Let's look at Kubernetes as an example: Did you ever setup a distributed HA Kubernetes cluster (and no, minikube does not count here ;))? Here are the deployment steps for Kelsey Hightower's Kubernetes the hard way:
1. Check Prerequisites
7. Bootstrapping the etcd Cluster… 3x for HA
10. Bootstrapping the Kubernetes Control Plane… 3x for HA
16. Deploying the DNS Cluster Add-on… Deploying other Add-ons
20. Smoke Test
21. Cleaning Up
These 21 steps are not the only challenges faced by Kubernetes operators. First, there is more to the service lifecycle than deployment (even if most demos choose to stop after a successful deployment). The operator also has to take care of upgrades, failures, configuration changes, scaling, and more. (DC/OS automates Kubernetes installation and management).
Container orchestration with stateless containers is an easier challenge to solve than for stateful services. For example, a failed container can simply be restarted on any node, but when dealing with stateful services, restarting just one component might impact other components (for example reshuffling data between nodes in the event that the component moves).
Secondly, as shown by the CI/CD pipeline example, there is not merely a single service, but many services, and each has its own peculiarities in terms of deployment, failure modes, monitoring, and so on.
The operator has to completely understand the nuances of a multitude of services and be able to fix issues on-the-fly when a node has failed. And since we all know that nodes can only fail at 3AM on Sunday morning...this is not a pleasant job.
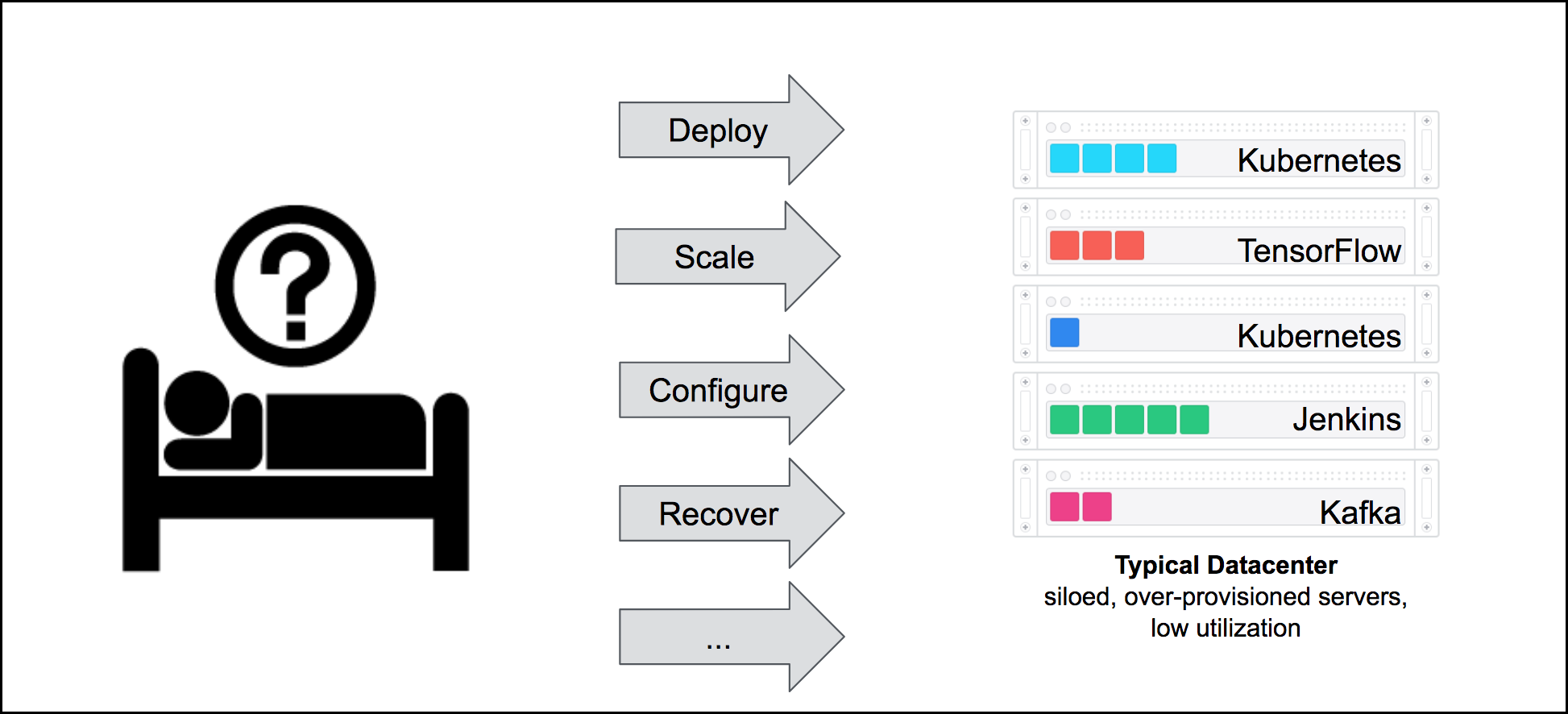
Challenge 2: Resource Allocation and Utilization
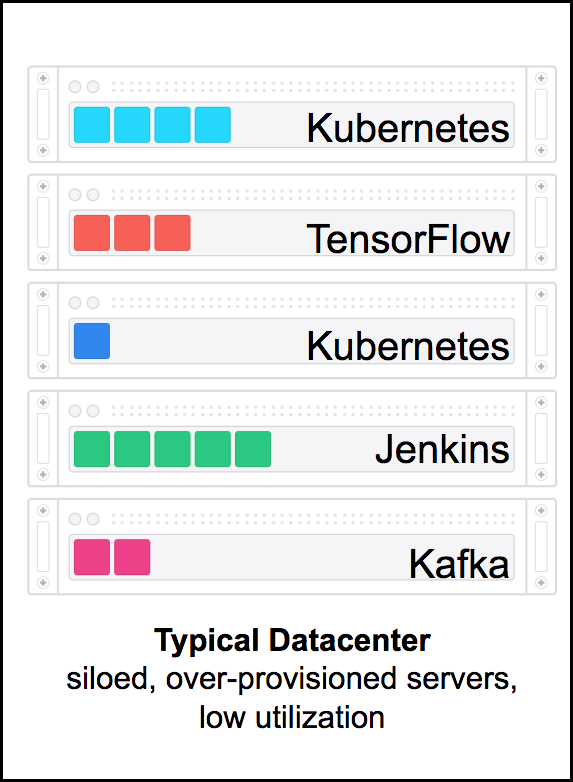
Deploying multiple distributed systems natively often also results in suboptimal resource utilization as we create silos, i.e., subsets of CPU, memory, disk, and network resources dedicated for each service. As each silo for these services is typically over-provisioned in order to account for the maximum load (e.g., Monday's between 8 and 9 AM when everyone is logging on we need 10 instances of a particular service, but rest of the week 2 instances would be sufficient).
Challenge 3: Multi-Tenancy
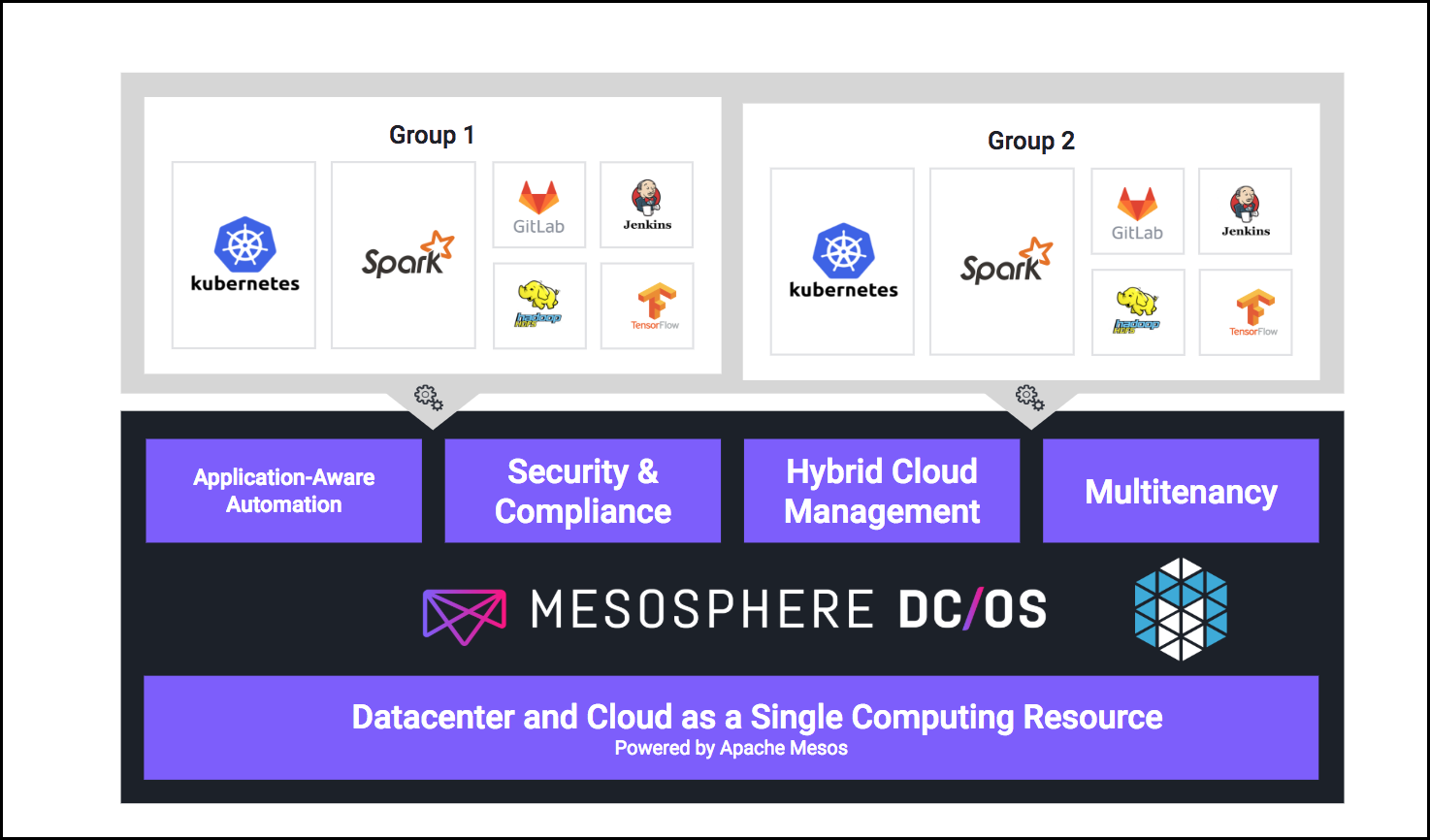
Deploying and operating that many services is already challenging enough, but what happens if we add multiple tenants, each with their own requirements and all isolated with security controls? Imagine multiple lines of business, each requiring a Kubernetes cluster and additional accompanying services as shown below:
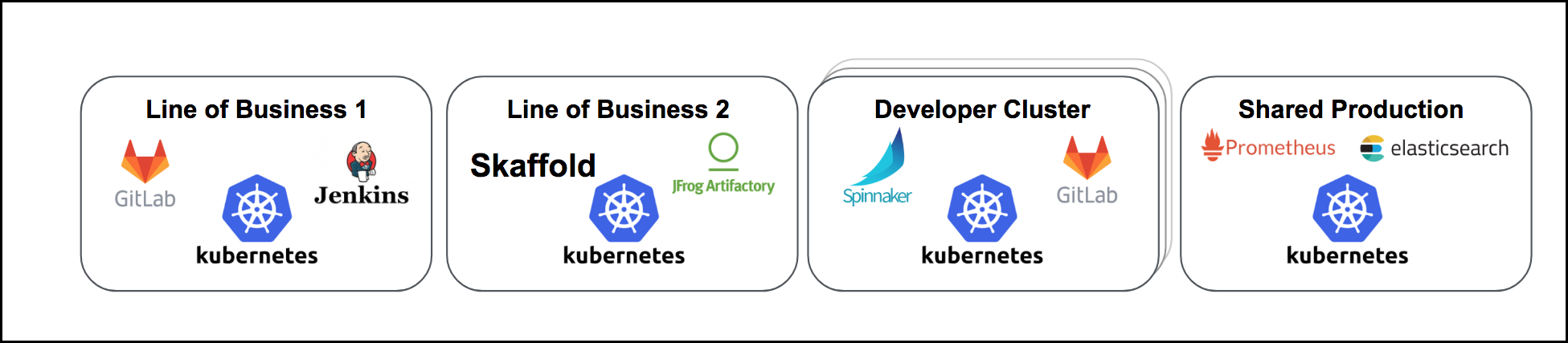
This raises a number of questions, such as "How can we make sure one tenant cannot take over all resources in the cluster and impact the performance of the other tenants?" or "How we make sure each tenant can only access her respective services including metrics, logs and other metadata?".
Challenge 4: Infrastructure
Many of the most popular services are offered by cloud providers proprietary managed services, but most IT leaders can't stomach the risk of being tied to a specific vendor's cloud API as it prevents moving to another cloud or on-prem data center. Others might not even be allowed to move all their data into the cloud due to data privacy and governance requirements.
Many organizations also need to have the services run across different data centers (or clouds). Imagine, for example, running the base workload on-prem, but having the need to add burst compute resources in the cloud. Yet another use case could a shared setup across multiple AWS regions for fault tolerance.
How can we develop and deploy our services independent of the underlying infrastructure regardless of what it is and where it resides (in our datacenter, across multiple datacenters, across public and private clouds)?
Service Orchestration with DC/OS
In order to provide efficient Service Orchestration we need two main things:
- Resource Abstraction and Cluster Management: We need to abstract away the underlying infrastructure to achieve good resource utilization and not be dependent on a particular cloud provider.
- Software-based Service Operations: Managing the complete lifecycle for many different services can be a challenging task for an operator. It is therefore imperative to automate as much as possible and encode operational knowledge into software components.
This can be done practically using DC/OS.
In case you don't know what DC/OS is, here the short definition from dcos.io:

Let us see how this helps us with the above challenges of Service Orchestration:
Solution 1: Complex Lifecycle Management
Apache Mesos (and therefore DC/OS) makes heavy use of the concept of schedulers, each service (aka framework) has its own scheduler which controls (e.g., launch, stop) tasks and reacts to failures or updated.
For example, it is easy for a scheduler to respect certain deployment dependencies as shown below. For HDFS, we first have to deploy the journal nodes, then the namenodes, and then the data nodes. Also, the scheduler is responsible for the entire lifecycle, so it also needs to dynamically react to failures and configuration changes, and be able to upgrade the respective service. Note that, especially in distributed systems, there errors can occur at any point in time.
For that reason it is good practice to implement a scheduler as state machines (If you consider building one of those services yourself, you should take a look at the DC/OS SDK which greatly simplifies the creation of such state machines.) where the scheduler tries to achieve or maintain a certain goal state. You can visualize such a state machine as a continuous loop, always checking system state and then moving towards the goal state if required. Note that the plan towards the goal state might require some extra steps (i.e., it is not simply starting or stopping tasks). For example, if in the HDFS scheduler both namenodes fail simultaneously, then the scheduler has to first recover the state from the namenodes before it can restart the namenodes.
There is already a large repository of schedulers and services developed by Mesosphere, partners, and the community available in the which can be deployed with two simple clicks.
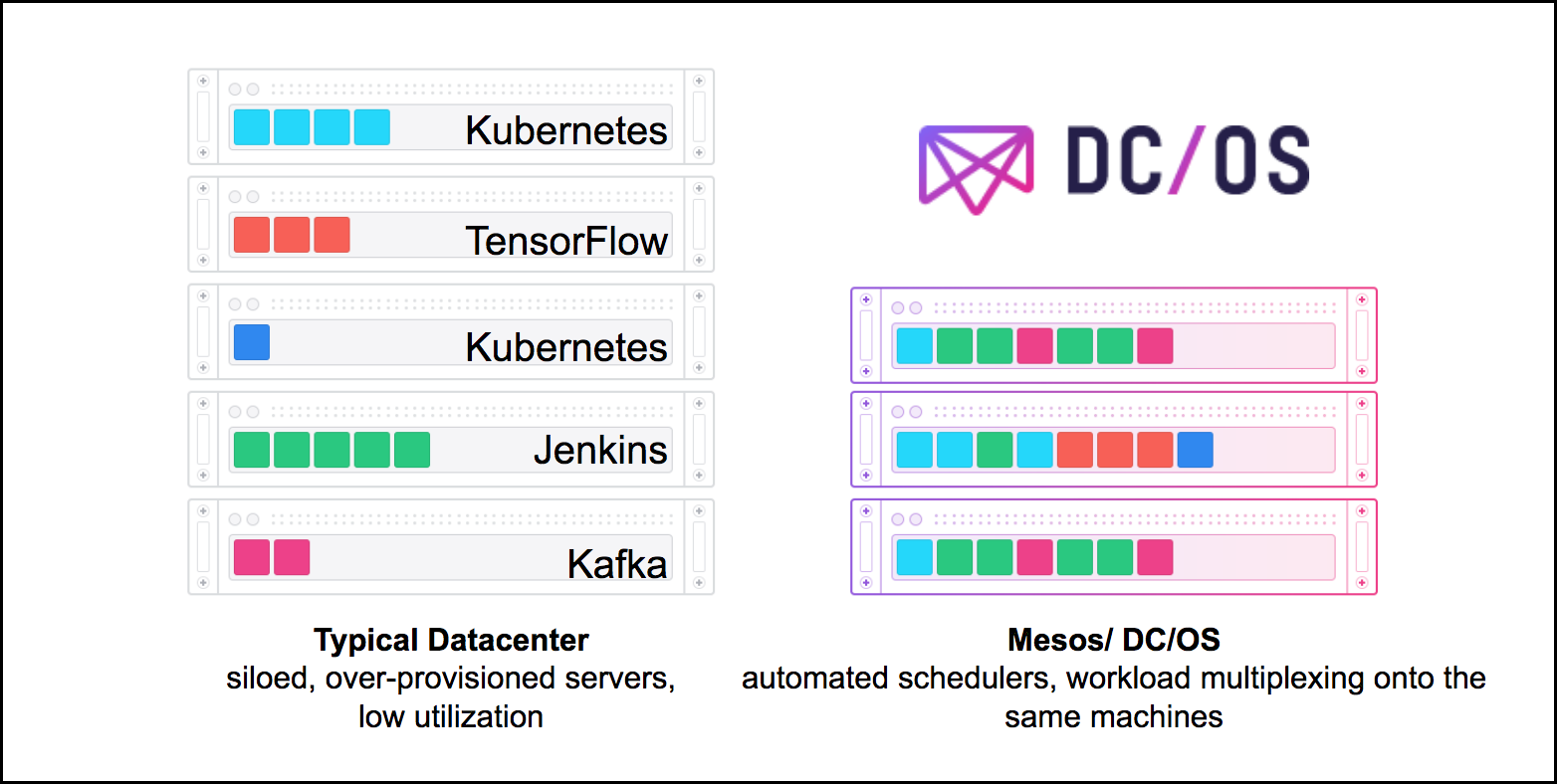
Solution 2: Resource Allocation and Utilization
As DC/OS is built with Apache Mesos at its core, it basically considers resources from different nodes as one big resource pool. The operator/user only needs to specify "We need 10 instances on disjointed nodes" and DC/OS will take care of scheduling all of those tasks. This typically results in a better resource utilization than manual management.
Solution 3: Multi-Tenancy
The same flexibility DC/OS provides in terms of the underlying infrastructure, it also provides for the services running on top it so we can provide multiple instances of the same service for multiple teams. This is helpful, for example, when one development team is using one version of a service and another is using a different version.
Mesosphere DC/OS includes security features that make user authentication and authorization in multi-tenant scenarios simple, and isolates environments from each other.
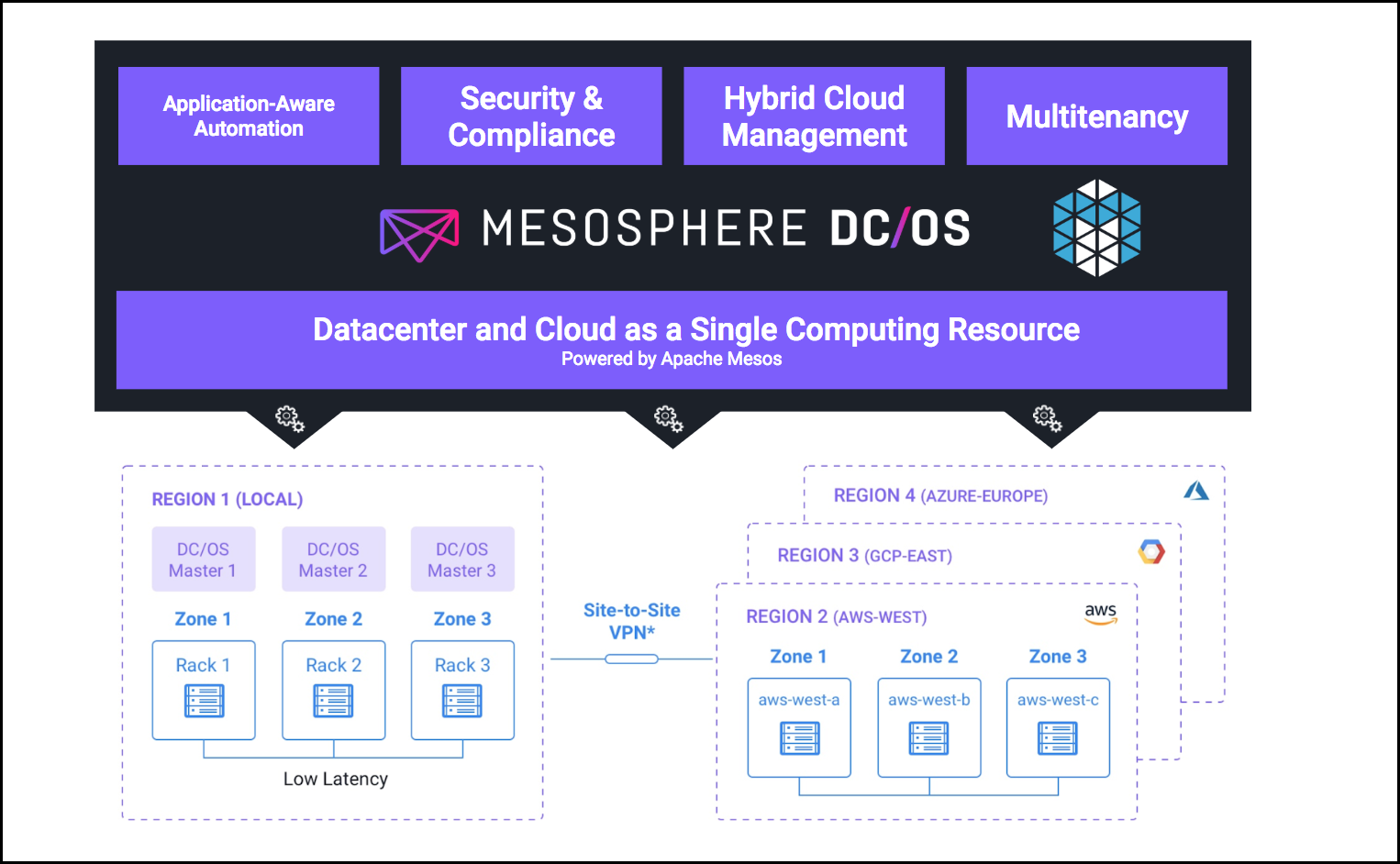
Solution 4: Infrastructure
Furthermore, the resource abstraction provided by DC/OS makes the services independent of the underlying datacenter and helps to avoid lock-in to a particular cloud provider API. Also, hybrid cloud use cases become possible as shown below.
Why not use Kubernetes for Service Orchestration?
Note: The following answer is as of summer 2018 and might look different in summer 2019!
Kubernetes was primarily designed to orchestrate stateless containers, which as we have seen earlier is vastly different from service orchestration.
The recent improvements towards supporting stateful workloads with persisting volumes and operators (the Kubernetes version of schedulers) is impressive, but, as of today, even Kelsey Hightower, Staff Developer Advocate for Kubernetes, would not run his stateful services on Kubernetes.
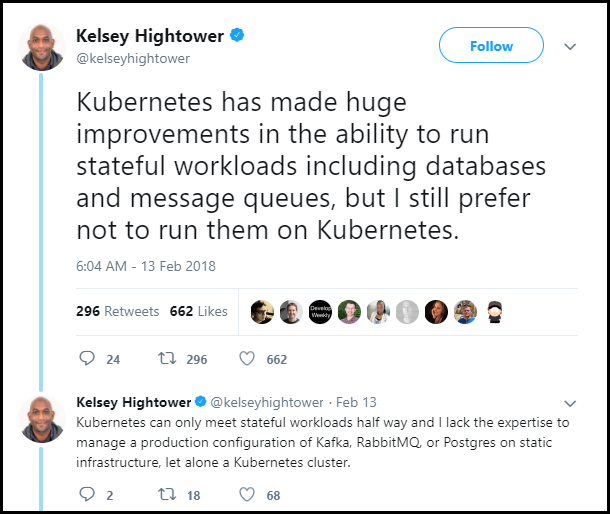
One the main challenges here is (at least in our personal opinion :) ) that writing operators (and schedulers for that) is not an easy task, especially for stateful services (check out this MesosCon talk for more details on the challenges and the DC/OS SDK). The DC/OS community has worked hard to implement best practices into the DC/OS SDK and it is great to see similar efforts being sparked in the Kubernetes community. We are really looking forward to revisit this question next year.
Service Orchestration with DC/OS
Service orchestration allows us to manage complex distributed systems as easily as we currently manage individual containers, but requires a scheduler (or operators in the Kubernetes ecosystem) to manage complex lifecycles which typically differ quite a bit between services.
Furthermore, despite the growth of managed service offerings by various cloud providers, many users still want (or are even required) to run services independent of a particular cloud provider without missing the comfort of a managed service.
DC/OS helps by first abstracting away the underlying infrastructure and enables hybrid cloud use cases that leverage the benefits of both on-prem datacenter and public cloud resources. DC/OS simplifies the complex tasks of service orchestration to enable technical and business teams to run the services they need without prohibitive operational overhead.


