





Part I: Why Machine Learning's Dogged by Failure and Delays | D2iQ

Feb 19, 2021
Ian Hellström
D2iQ

10 min read
AI is everywhere.
Except in many enterprises.
Going from a prototype to production is perilous when it comes to machine learning: most initiatives fail, and for the few models that are ever deployed, it takes many months to do so. While AI has the potential to transform and boost businesses, the reality for many companies is that machine learning only ever drips red ink on the balance sheet.
There is a lot more to machine learning in the enterprise than just the model, which is what many people think of when they hear artificial intelligence. As little as 5% of the code of production machine learning systems is the model itself.
Adapted from Sculley et al. (2015): Hidden Technical Debt in Machine Learning Systems. The model itself (purple) accounts for as little as 5% of the code of a machine learning system. Components that are unique to data engineering and machine learning (red) surround the model, with more common elements (gray) in support of the entire infrastructure on the periphery.
Before you can build a model, you need to ingest and verify data, after which you can extract features that power the model. The model itself requires debugging, and you have to evaluate and analyse it for bias and fairness. But once it’s ready to be served, it requires infrastructure of its own with monitoring of course.
The overall process needs to be managed, the data and model need to be tracked, and there are of course generic components, such as resource management, configuration management, and automation.
These tasks are usually split over a data engineer, a data scientist, and a machine learning engineer.
The data engineer’s main focus is on ETL: extracting, transforming, and loading data.
This means integrating with lots of data sources and writing custom transformations to shape the data in the format required for each use case.
Machine learning engineers are typically responsible for ML models in production environments, dealing with web services, latency, scalability, and handling most of the automation around ML. While there is a large infrastructure component that can often be handled by DevOps or platform engineers, the challenges unique to machine learning mean in practice that they need to have a solid background in modelling too. We’ll come back to some of these challenges later.
Data scientists sit in the middle of this, and they are the experts on the data sets and their value to the business. A core task is the identification of business problems that can be solved by data science and in a lot of cases: machine learning.
In quite a few organizations, data scientists can be heard complaining about data engineers being too slow in providing high-quality data sets. They, in their defence, often counter that it takes time to access the correct data, build pipelines that are well tested, parameterized, and automated to run on a schedule with clear SLAs, and monitoring and alerting in place. The same is true for the handover of models towards machine learning engineers, who often have to rewrite the data ingestion and model code, which can add or even uncover mistakes that cause models to be delayed or fail.
While there is definitely some overlap with data and machine learning engineers, the tools data scientists use are quite different too. While both groups of engineers are comfortable with IDEs, CI/CD, containers, and the like, data scientists, due to the nature of their work, often rely on notebooks for exploratory work with little to no automated testing or containerization.
The division in tasks and technologies is not merely an artifact of the separation of responsibilities and expertise, but also a consequence of Conway’s law due to
cultural differences, in which there is a clear split between research (science) and engineering; it resembles the pre-DevOps situation, in which code transfers were not unlike uncomfortable hand-me-downs rather than professional hand-overs—or better still: collaborative efforts.
The Road to End-to-End ML Platforms
While 85% of initiatives are still expected to fail over the next two years, it’s perhaps sensible to take a step back and look at how the industry arrived at today’s technologies and troubles. We shall see that end-to-end machine learning platforms for the big data era have only emerged over the last five years at various tech companies such as Facebook, Twitter, Google, Uber, and Netflix.
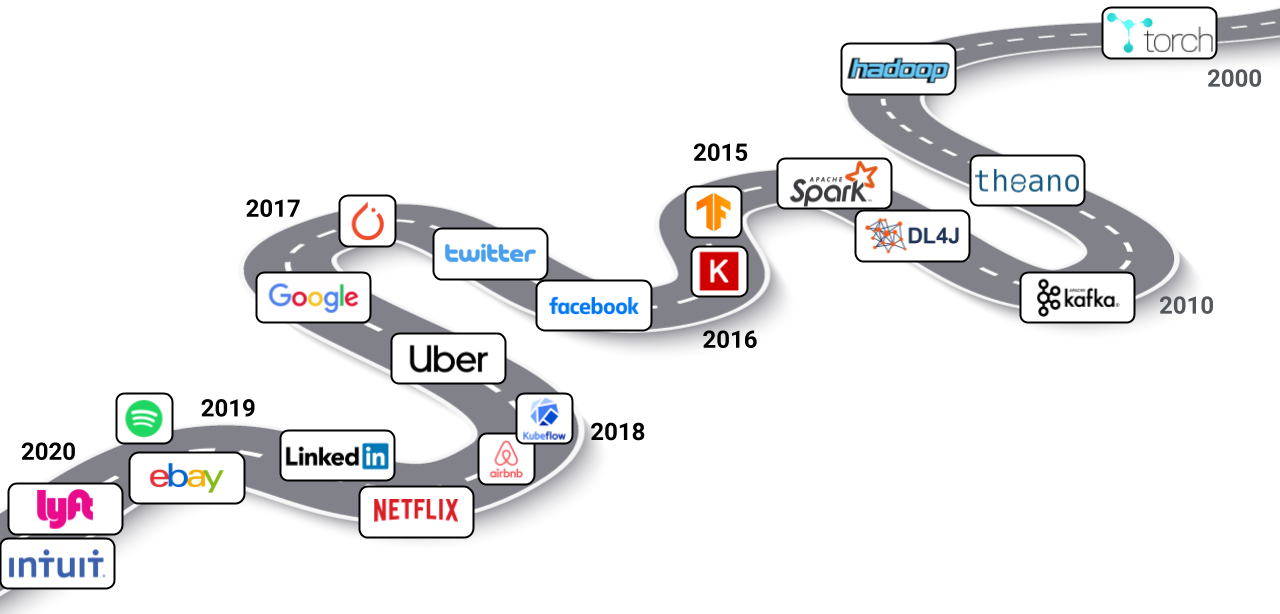
The road to end-to-end machine learning platforms. A more complete timeline is available on Databaseline.
The open-source data era kicked off with Hadoop and MapReduce in the early noughties, soon followed by Kafka and Spark. Around the same time the first frameworks for deep learning were developed: Torch, Theano and DeepLearning4j. Keras and TensorFlow emerged in 2015. Back then, TensorFlow was very low level, even though nowadays it includes the Keras API. PyTorch was released a year later. It relied on Torch’s core but replaced Lua with Python, which is the de facto language for data science.
In 2016, Facebook was the first tech company to publicly announce details of their ML platform, FBLearner Flow. Twitter followed suit in the same year. Another year had passed when Google announced the details of TFX, which has since become the backbone of TensorFlow deployments in many production environments. In 2018, Google open-sourced another of their machine learning projects: Kubeflow, the machine learning toolkit for Kubernetes.
Uber’s Michelangelo was announced in late 2017, which gained a lot of attention at the time as it inspired many others to imitate or reveal the details of their own platforms. After that, Airbnb’s published details of Bighead, and then Netflix with their notebook-based Metaflow platform that has since been open sourced but is still intimately tied to AWS. LinkedIn also shared specifics of their platform, as did eBay, and Spotify who mostly run Kubeflow Pipelines on GCP with their own Luigi for dependency management. Lyft open-sourced their Kubernetes-based platform called Flyte earlier this year.
Case study: K9s
We have claimed that machine learning in the enterprise is much more than just the model. To demonstrate that, we shall look at a fictitious company called K9s, an online shop for dogs, run by dogs. By reasoning backwards from a high-level business objective, the team at K9s is able to translate their needs into requirements for machine learning technologies. As we shall see along the way, these requirements are often unique to machine learning.
The K9s CEO states to the executive team that she wants to increase online sales by a 10% without changing marketing strategy or budget. Discussions with the CMO revealed that K9s already leave their mark everywhere in town, so it does not make sense to adjust their strategy or expand their reach.
Immediately the CTO jumps in and says they could build a recommendation engine to suggest items customers may be interested in; a 10% increase in sales thanks to product recommendations is definitely achievable. The CEO loves the idea and wants the CTO to work out the details with the team to figure out what they need to make it happen.
CTO:
With 100,000 products in our catalogue and many of them seasonal, we cannot rely on manual curation. We therefore have to look at automation and ideally leverage our customer data.
Data scientist:
I propose a collaborative filtering recommender. It is a decent baseline that does not require special product knowledge, so there is no need for extensive feature engineering. We can use the existing data of our users’ behaviour, such as clicks, page views, and purchases. For the seasonal products, we may need to look at a hybrid approach that combines it with a content-based recommendation system though. To achieve that, we need a platform that's capable of running many models and experiments on large amounts of data in an interactive manner.
Data engineer:
That means storing the data in a format that's easy to consume. We must grab it from wherever it arrives, including external data sources and social media to pick up on trends for seasonal items. That requires ingestion, transformation, cleansing, storage, dealing with dependencies, etc.
ML engineer:
None of that works if you cannot deploy the models automatically while ensuring the quality does not drop. We have to be able to run the deployed and a baseline model in parallel. Moreover, the redeployed model should always be better than the baseline and safe to serve, that is, not crash, behave in unexpected ways, or increase the latency to above our internal SLAs.
Infrastructure engineer:
That sounds like observability across all components: data pipelines, model deployments. Am I missing anything?
ML engineer:
Feedback loops. Suppose our website is experiencing technical issues that increase the latency to the point where individual pages load over several seconds instead of fractions thereof. This causes our customers to abandon the website and look elsewhere. Consequently, we receive less data to determine what they and others are interested in. This in turn means the recommendations deteriorate over time due to a lack of signals. If the recommendations become less relevant, our customers will click on fewer items we suggest, so we get even fewer signals. That will make the model’s recommendations even worse, and so on. In other words, a feedback loop. Worst of all, without proper monitoring and alerting, this is a failure mode that is completely silent.
Infrastructure engineer:
We need to monitor model performance, system performance, and data or model drift.
Data scientist:
For the initial development, we can restrict ourselves to daily batch retraining of the model and not attempt to retrain it dynamically with live data. Daily fresh recommendations should be good enough to begin with. However, the retraining has run automatically and with safety guards: if the data feeding our model is incomplete, late, or even incorrect, we have to alert the team, and delay automatic retraining until upstream issues have been addressed.
Infrastructure engineer:
I see. A deployment is not simply a model behind a REST API. It is really a multi-step workflow of data pipelines, their dependencies, schedules or triggers, the code to train the model, the model once it’s been trained and is ready for serving, the code to decide how and when to deploy, and of course an orchestration layer that makes sure all of that is done automatically and in case of issues knows how to deal with each. Not to mention observability or the ability to scale as our business grows.
ML engineer:
On top of which, we need to track lineage from all inputs and configurations to the output artifacts of the trained model. We need to be able to tell customers why they saw a certain recommendation and to do that reliably we need to ensure we can go back in time in case something went wrong.
Infrastructure engineer:
Would a git-based CI/CD be suitable?
ML engineer:
Sure, but only if we see deployments as entire workflows, not individual steps. In ML, you typically deploy the code that builds, optimizes, and deploys the model itself. In a sense, we deploy the factory, not merely the finished product.
That distinction becomes apparent when you compare it to traditional software development, say, a backend service that deals with the processing of payments. Sudden behavioural changes, as we have seen lately due to Covid-19 or demographic shifts do not affect the payment experience: if we suddenly sold products to cats as well as dogs, the way our customers pay and how we ensure their payments are secured and valid remain the same. The code remains the same, even though the data changes.
The model powering the recommendations could not stay the same: without prior data for cats, the model has no way of bootstrapping itself for the new situation, meaning the original dogs-only baseline would be irrelevant. Deploying a new model (product), perhaps cold-started for cats with some hand-crafted recommendations, would not be sufficient as the entire pipeline (factory) for training, tuning, deploying, and monitoring the model with its data may have to be altered.
Unit and integration tests are pretty standard for data pipelines and microservices. And with metrics or counters you can also ensure that some basic sanity checks are done before storing the derived data sets to deal with the most obvious issues. With sudden shifts in the data distributions, such metrics would have to be analysed and modified though.
Some of the steps in the ML process are harder to test with CI though: model training and tuning are statistical in nature, and of course the data distributions change naturally, even without sudden shifts.
Data scientist:
Just a word of warning: what you suggest is valuable, but if a certain model is performing better than a baseline, it does not automatically imply measurable improvements in KPIs.
ML engineer:
As long as we honour APIs and SLAs we should be able to exchange models without having to go through formal approval processes. That implies we must ensure ready-to-serve models are safe and good enough. We have to do canary deployments, gradual rollouts, and automated A/B tests, by default. If we wanted to run multiple models in parallel, we could opt for a multi-armed bandit instead.
Infrastructure engineer:
I have to insist on a platform that I can operate with ease, that suits our tight security requirements, supports multi-tenancy with access to shared resources, and so on. I'm thinking of container orchestration, because I personally don't care what runs inside the containers, but I do care about my budget and not spending inordinate amounts of time going through dozens of manuals whenever there is an issue. Kubernetes (K8s) is an obvious choice. With cloud-native technologies, we can leverage the latest in scalability and high availability to serve our customers with minimal or no downtime. That should make my boss happy too.
Data and ML engineers:
Sounds good!
Data scientist:
I’ll have to see what tools are available for Kubernetes. The ML ecosystem grew independently of the cloud-native stack, so some of it depends on Jupyter notebooks and virtual environments, other bits run on Hadoop, YARN, or Mesos. Not all of the tools are built for large, distributed workloads, where failure is common and recovery from failure is expected.
The Broken Roomba Methodology and The Frankenweenie Stack
As the team at K9s irons out the details, it’s important to realize the previous discussion is not representative of what happens in most enterprises. The canines were already ahead of many companies in that they knew what they needed. They probably had previous experience building production ML systems.
In reality, monitoring is often an afterthought, as is security, especially when platform or infrastructure engineers are not part of the early discussions. It is also not uncommon for companies to skip the infrastructure altogether, and just begin with a small project that flies under the radar for a bit and naturally evolves into a Frankenstein’s monster of assorted technologies. In sticking with the canine theme, we call this the Frankenweenie stack: any collection of semi-related technologies held together by duct tape and prayers, but mostly the latter.
While an MVP can serve as a valid basis for a future ML platform, few companies take a step back and reevaluate core infrastructure. Technologies keep being tacked on based on short-sighted needs, and that can be hazardous to any hair remaining on your head, especially if you’re on the infrastructure team. This is often the result of the Broken Roomba Methodology.
The Broken Roomba Methodology: a method of software development, often employed implicitly, with unfamiliar technologies, in which bumping into every obstacle is mistaken for progress.
The Broken Roomba Methodology lies at the heart of the model hand-me-downs from data scientists to machine learning engineers, where conversations often go along these lines:
- It works on my machine!
- Why is it taking so long? The model was finished ages ago.
- Well, I’ve been rewriting the finished model for weeks.
As we’ve seen before, some tech companies have successfully built end-to-end machine learning platforms in recent years. They most likely used the broken roomba methodology too, but given sufficient engineering resources, the broken roomba methodology can resemble the agile methodology and lead to success.
It’s just easy to underestimate the difficulty of building a machine learning platform from scratch, thinking that most of the problems are already “solved”, in one way or another, when in reality most of the technology is still rough around the edges and built in isolation from the rest of the stack.
So, how does this all contribute to the extremely high failure rate mentioned earlier?
Many so-called data science platforms focus on model training and tuning, that is pure data science. They leave deployments, where you actually see the return on your ML investments, as an exercise to the reader.
Compare that to the fact that more than 70% of machine learning frameworks do not mention deployments beyond how to save and load models for demonstration purposes. Many of these frameworks evolved out of research and development, so they did not necessarily have production usage in mind. Arguably, it’s not the training frameworks’ duty to tell data scientists how to use the models in production, but with almost 9 out of 10 machine learning initiatives ending up in the corporate dumpster that is unacceptable. Please note that, again, we see evidence of cultural debt and Conway’s law.
In Part II of our story, we will turn to an examination of the best way to get data science models into production, where they can produce real benefits for the enterprise. Stay tuned!

