





USE-CASE
The Need for Fast Data
Build scalable, reliable, and cost-efficient fast data pipelines with DKP.
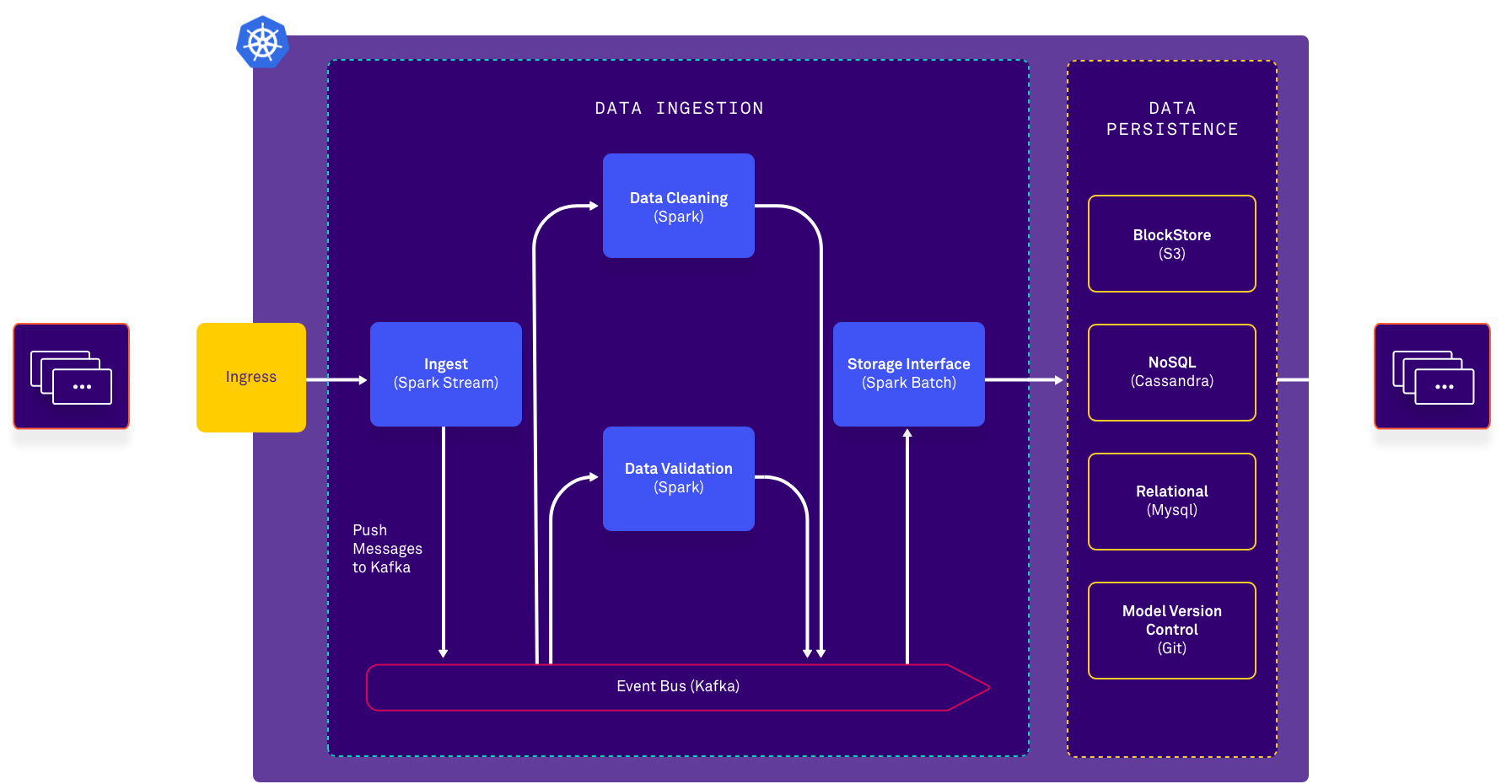
Benefits of using Fast Data Pipelines on Kubernetes
Low Latency
The ways in which data is generated and used today has changed dramatically since Hadoop and batch processing. These processes would take hours or even days to get results, which is not optimal for the type of workloads or use cases organizations want to leverage in today's environments. Fast data pipelines help remove latency from the data collection and transport process so that organizations can make smarter decisions faster to improve the customer experience.
Manage Large Volumes of Data
The volume of data and data sources are growing every day. In fact, International Data Corporation (IDC) estimates that 175 zettabytes (a zettabyte is a trillion gigabytes) of data will be created annually, through 2025. Fast data pipelines enable organizations to collect, move, and store very large volumes of data that can be used for big data analysis to provide actionable insights.
Lower Costs
As the volume of generated data increases, so does the need for extracting value from it in real-time. However, the process of collecting, transporting, storing, and processing data can easily overwhelm a company's IT budget. Fast data pipelines constructed using open-source technologies can significantly cut costs, especially when combined with Kubernetes' ability to scale up and down resource utilization in response to demand.
Challenges of using Fast Data Pipelines on Kubernetes
Building a Data Pipeline Requires Time and Expertise
Organizations need the digital agility that only a fast data pipeline on Kubernetes can provide. However, setting up a production-ready environment includes a wide variety of open-source technologies that are very labor intensive to get up and running. Not only that, but operators must take into account the specific requirements and needs of each data service that comprise a fast data pipeline, making it difficult to build a robust data pipeline to support mission-critical workloads.

Operating Fast Data Pipelines is Manual and Error-Prone
In today's data-centric economy, managing your data pipeline throughout its lifecycle is more important than ever. However, managing all of the data sources and the large-scale processes that come with it is incredibly complex. Ongoing maintenance includes a number of tasks, such as upgrading software, deploying updates, and more, that are often manual and time-consuming. Without a way to automate many of the manual tasks, it can lead to an increase in overhead, operating costs, and opportunity costs.
Lack of Centralized Visibility and Standardization
When many different people in the organization are working with data independently and in different ways, it inevitably leads to a lack of standardization. And when there is no single point of control to track where the data comes from, where it moves to, or where it ends up, managing the sprawling web of data sources and the large-scale processes that come with them is hard. This becomes more difficult to manage as the number of data sources and integrations grow and team members multiply.


Unable to Unify Access Across Different Infrastructures
Organizations require a flexible solution that aligns with upstream, open-source Kubernetes so they can integrate with key data services across the ecosystem and deploy anywhere. Being able to unify your fast data pipeline on a single platform gives you the ability to access data services and high value workloads with Day 2 consistency, regardless of cloud provider.
How DKP Enables Simple Provisioning and Deployment of Fast Data Pipelines
Build Production-Ready Fast Data Pipelines with Ease
Enable Fast and Easy Deployment of Key Data Services
Rather than having to piece together a solution, D2iQ does the difficult work for you by selecting all of the key data services from the CNCF landscape, integrating them with the Kommander Catalog, automating their installation, and testing them to ensure they all work together for quick and easy deployment into Kubernetes clusters. Organizations can benefit from faster time to value, reduced overhead, and the robust Day 2 readiness features that Kommander provides, including security, observability, RBAC, and more.

Ensure Lifecycle Management of Key Data Services
Replace Manual Operational Effort With Operators
DKP automates many of the manual tasks required to maintain fast data pipelines through operators, or embedded run-books, that are provided and validated by D2iQ. Anytime you need to make a change to an application, upgrade software, deploy updates, and more, operators tell you the order in which you need to do things to successfully make a change to a complex system. By replacing human effort with code, you'll have peace of mind in the lifecycle management of these key data services.
Unify Disparate Data Sources From a Single Point of Control
Provide Centralized Visibility Across the the Kubernetes Landscape
DKP's federated management plane provides centralized visibility and monitoring of any CNCF-compliant Kubernetes cluster or distribution from a single, central point of control. This simplified bird's eye view helps organizations better understand where their data comes from, where it moves to, and where it ends up. As a result, you and your team can manage fast data pipelines with consistency and reliability, without interfering with the day-to-day business functions and requirements that different clusters support.

Minimize the Costs of Transporting Data
Run Kubernetes on any Infrastructure
DKP is infrastructure agnostic, meaning that software developed on one type of infrastructure will work the same wherever it is run. The ability to run Kubernetes on many different infrastructures makes it easier to bring compute resources closer to the data. It also allows the use of existing on-premise infrastructure in place of public cloud resources that can quickly become expensive. This versitability reduces overall costs and increases ROI for on-premise IT infrastructure.
Luc Van Maldeghem
General Manager, MYCSN
Key Features and Benefits
Operational Dashboard
Provide instant visibility and operational efficiency into the Kubernetes landscape from a single, centralized point of control.
Centralized Observability
Provide enhanced visibility and control at an enterprise level with comprehensive logging and monitoring across all clusters.
Declarative Automated Installer
Accelerate time-to-production on any infrastructure with a highly automated installation process that includes all of the fast data components needed for production.
Lifecycle Automation
Make changes to an application, upgrade software, deploy updates, scale out, scale in, roll back after failures, and more, through Operators that are provided and validated by D2iQ.
Service Catalog
Quickly and easily deploy complex data services from the Kommander platform application catalog to specific or multiple clusters, with governance.
Governance Policy Administration
Meet the requirements of security and audit teams with centralized cluster policy management.
Centralized Authorization and Authentication
Enable single sign-on (SSO) across an organization's cluster footprint and govern authorization with RBAC and Open Policy Access to enhance security and reduce risk.




Thank you. Check your email for details on your request.