






Mar 15, 2018
Chris Gutierrez
D2iQ

13 min read
Fraud detection and risk analysis initiatives are a high priority for many companies conducting business online. This tasks data science teams with building and maintaining platforms capable of performing complex processing, modeling, and analysis of fast data and big data in real time. Such a platform (and all of its associated components) can be difficult and time consuming to build and maintain manually.
Fortunately, there is a better way: Mesosphere DC/OS streamlines the building of data processing and modeling pipelines so data science teams can be more productive. And fortunately for you, you don't have to experience the pain I did when I helped build fraud detection and risk analysis platforms at past companies.
Let's take a look at the pain points that I encountered in the past when building fraud detection and risk analysis platforms and how DC/OS would have made the process far easier and faster. Although much of this post describes situations that predate DC/OS, the core problems are the same today. As such, this is a good demonstration of how DC/OS helps data science teams build and maintain a modeling infrastructure now and in the future.
Background
Most data science teams that I've managed focused on the product and how customers used it. There were many disparate data science platforms along the way, and much of our work revolved around reporting and A/B testing. I've worked with teams responsible for things like measuring the impact of changes to site flow, search rankings, and many other product adjustments. Most of the work was performed in batch jobs, which meant that adding new products, features, and pipelines often did not require many infrastructure changes. However, as stream processing has become more prevalent, the infrastructure required to support data science has grown more complex.
At one point I was tasked with taking over a fraud/risk platform from engineering. The fraud platform was very different from anything that the data science team had previously owned. The near real-time aspect was the reason it had been owned by engineering. At that time the data science team owned nothing that operated in real time. The closest system we had was comprised of batch jobs that ran every 15 minutes. There were analytics systems that ran in near real time, but they were not owned and maintained by the data science team. They were also custom to their task. Based on the nature of the data and how the data was accessed and processed it was not an option to simply run a new batch process with smaller batch intervals. The data science team needed a new system to return model results in near real time.
Building a Fraud Detection Platform Manually
When I started work on the fraud platform, it was a Java and Weka solution. It worked but wasn't trivial for a non-Java programmer to take over. It didn't read from all the data sources that were being continuously added to the infrastructure.
There were a couple of data sources. Ruby on Rails would write csv files. Queries were also written against a MySQL database. At the start that was sufficient. Over time, however, third party data and data from HDFS became available, yet the existing system would require significant work to add these new data sources.
After the data was pulled Weka was used to create and tune a model. When satisfied with the results the modeler could save the Weka code where it was available to a restful API written in Java.
However, the difficulty in adding new data sources wasn't the main problem. There wasn't a way to run multiple models at one time, and we had no version control over our models. Even this was all fixable, but not if the data science team was going to take over ownership because there were no programmers on the data science team to maintain the Java and Weka code we were using. The primary languages of the team members were R and Python. There were a few Stata programmers, but they were all economists (who wants economists working on risk?).
I started looking for an oxymoron: a scalable system that worked with R. If engineering was going to hand this off to the existing data science team the system needed a different design.
Fraud Detection Platform Requirements
Fraud detection and risk analysis initiatives can only be successful if they impact the business as a whole. For this reason, it was important for us to gather business and technical requirements prior to developing and deploying the platform.
There were many more requirements than the ones listed below, but the following were the most important high-level requirements.
Business Requirements
- Reduce Fraud/Risk on our transactional platform to ensure a safe environment for our users and increase adoption.
- Ability to develop and test new models quickly and consistently to constantly improve models and react to rapidly changing conditions.
- Migrate from batch only to batch and real-time architecture to improve the timeliness of analyses and prevent fraud as it happened.
- Transfer ownership of fraud/risk platform from engineering to the data science team to improve developer agility.
The last requirement revolved around a non-engineering team taking the platform over. Without hiring data scientists with strong engineering backgrounds (later that was done), we needed a solution built on SQL, R or Python. This business requirement was the largest driver for the technical requirements.
Technical Requirements
- R support. As stated earlier, with few exceptions everyone on the data science team knew R well. Thankfully, fraud is rare, so working with fraud data allows for large undersampling of negative cases. Modeling on modest hardware with R was, therefore, possible. This also allowed model training to be divorced from production processing.
- RESTful API. The main new feature required was quickly returning model results from API calls. The API call volume was high and responses needed to be returned in under a few dozen milliseconds. Failover and redundancy also needed to be included. The calls and results needed to be logged for future analysis and reporting.
- Batch processing. Although the API was the key component, batch processing of the model results was still required for "what-if" scenarios such as "What if the model we just created had been running in the past? What would the results have been?" It wouldn't work to make 10's of millions of calls to an API for every query used to evaluate a model. The model would need to be compilable and transportable.
- A/B Testing. Running models and what-if scenarios was not enough. We also needed to run A/B tests of various models. That meant that a model, selected randomly from the set of appropriate models, needed to be returned with a call. The model name and version needed to be included and logged for future evaluation.
- GIT support. There needed to be version control on the models. Any data scientist added to the project would want to know what had already been tried and correlate the model with the results.
Fraud Detection Platform Architecture (Without DC/OS)
Finding a solution that met all requirements was more difficult at the time I was building this fraud detection platform than it would be today. I looked through many potential solutions at various stages of maturity. The one that we eventually went with was Openscoring.
- R support. R could export Predictive Model Markup Language (PMML). This allowed models created in R to be consumable by anything that was PMML compatible. Openscoring consumed PMML, so it could meet our other needs. At that time Openscoring was a young project missing some features we needed. It also had a few known bugs that we needed addressed. It was very close to what we needed and the quality of the code base looked very good.
- RESTful API. This was the main draw to Openscoring. The RESTful API worked well, and it's improved a lot since then.
- Batch processing. Openscoring could convert the PMML to compilable Java. The model could then be used as a UDF in Hive. Now it would be even easier with jpmml/jpmml-hive.
- A/B Testing. Openscoring logged calls with all the model details. This made A/B testing trivial.
- GIT Support. PMML is just text. Models were easily versioned and stored in GIT. There were workarounds for a few very large random forests, but generally, this wasn't a problem.
Building a Better Fraud Detection Platform with DC/OS
Even with a clear path the project took months and required a lot of engineering help. The project was a big success, but had DC/OS existed it could have been completed in weeks and been easier to maintain. Here I'll run down how we implemented Openscoring and how DC/OS could have made it a lot easier. Keep in mind that this was several years ago, and while some of the decisions may seem a little crazy today, they were good options at the time.
Provisioning
At the start, I needed a machine to test and train models and this required the operations team to provision a node on AWS. They often wanted to take the node down in the evening and especially over the weekend since it would be idle. A laptop was sometimes used, but that was less than ideal. Matching a laptop environment to an AWS node while continuing to do other things on the laptop created unneeded problems.
With DC/OS, I wouldn't need anything provisioned by the operations team. On a DC/OS cluster, any Docker image can easily be provisioned from the GUI. If the container doesn't consume a lot of resources while idle, it can be left running on the cluster. The container takes up resources, but it becomes possible to take fractional resources. That is, rather than requiring an entire node, my container may only require a fraction of an already running node. In many cases, there is no incremental cost.
It's true that you could do this with only Docker on a laptop. While that is nice, it is not as good as running on DC/OS. If something works on a local docker container, it doesn't guarantee it will work on a cluster with different networking and routes to machines. If the container is already reading and writing to and from the cluster, while in the cluster, then making the process a production process is made easier.
DC/OS clusters can be installed locally, or on AWS, Azure, or Google Compute Engine. Installation does not require strong operations expertise. Anyone with a basic understanding of networking can bring up a cluster by just following the directions.
Installing
After the node was provisioned on AWS, Openscoring needed to be installed, not a trivial task at the time. For a data scientist that is not an engineer, it was even more of a challenge. I mercilessly solicited assistance from engineers outside the data science team.
If we had DC/OS I could have done the work with minimal, if any, help. Engineers would have gotten a lot more sleep and spent far less time hiding from me. Openscoring has a container on Docker Hub. Anyone on the data science team could have entered the container information and resource requirements into the DC/OS management GUI. Two clicks later and it would be running on the cluster. There's no need to fuss about versions, paths, missing libraries, etc. It would have just worked.
As an example, this 13 minute video shows how to easily install Tensorflow and Jupyter on DC/OS using Docker images. The example shows both GPU and non-GPU versions and compares performance. Another 9 minute video has the same example using only Docker. Together they illustrate how to seamlessly go from a local test environment to a cluster running DC/OS.
Adding Features and Debugging
Fortunately, not only did I have great internal engineering support, but we also contracted out the originator of Openscoring, Villu Ruusmann. Some complications, however, were introduced because he was not an employee and therefore didn't have access to our cluster. It was sometimes difficult for him to reproduce our errors. Villu would add features that worked when he tested them in his environment, but sometimes would not work in ours.
With DC/OS, he could have worked specifically on a Docker image. If needed, it could be a private Docker repository owned by the company. Since passwords are stored securely in a secrets store on the cluster, code can be written independently of password and username. Even better, we could have set up a dummy cluster outside our network. The dummy cluster would have the same networking without any real data. A contractor could develop and debug on something very close to the environment the application would eventually run on, with DC/OS managing details like versions, paths, libraries, and more.
Integration
Even with everything running, integration with all the other systems was difficult at best and painful at worst. Data came from several systems across the company. Some data came in at near real-time (e.g. IP address of site users and 3rd party partners). Other data was compiled from user history, host history, and batch-processed data. Some processes were dependant on other process completing. The data pipeline required for each request was extensive.
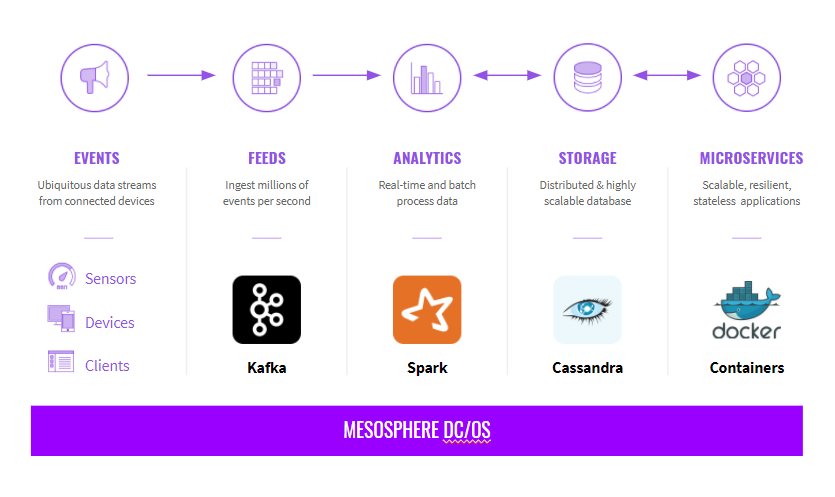
With DC/OS, connecting applications is often easy. The built-in networking makes it easy to discover and connect clients to data services via a hostname. The DC/OS job scheduling capabilities can be used to reliably orchestrate ETL pipelines with complex dependencies.. This still requires the hard work of writing the logic to process and compile data, but the connectivity is easier to see, understand, and debug. It's possible to deploy a data pipeline in under 10 minutes with DC/OS.
Maintenance
Chef was required to ensure that operations could bring up an Openscoring node if it died in the middle of the night. That meant I had to setup the Chef recipe. While not incredibly difficult, it's not an enjoyable task.
With DC/OS, if the node with Openscoring goes down it will automatically be restarted on another one. If the container itself were to crash for some reason, another container will automatically be spawned. In either case, it will come up and be correctly configured in the network. The DC/OS network takes care of routing so all other apps will seamlessly continue to reach Openscoring. No Chef recipes are needed.
It is also worth noting that, by design, any application that is set up with attached volumes will be stateful. That is, when a new application is spawned from an application that died, it will know where it left off.
DC/OS Increases Data Science Productivity
DC/OS makes data science initiatives easier to create, shortens the amount of time required to bring them to market, and simplifies the deployment and management of open source frameworks and in-house developed models.
Openscoring, or any other containerized application can form the basis of a data science platform. Any application with a Docker image can be deployed as part of the solution. Moreover, there are dozens of applications already in the DC/OS Service Catalog to choose from, including Apache Kafka, Apache Spark, BeakerX (Jupyter with extensions), Apache Zeppelin, and more that can be installed and configured as easily as an iPhone app.
Getting individual applications working on DC/OS is easy, even for a non-engineer. Connecting several applications together as a comprehensive and powerful solution is also within reach of non-engineers. Data scientists can snap together a pipeline of application like legos. Creating solutions that are assembled on the cluster from the beginning shortens the time to production and improves the quality of the solution. With DC/OS, data science teams are more proactive in architecting solutions, relieving pressure from infrastructure teams and freeing data science teams to focus on data and data-centric solutions.


