






May 09, 2017
Fernando Sanchez
D2iQ

6 min read
D2iQ has chosen to sunset DC/OS, with an end-of-life date of October 31, 2021. With D2iQ Kubernetes Platform (DKP), our customers get the same benefits provided by DC/OS and more, as well as access to the most impressive pace of innovation the technology world has ever seen.
Learn more about D2iQ Kubernetes Platform here.
This is the third part of a blog series on Networking for Docker containers. The first part of this series introduces the fundamentals of container networking. The second part covers the basics of Service Discovery, how it has evolved over time, along with the evolution in computing and virtualization. This article lays out the various architectural patterns you could use for Service Discovery, Registration, and Load Balancing.
Adopting containers for delivering your microservices applications provides many advantages, but it also requires a solid architecture for service discovery, service registration, and load balancing.
For service registration, manually registering each individual container every time it comes up (and then having to de-register it once it's destroyed) is not practical, and may not even be feasible at scale. Many containerized workloads have a short lifespan. This creates the need for an automated service registration strategy that the application or infrastructure operator does not have to be involved in.
For service discovery, this also makes the Load Balancer (or equivalent system routing the client's traffic to the service endpoints) a key piece in the architecture, as it will be responsible for the "Application/Service Delivery": every application or service is only as usable, performant, or available as the Virtual IP or endpoint provided for it via the Load Balancer. This forces the Load Balancer to be treated as a critical piece of the system, and imposes a need for resiliency and high availability, as it is the entry point to the application.
In a system where backends may be created and destroyed quickly, the Load Balancer has the task of making sure all of the service instances are available and healthy (or else remove them from the list and force a reboot, destroy/reboot, or relocation). This imposes the need for a stringent control over the lifespan of the workflows via healthchecks, and a perfect synchronization between the Load Balancer and the Service Registration mechanism.
As outlined previously, this issue can be tackled in many ways, and each method has its advantages and drawbacks. Depending on how your application is designed, the skills of your team, or the tools at hand to solve the challenge, you may find one method (or a combination of them) more suitable than others. Here are some of the main strategies:
Architectural Patterns for Service Discovery
Service Discovery strategies determine how clients find the location of a service instance, knowing the service's name.
Client-Side Discovery
With client-side discovery, the application's clients talk to a service registry where all your application's endpoints and backends are stored and kept up to date. Clients talk to the registry directly (they are "registry-aware") and usually perform the load balancing logic between the list of backends.
This pattern usually comes coupled with some popular development frameworks (or Microservices "chassis" frameworks) that simplify the creation and management of the client side of the discovery with some sort of "prototype" or inheritable client, making it easier for developers to include it in their applications.
(Image source: NGINX's Service Discovery in a Microservices Architecture)
An example of this would be Netflix's Eureka service registry coupled with their Ribbon SD client.
Client-side discovery generally simplifies the service architecture, reducing the number of elements involved to just the client and the registry. On the downside, this forces you to have client-side logic for all the programming languages or frameworks you may want to use, which may make development of new services slower or more difficult.
Server-Side Discovery
In server-side discovery, clients talk to the load Balancer, and the load balancer talks to the service registry. This removes the need for the clients to be registry-aware, and also makes the load balancer a demarcation point where several operations related to security, monitoring, and service delivery can be centralized.
(image source: NGINX's Service Discovery in a Microservices Architecture)
Server-Side Discovery with DNS
The simplest way to enable server-side service discovery is via the venerable Domain Name Service (DNS) that fuels the internet. DNS clients are embedded in all operating systems, so that you (or your program) just need to remember "which service" you want to access (like www.mesosphere.com "externally", or possibly "server04.databaselayer.mycompany.net" internally), and your DNS server will provide you with an address for it.
You could consider using this for accessing your microservices as it greatly simplifies your approach to the problem. It does, however, come with a number of relevant drawbacks:
- DNS is very slow adapting to changes. Microservices and containers are by nature very dynamic and their locations change often and quickly. So if your microservice backend list changes quickly, these changes wouldn't be reflected in DNS fast enough for your clients to correctly access them, producing connectivity problems.
- A DNS based solution will very likely support only a round-robin load balancing logic (the DNS will return the entries it has for a name in a round robin fashion, and in this pattern there's no load balancer involved), whereas for a modern microservices implementation you typically want granular load balancing policies that consider latency, load, number of connections, or other parameters.
These drawbacks come from the fact that DNS was designed many years ago, when services didn't change that often. Also, it was designed for internet-grade scalability and with different goals in mind than today's microservices require.
Still, DNS is a standard that needs to be available in any platform, and most platforms used today to provide microservices offer a DNS-based solution. Kubernetes uses kube-dns, Consul provides DNS functionality, and Mesosphere DC/OS ships with Mesos-DNS and a Distributed DNS proxy (a.k.a. Spartan).
Most of these implementations provide improvements and fixes targeted to alleviate the standard inherent flaws with DNS for use with containers and microservices, such as keeping DNS in sync with a dynamic registry for services or providing distributed DNS proxies across the cluster to reduce latency. Still, these flaws make DNS suboptimal for a microservices architecture.
Server-Side Discovery with a Load Balancer
Another simple example of server-side discovery is a classic load balancer based architecture, even those from years ago where the "service registry" was an excel sheet that some network operator would keep up to date with the list of physical servers running an application (as discussed in part II of this blog series). More recently, and in a microservices context where registration needs to be automated, the load balancer needs to be synchronized with a service registry of some sort. Other architectures based, for example, on a combination of HAproxy or NGINX as load balancers being synchronized to a service registry such as Consul, Etcd, or Zookeeper would also apply here.
In general, using a feature-rich Layer-7 load balancer (i.e., a load balancer that de encapsulates the incoming TCP connections and looks into the HTTP and even the content inside) provides control and versatility over advanced features at the application level. These are usually considered useful for "external facing" load balancing, like SSL/TLS processing, cookie or content-based processing, URL rewrites and other content-specific features. Usually these fields are processed in "north-south" connections (i.e. connections "into" and "out of" the cluster where the application is running) -- as opposed to "east-west" connections (i.e. connections "internal to the cluster" between services running in it). Processing the traffic at layer-7 also adds CPU overhead and potentially latency, so while the need for all these features is evident in north-south connections from "the internet", for east-west load balancing internal to an application these needs can be questioned (provided that traffic inside an application is normally already protected by perimetral security, and we can "trust" our own services more than traffic from the outside), and maybe an approach with a layer-4 load balancer can be considered more optimal for performance and latency.
Additionally, north-south traffic typically needs to be routed through a specific physical location, like your connection to the internet or the WAN, a firewall, or a core router. This means that using a load balancer that isn't fully distributed may not be of relevance, given that traffic is already "centralized" in nature as it goes "in and out" of the cluster. We'll see the difference with east-west traffic below.
In DC/OS, north-south traffic is handled like this, as we will see in the section "Simplifying Service Registration, Discovery, and Load Balancing for Microservices with Mesosphere DC/OS" below.
Server-Side Discovery with a Load-Balancing Proxy
A twist and optimization on the previous approach is to co-locate a proxy or load balancer in each of the servers of the cluster where the services are being launched. AirBNB's Smartstack is an early example of this, and the Kubernetes "kube-proxy" is a more recent one. This allows to do "server-side" load balancing. Each service is assigned a port across the system. In order to make a request to a service, a client routes the request via the proxy using the host's IP address and the service's assigned port. The proxy then transparently forwards the request to an available service instance running somewhere in the cluster, either locally on that same host or in a different one if required. The configuration of the proxy on each host to make sure is up to date is typically performed by the framework's internal components (Synapse in the case of Smartstack, or through the kube-apiserver in the case of Kubernetes).
Server-side discovery simplifies the clients as they don't have to care about the discovery and simply hit a well-known endpoint.
Mesosphere DC/OS also uses server-side discovery with a load-balancing proxy (along with additional improvements) for east-west traffic, as we will describe in the final section of this post, "Simplifying Service Registration, Discovery, and Load Balancing for Microservices with Mesosphere DC/OS".
Server-side discovery with an API Gateway
An API gateway mediates between the clients and the (micro)services behind it, proxying requests to them and possibly providing a tailored API depending on the client type or the service version. In a microservices architecture, where your backend services may be subject to change and be decomposed in smaller services, or where your versions may change quickly, an API gateway could allow you to maintain homogeneity in the interface offered to clients, while still being able to make changes in your backend implementation.
(image source: NGINX's Building Microservices Using an API Gateway)
Whereas most API gateways form part of larger "API management" solutions, we focus here exclusively on the "mediation" work that the gateway does between clients and services. API gateways work both in the service discovery aspect (offering convenient API endpoints to clients to access services), and in the service registration aspect (by keeping an up-to-date list of microservices and backends they connect to). These API endpoints are likely tailored for each client type, and possibly tailored/modified/simplified from their original shape in a "transformation" function that many API gateways can provide. Other functions such as API lifecycle management including versioning, updates, registration and more are usual components of an API gateway solution.
API gateways can work as "proxies" with server-side discovery, being in the middle of the requests between clients and services, in which case they act as a sort of "load balancer" and assume the responsibility of routing traffic to the service backends. They can also be in "client" mode (or client-side discovery), providing a plugin that integrates with your server, in which case they wouldn't be in the traffic path like in proxy mode. Also, some solutions work in "hybrid mode" providing both an agent and a proxy.
Examples of open source API gateway/management solutions include Kong, Tyk, or WSO2. There's also a plethora of commercial solutions available from vendors such as Apigee, CA, IBM, Mashape or Oracle. Also, many cloud providers provide a sort of "API management" service.
Architectural Patterns for Service Registration
Service registration determines how instances of a service are onboarded into the service's "backend list" with their location, so that traffic can be routed to them from the load balancer, the API gateway, or whatever "routing facility" is used in the architecture.
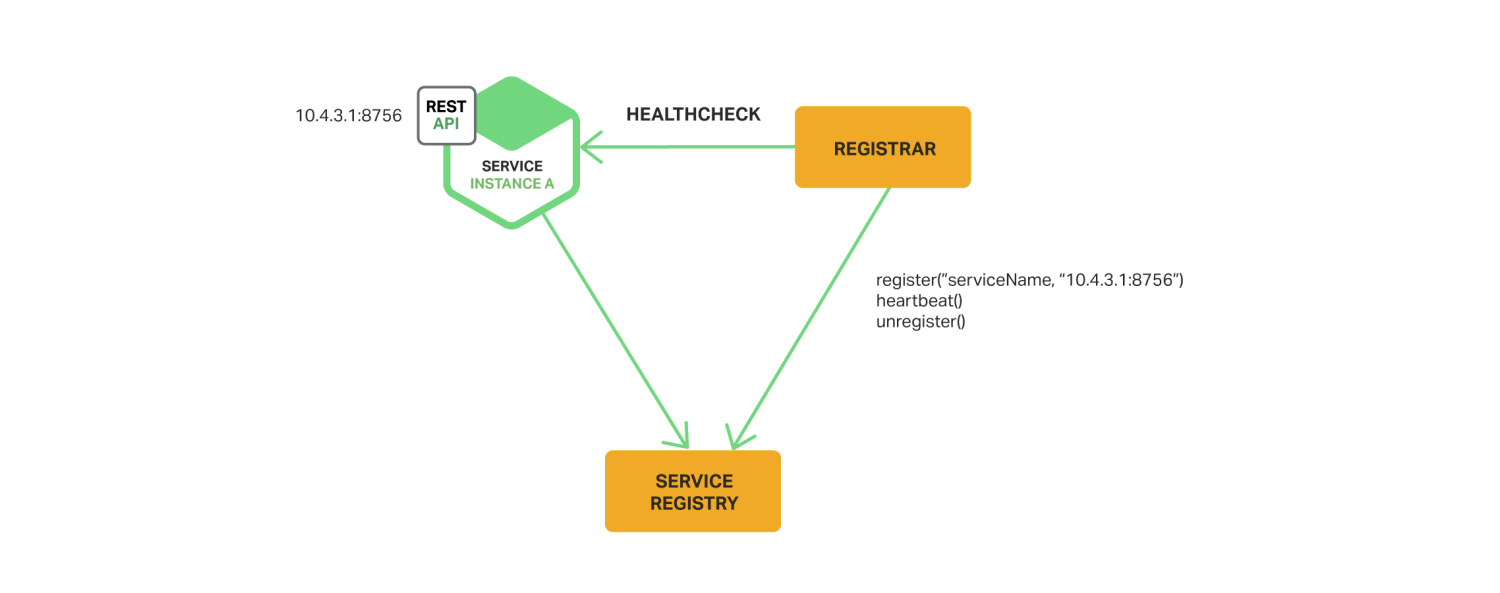
Self-Registration / Sidecar Process
The application itself (or the microservices forming the different pieces of it), would have an internal piece or process designed to automatically detect the IP address and port in which the application is running, and add it to a centralized database (or service registry). Consumers of this service (either users or other services that need to use it) can get an updated view at any time. This service registry could be a simple database implemented with any key-value data store.
(image source: NGINX's Service Discovery in a Microservices Architecture)
Clients of the service would be capable of querying the service registry using the service name to discover which specific endpoint to send each individual request to.
A good example of a self-registration method is Netflix's Eureka. Examples of service registries that can be used to implement this pattern include Zookeeper, Consul, or Etcd. Most of these key-value stores are able to provide "watches" so that clients can get automatically notified of changes in the backend list.
Usually, the advantage of self-registration is that it tends to simplify the architecture. On the other hand, it requires all services to include the registration logic. This means that if you're developing services in different languages or frameworks, you should have this registration logic implemented for all of them. Additionally, typically the service instances themselves are responsible for de-registering, which means that in case of a crash there should be a timeout for the registry to "unregister" lost backends.
External Orchestrator / Service Manager
In cases where endpoints are created by an external orchestrator (such as a container orchestrator like Marathon) and that orchestrator is aware of the addresses assigned to endpoints (for example, if it includes or has visibility on a DHCP server that assigns addresses to workloads running in containers), it is feasible to have the orchestrator make this information available to a load balancer.
(image source: NGINX's Service Discovery in a Microservices Architecture)
The Orchestrator or service manager can maintain a service registry with the updated backend list (again, typically implemented with a key-value store), and/or provide that information through some sort of event bus for consumers like a load balancer to maintain an external registry themselves. The load balancer (or the service consumers themselves) can then check the service registry to get an updated view of the endpoints.
Clients of the service would then access the service through an endpoint in the load balancer, which would stay up to date by keeping in sync with the service registry or through the event bus.
Mesosphere DC/OS is able to automatically handle the registration for all services running on it, as we will see in the next section.
Simplifying Service Registration, Discovery, and Load Balancing for Microservices with Mesosphere DC/OS
Mesosphere DC/OS is the platform of choice for containers and microservices, running more containers in production today than any other commercial software vendor. Based on the Mesos distributed systems kernel, Mesosphere DC/OS fuels applications across industry verticals including Finance, Telco, Consumer Goods, Automotive, or Pharmaceuticals. Some of the world's most demanding web scale applications run on Mesos, and our team has been pioneering the development and operations of some of the internet's best known web-scale services.
Enterprise DC/OS ships with a tightly integrated set of service discovery, service registration, and load balancing mechanisms in order to make it easy for developers and operators to connect and scale their microservices and applications.
For Service Discovery, Mesosphere DC/OS provides native and off-the-shelf DNS, load balancer and load balancing-proxy solutions that serve different needs:
- Mesos-DNS automatically provides name-based resolution to any workload living on DC/OS. From containers to big data workloads, from machine learning to distributed storage, everything that runs on DC/OS can be easily reached through a DNS name, independently of where it runs on an arbitrarily large cluster. This is convenient for long-running internal services (the internal components of DC/OS can use it for communication) and also for locating some of the workloads that are not subject to frequent modification (like the schedulers or internal components of Mesos frameworks).
- Marathon and Marathon-LB are examples of load balancer based server-side discovery, where Marathon-LB acts as an external-facing (north-south) Load Balancer and Marathon keeps a registry of the state for all services. In DC/OS, Marathon-LB runs on the public nodes that offer connectivity to the outside of the cluster, providing advanced L7 load balancing services. Marathon-LB stays in sync with the Marathon container orchestrator by listening into the Marathon event bus to access the contents of the internal service registry, and adapts immediately to changes happening in the cluster. Based on the well-known open source project HAproxy, Marathon-LB enables seamless discovery of applications and provides advanced and battle-proven L7 load balancing features. Marathon-LB acts as the point of delivery for applications running on DC/OS towards external users, providing features such as SSL/TLS, cookie parsing, virtual hosts and many others. It is tightly integrated with Marathon, our container orchestrator of reference within Mesosphere DC/OS. If you'd like to get further detail on how Marathon-LB works, please read this tutorial.
- For east-west traffic and communication between microservices, Mesosphere DC/OS ships with our distributed load balancer (a.k.a. Minuteman) and our distributed DNS proxy (a.k.a. Spartan) that provide Virtual IPs for east-west traffic, enabling service discovery for workloads running internally on DC/OS. Local instances of the distributed load balancer and distributed DNS proxy run on each agent of a DC/OS cluster, in a design that follows the "load balancing proxy-based discovery" approach mentioned earlier in this article. This enables the solution to scale linearly for any arbitrarily large cluster size while minimizing latency and maximizing throughput. Whether you're running 5 or 50,000 nodes in your DC/OS cluster, your east-west service discovery will connect your microservices with ease and performance. Given that microservices can be anywhere in the cluster, it is key that east-west traffic is handled in a fully distributed fashion.
For service registration, Mesos-DNS and Marathon provide automated registration of all containerized workloads, name-based microservice endpoints, and distributed Mesos frameworks that run in the cluster, acting in a way described above as the "External Orchestrator / Service Manager" service registration pattern.
Finally, and in line with our philosophy of openness and freedom of choice for our users and customers, we are also proud to provide and support an application ecosystem comprised of more than 100 partners and open source projects. These include some of the most popular solutions for service discovery, service registration and load balancing, including Kong, AVI Networks, Etcd, Linkerd, Vamp, and NGINX (just to name a few). Each offers unique features and advantages that enable you to apply the different patterns we discussed in this article.
At Mesosphere, we ensure these partner services are tightly integrated with the rest of DC/OS to guarantee a smooth experience for developers and administrators. Mesosphere DC/OS provides an open and public API for developers and vendors to easily make their products available to DC/OS users. This fuels a rapidly growing service catalogue that currently has over 100 packages available for easy installation. We expect this explosive growth to continue over the next months and years, thus making DC/OS an evergreen platform for any application you choose to develop and deploy.
Contact us if you'd like to learn more.


