Apr 17, 2018
Joerg Schad
D2iQ

10 min read
DC/OS provides a platform for running complex distributed systems both for Big Data applications and also custom containerized applications. But what happens if your application keeps failing? Debugging in distributed systems is always difficult and while DC/OS provides a number of tools for debugging it might be difficult to choose which of these tools to apply in which situation.
This blog post aims at providing an overview to debugging applications and their deployments on DC/OS.
Please note, debugging is a wide topic and certainly beyond the scope of a single blog post. Therefore this blog post does not claim to be exhaustive, but rather should serve as a starting point. We would love to get your feedback on issues you have debugged yourself and tools/ strategies you like to use for debugging. The DC/OS community (Slack and/or Mailing list) is a good place to provide feedback and ask questions.
You should have a working knowledge of DC/OS in order to complete this tutorial. There are plenty of tutorials to get you up and running with DC/OS.
Expecting failures and preparing for it, is probably to most important tip for working with distributed system (and as such also a design criteria for DC/OS). So a few of the most important steps are - hopefully - happening before the actual debugging:
- Design your applications for debuggability
- Follow best practices for deployments
- Set up monitoring and alerts so you can resolve issues as early as possible
This blog post is structured as follows: We will first look at potential problems you might face, next we will look at the standard set of tools for debugging, and then discuss a general strategy of how to apply all those different tools.
After that we have some concrete examples. We encourage everyone to first try debugging these yourself, but don't worry, we also provide detailed guidance for debugging them.
Potential Application Problems
As mentioned previously, the range of problems that can be encountered and require debugging is far too large to be covered in a single blog-post. Some of the problems that may need troubleshooting on DC/OS include applications:
- Not deploying at all
- Deploying very slowly
- Deploying but do not start correctly (or behave incorrectly)
- Restarting repeatedly
- Not being reachable inside (or outside) of the DC/OS cluster
DC/OS consists of a number of different components most notably Apache Mesos and Marathon. As each of these components could be involved in the issue you are seeing, it might be difficult to even locate the component causing your issue. But don't worry, this blog provides the guidance you need when approaching a variety of issues.
Besides application failures, there are a myriad of other potential issues such as networking problems, DC/OS installation issues, and DC/OS internal issues that could affect your cluster. These are unfortunately out of scope for this blog post, and we encourage you to reach out via our Community channels with ideas and feedback to shape follow-up blog-posts.
Tools for Debugging on DC/OS
DC/OS comes with a number of tools for debugging. In this section we will try to provide an overview of the relevant tools for application debugging.
In particular we discuss:
Different DC/OS UIs
DC/OS provide a set of different UIs for different components, for application debugging these ones are the most relevant one:
- DC/OS UI
- Mesos UI
- Zookeeper/Exhibitor UI
The DC/OS UI is a great place to start debugging as it provides quick access to:
- Cluster Resource Allocation to provide an overview of available cluster resources
- Task Logs to provide insight into tasks failures
- Task Debug Information about the most recent task offers and why a task didn't start
Despite the DC/OS UI showing most of the information that you'd need for debugging, sometimes accessing the Mesos UI itself can be helpful, for example when checking failed tasks or registered frameworks. The Mesos UI can be accessed via https://<cluster>/mesos.
As much of the cluster and framework state is stored in Zookeeper, it can be helpful to check its state. This can be done by using Exhibitor UI via https://<cluster>/exhibitor. This is particularly helpful as frameworks such as Marathon, Kafka, Cassandra, and many store information in Zookeeper. A failure during uninstall of one of those frameworks might leave some entries behind, so if you experience difficulties when reinstalling a framework you have uninstalled earlier, this UI is likely to be worth checking.
Logs
Logs are useful tools to see events and conditions that occurred before the problem. Very often logs include error messages that shed light on the cause of the error. As logging is an important topic, we also recommend to have a look at the DC/OS logging documentation, for more information.
DC/OS has a number of different sources for logs, including these which we will look at more detail below:
- Tasks/Applications
- Mesos Agents
- Mesos Master
- Service Scheduler (e.g., Marathon)
- System Logs
DC/OS unifies these different logs and makes them accessible via different options: the DC/OS UI, the DC/OS CLI, or HTTP endpoints. Also logs are log-rotated by default in order to avoid filling all available disk space.
If you require a scalable way to manage and search your logs it might be worth building an ELK stack for log aggregation and filtering.
Also, as with other systems, in some cases it is helpful to increase the level of detail written to the log temporarily to obtain detailed troubleshooting information. For most components this can be done by an endpoint, for example when you want to increase the log level of a Mesos Agent for the next 5 minutes:
# connect to master node
$ dcos node ssh --master-proxy --leader
# raise log level on Mesos agent 10.0.2.219
$ curl -X POST 10.0.2.219:5051/logging/toggle?level=3&duration=5mins
Task/Application Logs
Application logs are often helpful in understanding the state of the application.
By default applications logs are written (together with execution logs) to the STDERR and STDOUT files in the task workdirectory. When looking at the task in the DC/OS UI you can just simply view the logs as shown below. You can also do the same from the DC/OS CLI: dcos task log --follow <service-name>
Scheduler/Marathon Logs
Recall that the scheduler matches tasks to available resources and our default scheduler when starting an application container is Marathon. Scheduler logs, and Marathon logs in particular, are a great source of information to help you understand why and how something was scheduled (or not) on which node. The scheduler also receives task status updates, so the log also contains detailed information about task failures.
You can retrieve and view a scheduler log about a specific service through the list of services found in the DC/OS UI, or via the following command:
dcos service log --follow <scheduler-service-name>
Note that as Marathon is the "Init" system of DC/OS and hence is running as SystemD unit (same of the other system components), you need the CLI command to access its logs.
Mesos Agent Logs
Mesos agent logs are a helpful tool for understanding how an application was started by the agent and also why it might have failed. You can launch the Mesos UI using https://<cluster_name>/mesos and examine the agent logs as shown below, or use dcos node log --mesos-id=<node-id> from the DC/OS CLI, where you can find the corresponding node-iddcos node:
$ dcos node
HOSTNAME IP ID TYPE
10.0.1.51 10.0.1.51 ffc913d8-4012-4953-b693-1acc33b400ce-S3 agent
10.0.2.50 10.0.2.50 ffc913d8-4012-4953-b693-1acc33b400ce-S1 agent
10.0.2.68 10.0.2.68 ffc913d8-4012-4953-b693-1acc33b400ce-S2 agent
10.0.3.192 10.0.3.192 ffc913d8-4012-4953-b693-1acc33b400ce-S4 agent
10.0.3.81 10.0.3.81 ffc913d8-4012-4953-b693-1acc33b400ce-S0 agent
master.mesos. 10.0.4.215 ffc913d8-4012-4953-b693-1acc33b400ce master (leader)
$ dcos node log --mesos-id=ffc913d8-4012-4953-b693-1acc33b400ce-S0 --follow
2018-04-09 19:04:22: I0410 02:38:22.711650 3709 http.cpp:1185] HTTP GET for /slave(1)/state from 10.0.3.81:56595 with User-Agent='navstar@10.0.3.81 (pid 3168)'
2018-04-09 19:04:24: I0410 02:38:24.752534 3708 logfmt.cpp:178] dstip=10.0.3.81 type=audit timestamp=2018-04-10 02:38:24.752481024+00:00 reason="Valid authorization token" uid="dcos_net_agent" object="/slave(1)/state" agent="navstar@10.0.3.81 (pid 3168)" authorizer="mesos-agent" action="GET" result=allow srcip=10.0.3.81 dstport=5051 srcport=56595
Mesos Master
The Mesos Master is responsible for matching available resources to the scheduler and also forwards task status updates from the Agents to the corresponding scheduler. This makes the Mesos Master logs a great resource for understanding the overall state of the cluster.
Please be aware that typically there are (or at least should be in an HA setup) multiple Mesos Masters and you should identify the currently leading Master to get the most up-to-date logs (in some cases it might make sense to retrieve logs from another Mesos master as well, e.g., a master node has failed over and you want to understand why).
You can either retrieve the Master logs from the Mesos UI via <cluster-name>/mesos, via dcos node log --leader, or for a specific master node by ssh master and journalctl -u dcos-mesos-master.
System Logs
We've focused on the most important log sources in the DC/OS environment, and there are many more logs available. Every DC/OS component writes a log. For example each DC/OS component is running as one systemd unit for which you can retrieve the logs directly on the particular node by accessing that node via SSH and then typing journalctl -u <systemd-unit-name>. In my experience the two most popular system units considered during debugging (besides Mesos and Marathon) are the docker.service and the dcos-exhibitor.service.
As an example, let's consider the system unit for the docker daemon on the Mesos agent ffc913d8-4012-4953-b693-1acc33b400ce-S0 (recall the dcos node command retrieves the Mesos ID).
First we connect to that agent via SSH using the corresponding SSH key:
dcos node ssh --master-proxy --mesos-id=ffc913d8-4012-4953-b693-1acc33b400ce-S0
Then we use journatlctl to look at the Docker logs:
$ journalctl -u docker
-- Logs begin at Mon 2018-04-09 23:50:05 UTC, end at Tue 2018-04-10 02:52:41 UTC. --
Apr 09 23:51:50 ip-10-0-3-81.us-west-2.compute.internal systemd[1]: Starting Docker Application Container Engine...
Apr 09 23:51:51 ip-10-0-3-81.us-west-2.compute.internal dockerd[1262]: time="2018-04-09T23:51:51.293577691Z" level=info msg="Graph migration to content-addressability took 0.00 seconds"
Metrics
Metrics are useful because they help identify problems before they become problems. Imagine a container using up all allocated memory and you can detect that while it is running but before it gets killed.
In DC/OS there are three main endpoints for metrics:
- DC/OS metrics endpoint exposing combined metrics from tasks/container, nodes, and applications
- Mesos metrics endpoint exposing Mesos specific metrics
- Marathon metrics exposing Marathon specific metrics
The best way to leverage metrics for debugging is to set up a dashboard with the important metrics related to the services you want to monitor, for example using prometheus and grafana. In the best case, you can detect problems before they become issues. In case of issues such a dashboard can be extremely helpful in detecting the cause (for example, the cluster has no free resources). For each of the endpoint, the above links include recommendations for the metrics you should monitor.
Debugging tasks interactively
If the tasks logs are not helpful, then you may want use your favorite Linux tools (e.g., curl, cat, ping, etc) to understand what's going on inside the application. You can use dcos task exec if you are using Universal Container Runtime (UCR) or SSH into the node and use docker exec if your are using the docker containerizer. For example dcos task exec -it <mycontainerid> bash gives you an interactive bash shell inside that container.
If you alter the state of the container, you must update the stored app-definition and restart the container from the updated app-definition. Otherwise your changes will be lost the next time the container restarts.
HTTP Endpoints
DC/OS has a large number of additional endpoints. Here are some of the most useful ones for debugging:
- <cluster>/mesos/master/state-summary
This endpoint gives you a json encoded summary of the agents, tasks, and frameworks inside the cluster. This is especially helpful when looking at the different resources as it shows you whether there are reserved resources for a particular role (we will see more details of this in one of the Hand-On exercises). Here is the complete list of Mesos endpoints.
- <cluster>/marathon/v2/queue
This endpoint lists all tasks in the queue to be scheduled by Marathon. This endpoint is valuable when troubleshooting scaling or deployment problems.
Community
The DC/OS community is a great place to ask additional questions either via slack or the mailing list. Keep in mind that both Mesos and Marathon have their own communities in addition to the DC/OS community.
Other Tools
There are other debugging tools as well, both inside DC/OS as well as external tools such as Sysdig or Instana. These tools can be especially helpful in determining non DC/OS specific issues, e.g., Linux Kernel or networking problems.
Debugging on DC/OS Strategy
At this point, you're probably thinking "That's a great set of tools, but how do I know which tool to apply for any given problem?"
First, let's take a look at a general strategy for troubleshooting on DC/OS. Then, let's dive into some more concrete examples of how to apply this strategy in the hands-on section below.
If there is no additional information, a reasonable approach is to consider the potential problem sources in the following order:
Task Logs
Start by examining the UI (or use the CLI) to check the status of the task.
If the task defines a health check, it's also a good idea to check the task's health status.
Next, checking the task logs, either via the DC/OS UI or the CLI, helps us to understand what might have happened to the application. If the issue is related to our app not deploying (i.e., the task status is waiting) looking at the Debug UI might be helpful to understand the resources being offered by Mesos.
Scheduler
If there is a deployment problem, it can be helpful to double check the app definition and then check the Marathon UI or log to figure out how it was scheduled or why not.
Mesos Agent
The Mesos Agent logs provide information regarding how the task (and its environment) is being started. Recall that increasing the log level might be helpful in some cases.
Task Interactive
The next step is to interactively look at the task running inside the container. If the task is still running dcos task exec or docker exec are helpful to start an interactive debugging session. If the application is based on a Docker container image, manually starting it using docker run and then using docker exec can also be helpful.
Mesos Master
If you want to understand why a particular scheduler has received certain resources or a particular status, then the master logs can be very helpful. Recall that the master is forwarding all status updates between the agents and scheduler, so it might even be helpful in cases where the agent node might not be reachable (for example, network partition or node failure).
Community
As mentioned above, the community, either using the DC/OS slack or the mailing list can be very helpful in debugging further.
Debugging DC/OS Hands-on
Now it's time to apply our new knowledge and start debugging! We encourage you to try to solve these exercises by yourself before skipping to the solution.
Note that these exercises require a running DC/OS cluster and a configured DC/OS CLI. Please note that we are using a cluster with 4 private and 1 public agents that is not running any workloads prior to this challenge, hence your results may vary if you have a different cluster setup.
Debugging DC/OS Challenge 1: Resources
Setup
For challenge 1 please deploy the following app definition:
$ dcos marathon app add https://raw.githubusercontent.com/dcos-labs/dcos-debugging/master/1.10/app-scaling1.json
If you check the app status using the DC/OS UI you should see something similar to this, with the Status most likely to be "Waiting" followed by a different number "x/1000". Waiting refers to the overall application status and the number represents how many instances have successfully deployed.
You can also check this status from the CLI:
dcos marathon app list
ID MEM CPUS TASKS HEALTH DEPLOYMENT WAITING CONTAINER CMD
/app-scaling-1 128 1 6/1000 --- scale True mesos sleep 10000
Or if you want to see all ongoing deployments:
dcos marathon deployment list
APP POD ACTION PROGRESS ID
/app-scaling-1 - scale 1/2 c51af187-dd74-4321-bb38-49e6d224f4c8
Now we know that some (6/1000) instances of the application have successfully deployed, but the overall deployment status is "Waiting". What does that mean?
Resolution
The "Waiting" state means that DC/OS (or more precisely Marathon) is waiting for a suitable resource offer. So it seems to be an deployment issue and we should start by checking the available resources.
If we look at the DC/OS dashboard we should see a pretty high CPU allocation similar to the following (exact percentage depends on your cluster):
Since we are not yet at 100% allocation, but we are still waiting to deploy, let's look at the recent resource offers in the debug view of the DC/OS UI.
We can see that there are no matching CPU resources, but we recall that the overall CPU allocation was only at 75%. Let's look at the Details further below:
Here we can see how the latest offers from different host match the resource requirements of our app. So for example the first offer coming from Host 10.0.0.96 matched the Role, Constraint (not present in this app definition), Memory, Disk, and Port resource requirements but failed the CPU resource requirements. The last offer also seems to have the resource requirements, let us understand that means exactly by looking at this offer in more detail.
So some of the remaining CPU resources are in a different Mesos resource role and hence cannot be used by our application which runs in role * (which is the default role).
To check the roles of different resources let us have a look at the state-summary endpoint which you can access under https://<master-ip>/mesos/state-summary.
That endpoint will give us a rather long json output, so it is helpful to use jq to make the output readable.
curl -skSL
-X GET
-H "Authorization: token=$(dcos config show core.dcos_acs_token)"
-H "Content-Type: application/json"
"$(dcos config show core.dcos_url)/mesos/state-summary" |
jq '.'
When looking at the agent information we can see two different kind of agents.
The first kind has no free CPU resources and also no reserved resources, although this might be different if you had other workloads running on your cluster prior to these exercises. Note that these unreserved resources correspond to the default role "*" in which we are trying to deploy our tasks.
The second kind has unused CPU resources, but these resources are reserved in the role "slave_public".
We now know that the issue is that there are not enough resources in the desired resource role across the entire cluster. As a solution we could either scale down the application (1000 instances does seem a bit excessive), or we need to add more resources to the cluster.
General Pattern
If the framework for your app (e.g. Marathon) is not accepting resource offers you should check whether there are sufficient resources available in the respective resource role.
This was a straightforward scenario with too few CPU resources. Typically resources issues are more likely to be caused by more complex issues such as improperly configured port resources or placement constraints.
Cleanup
Remove the app with
dcos marathon app remove /app-scaling-1
Debugging DC/OS Challenge 2: Out-Of-Memory
Setup
Deploy the file app-oom.json:
dcos marathon app add https://raw.githubusercontent.com/dcos-labs/dcos-debugging/master/1.10/app-oom.json
Let's take a look at the DC/OS UI. We see some strange results under CPU Allocation:
How is it that CPU Allocation is oscillating? Let's take a look at the app details in the UI:
It looks like our app runs for a few seconds and then fails. Let's find out why.
Resolution
Let's start by looking at the app logs, either in the UI or via the CLI. You can find the app logs in the UI by :
The log output "Eating Memory" is a pretty generous hint that the issue might be related to memory, but there is no direct failure message (and you should keep in mind that most apps are not as friendly as to log that they are eating up memory ;) ).
As we suspect this might be an application-related issue, and this app is scheduled via marathon, let's check the marathon logs using the CLI:
dcos service log marathon
One helpful time saving-tip is to grep for "TASK_FAILED". We see a log entry similar to:
Mar 27 00:46:37 ip-10-0-6-109.us-west-2.compute.internal marathon.sh[5866]: [2018-03-27 00:46:36,960] INFO Acknowledge status update for task app-oom.4af344fa-3158-11e8-b60b-a2f459e14528: TASK_FAILED (Memory limit exceeded: Requested: 64MB Maximum Used: 64MB
Now we know that we exceeded the container memory limit we had set here.
If you've been paying close attention you might shout now "wait a sec" because you noticed that the memory limit we set in the app definition is 32 MB, but the error message mentions 64MB. DC/OS automatically reserves some overhead memory for the executor which in this case is 32 MB.
Please note that OOM kill is performed by the Linux kernel itself, hence we can also check the kernel logs directly:
dcos node ssh --master-proxy --mesos-id=$(dcos task app-oom --json | jq -r '.[] | .slave_id')
journalctl -f _TRANSPORT=kernel
Mar 27 01:15:36 ip-10-0-1-103.us-west-2.compute.internal kernel: [ pid ] uid tgid total_vm rss nr_ptes nr_pmds swapents oom_score_adj name
Mar 27 01:15:36 ip-10-0-1-103.us-west-2.compute.internal kernel: [16846] 0 16846 30939 11021 62 3 0 0 mesos-container
Mar 27 01:15:36 ip-10-0-1-103.us-west-2.compute.internal kernel: [16866] 0 16866 198538 12215 81 4 0 0 mesos-executor
Mar 27 01:15:36 ip-10-0-1-103.us-west-2.compute.internal kernel: [16879] 0 16879 2463 596 11 3 0 0 sh
Mar 27 01:15:36 ip-10-0-1-103.us-west-2.compute.internal kernel: [16883] 0 16883 1143916 14756 52 6 0 0 oomApp
Mar 27 01:15:36 ip-10-0-1-103.us-west-2.compute.internal kernel: Memory cgroup out of memory: Kill process 16883 (oomApp) score 877 or sacrifice child
Mar 27 01:15:36 ip-10-0-1-103.us-west-2.compute.internal kernel: Killed process 16883 (oomApp) total-vm:4575664kB, anon-rss:57784kB, file-rss:1240kB, shmem-rss:0kB
Mar 27 01:15:36 ip-10-0-1-103.us-west-2.compute.internal kernel: oom_reaper: reaped process 16883 (oomApp), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
The resolution in such cases is to either increase the resource limits for that container, in case it was configured too low to begin with. Or, as in this case, fix the memory leak in the application itself.
General Pattern
As we are dealing with a failing task it is good to check the application and scheduler logs (in this case our scheduler is Marathon). If this isn't sufficient it can help to look at the Mesos Agent logs and/or to use dcos task exec when using UCR (or ssh to the node and use docker exec when using the Docker containerizer).
Cleanup
Remove the app with
dcos marathon app remove /app-oom
Debugging DC/OS Challenge 3: Docker Images
Setup
Deploy the file dockerimage.json:
dcos marathon app add https://raw.githubusercontent.com/dcos-labs/dcos-debugging/master/1.10/dockerimage.json
We see the app failing almost immediately:
Resolution
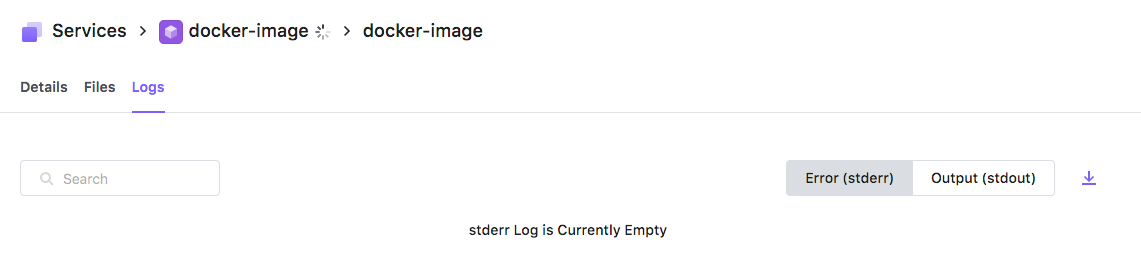
As we learned before, with app failures the first step is to check the task logs.
Unfortunately, this is completely empty. Normally we would at least see some output from the setup of the task. What could be happening?
Let's look at the scheduler (i.e., marathon logs):
dcos service log marathon
Mar 27 21:21:11 ip-10-0-5-226.us-west-2.compute.internal marathon.sh[5954]: [2018-03-27 21:21:11,297] INFO Received status update for task docker-image.c4cdf565-3204-11e8-8a20-82358f3033d1: TASK_FAILED (
Mar 27 21:21:11 ip-10-0-5-226.us-west-2.compute.internal marathon.sh[5954]: ') (mesosphere.marathon.MarathonScheduler:Thread-1723)
Unfortunately, this doesn't shed much light on why the task failed. Let's look at the mesos-agent logs:
dcos node log --mesos-id=$(dcos task docker-image --json | jq -r '.[] | .slave_id') --lines=100
8-4520-af33-53cade35e8f9-0001 failed to start: Failed to run 'docker -H unix:///var/run/docker.sock pull noimage:idonotexist': exited with status 1; stderr='Error: image library/noimage:idonotexist not found
2018-03-27 21:27:15: '
2018-03-27 21:27:15: I0327 21:27:15.325984 4765 slave.cpp:6227] Executor 'docker-image.9dc468b5-3205-11e8-8a20-82358f3033d1' of framework 6512d7cc-b7f8-4520-af33-53cade35e8f9-0001 has terminated with unknown status
It looks like the specific Docker image could not be found, perhaps because it doesn't exist. Does the image exist in the specified location (in this case noimage:idonotexist in dockerhub)? If not, you will have to correct the location or move the file to the specified location. Was there an error in the location or filename specified? Also, check whether the container image registry (especially when using a private registry) is accessible.
General Pattern
Being an application error, we again start by looking at task logs, followed by scheduler logs.
In this case we have a Docker daemon-specific issue. Many such issues can be uncovered by examining the Mesos Agent logs. In some cases, where we need to dig deeper, accessing the Docker daemon logs is required:
$dcos node ssh --master-proxy --mesos-id=$(dcos task --all | grep docker-image | head -n1 | awk '{print $6}')
$journalctl -u docker
Please note the more complex pattern to retrieve the mesos-id compared to the earlier example. This pattern lists already failed tasks and running tasks, while the earlier pattern only lists running tasks.
Cleanup
dcos marathon app remove docker-image
Ready, Set, Debug!
There are more hands-on exercises in the dcos-debugging github repository, so dive in, challenge yourself, and master the art of debugging DC/OS. Also feel free to contribute your own debugging scenarios to this repository!
We hope you got an idea of how to debug application failures on DC/OS from this introductory blog post. There are many more troubleshooting topics that we'll cover in upcoming posts. Keep coming back for more in-depth tutorials, and, in the meantime, happy debugging!