Aug 31, 2017
Joerg Schad
D2iQ

Most modern enterprise apps require extremely fast data processing, and event stream processing with Apache Flink is a popular way to reduce latency for time-sensitive computations, like processing credit card transactions. In this blog post we describe how to run Flink on Apache Mesos and DC/OS by looking at a demo detecting money laundering in a large stream of transaction data.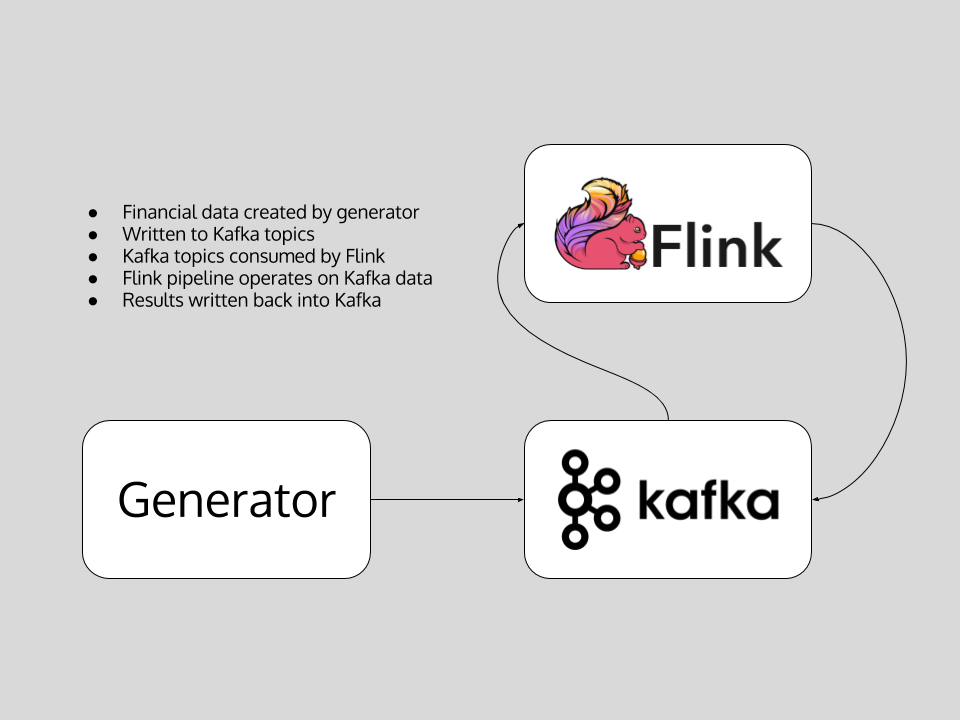
There are many stream processing frameworks to choose from, including Apache Spark (Streaming), Apache Storm, Apache Kafka Streams, or Apache Samza, but we will leave the comparison of all these stream processing tools for a another blog post.
Apache Flink
At its core Apache Flink is a distributed low-latency streaming engine designed to process long running streaming jobs. It also supports batch processing and event-driven applications. Flink provides the notion of event-time processing and state management, and it integrates well with other open source projects including Apache Kafka or Apache Cassandra.
Flink's integration with Apache Mesos and DC/OS
While Flink provides great support for stream processing, Mesos offers an elastic and fault tolerant way to run applications on a shared cluster. Even before Flink officially supported Mesos as a scheduler, 30 percent of Flink users surveyed in September 2016 said they were running on Mesos. So since the 1.2 release of Flink, Mesos and DC/OS are first-class citizens in Flink's deployment model.
Mesos Integration
To run on Mesos, Flink registers as a Mesos framework and its Application Master–which includes both Flink's ResourceManager and JobManager–runs on a Mesos agent. Flink's ResourceManager hosts the Mesos scheduler, which communicates with the Mesos cluster and allocates resources for the Mesos tasks, which in turn run Flink's TaskManagers.
DC/OS Integration
When using DC/OS, deploying Flink is simple; search for "Flink" in Universe, install the package with a couple of clicks, and you're ready to get started. During the installation, you can optionally configure advanced features such as checkpoints for fault tolerance (which is recommended for most production deployments, but also requires installing HDFS). Have a look at this example for more details.
Thanks to one of Mesosphere's summer interns, Robin Oh, you can now use the DC/OS CLI to control your Flink jobs. A simple
dcos flink upload <job-jar-file> followed by dcos flink run <jar> let's you run your first flink job. Check the cli section in the example for more details on the CLI usage.
Demo Hopefully, by now you're are excited to use Flink on DC/OS! The next step is to run a concrete demo, where we show you how to
use Flink and Kafka to analyze streams of financial transactions to detect money laundering.
Demo data flow
The demo structure is simple: we use a data-generator that generates transfers between two bank accounts, which are then written into a Kafka topic. This Flink job is then used to aggregate the individual transactions and detect transfers between two accounts that sum to more than $10.000 over a given timeframe.
We've recorded a video of the demo to show how easy will be to run it on your own.
https://www.youtube.com/watch?v=bwPXNlVHTeI
The Future
There are a number of improvements coming soon which will make the Flink and Mesos integration even more powerful. One highlight is dynamic resource allocation, which will enable Flink to adjust the number of Mesos tasks up or down depending on how much it needs to process. FLIP-6 will address this issue by allowing Flinks deployment components to scale independently of each other. A dispatcher component will receive jobs and spawn Flink clusters, and the new ResourceManager will dynamically allocate new tasks if more resources are needed.
Flink, Mesos, and DC/OS are all Open Source projects and you are invited to contribute! Checkout the Mesos component or join the DC/OS community #flink slack channel to get started!